Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Casi ElastiCache d'uso comuni e come ElastiCache può essere utile
Che si tratti di fornire le ultime notizie del giorno, una classifica dei primi 10 punteggi di gioco, un catalogo di prodotti o che si tratti di vendere biglietti per un evento, la velocità è alla base di ogni operazione. Il successo del tuo sito web e del tuo business è influenzato significativamente dalla velocità con cui si distribuiscono i contenuti.
Nel documento «For Impatient Web Users, an Eye Blink Is Just Too Long to Wait
Se qualcuno desidera dei dati, è possibile fornirli in modo molto più veloce se sono memorizzati nella cache. Che si tratti di una pagina web o di un report alla base di decisioni aziendali. La tua azienda può permettersi di non memorizzare in cache le pagine web in modo da distribuirle con la minore latenza possibile?
Intuitivamente, potrebbe essere piuttosto scontato pensare di memorizzare in cache gli elementi richiesti con maggiore frequenza. Invece, perché non memorizzare in cache gli elementi richiesti con minore frequenza? Anche le chiamate API remote o le query di database meglio ottimizzate sono notevolmente più lente rispetto a quando si richiama una chiave flat da una cache in memoria. I tempi notevolmente più lenti spingono i clienti ad andare altrove.
I seguenti esempi illustrano alcuni dei modi in cui l'utilizzo ElastiCache può migliorare le prestazioni complessive dell'applicazione.
Argomenti
In-Memory Archivio dati
Lo scopo principale di uno store chiave-valore in memoria è fornire accesso ultrarapido (latenza in millisecondi) e a costo zero alle copie di dati. La maggior parte dei datastore hanno aree di dati a cui si accede di frequente ma che vengono aggiornate raramente. Inoltre, l'interrogazione di un database è sempre più lenta e più costosa dell'individuazione di una chiave in una cache della coppia chiave-valore. Alcune query di database sono particolarmente costose da eseguire. Ad esempio, le query che implicano unioni di più tabelle o le query con calcoli complessi. Memorizzando nella cache tali risultati delle query, si paga il prezzo della query una sola volta. Quindi è possibile richiamare velocemente i dati più volte senza dover rieseguire la query.
Cosa devo memorizzare nella cache?
Quando si decide quali dati memorizzare nella cache, tenere presenti i seguenti fattori:
Velocità e spese – È sempre più lento e costoso ottenere dati da un database che da una cache. Alcune query del database sono per natura più lente e più costose di altre. Ad esempio, le query che eseguono unioni su più tabelle sono molto più lente e più costose delle semplici query a tabella unica. Se l'acquisizione di dati interessanti richiede una query più lenta e più costosa, è indicata per il caching. Se l'acquisizione di dati richiede una query semplice e relativamente rapida, può essere idonea per il caching ma è necessario valutare altri fattori.
Dati e modello di accesso— Determinare cosa memorizzare nella cache comporta anche la comprensione dei dati stessi e dei relativi modelli di accesso. Ad esempio, non ha senso memorizzare nella cache i dati sottoposti a continue modifiche o a cui si accede raramente. Affinché la memorizzazione nella cache fornisca vantaggi reali, i dati devono essere relativamente statici e l'accesso a essi deve essere frequente. Un esempio è un profilo personale su un sito di social media. D’altra parte, non è necessario memorizzare nella cache se questa operazione non fornisce vantaggi economici e non migliora la velocità. Ad esempio, non ha senso memorizzare in cache le pagine web che restituiscono risultati di ricerca, perché le query e i risultati sono di solito univoci.
Obsolescenza – Per definizione, i dati memorizzati nella cache sono dati obsoleti. Anche se in determinate circostanze non sono obsoleti, dovrebbero sempre essere considerati e trattati come obsoleti. Per dire se i dati siano candidati al caching, devi stabilire la tolleranza dell'applicazione per i dati obsoleti.
L'applicazione potrebbe essere in grado di tollerare i dati obsoleti in un dato contesto, ma non in un altro. Supponi, ad esempio, che il sito fornisca un prezzo delle azioni quotato in borsa. I clienti potrebbero accettare una certa obsolescenza con una dichiarazione di non responsabilità secondo la quale i prezzi potrebbero essere n minuti in ritardo. Tuttavia, quando si offre il prezzo per lo stesso stock a un broker che effettua una vendita o un acquisto, sono necessari i dati in tempo reale.
Prendi in considerazione di memorizzare nella cache i dati in presenza di una delle seguenti condizioni:
L'acquisizione dei dati è lenta o costosa se confrontata con il recupero dalla cache.
Gli utenti accedono spesso ai dati.
I dati rimangono relativamente gli stessi, o se cambiano rapidamente l’obsolescenza non è un grosso problema.
Per ulteriori informazioni, consulta Strategie di caching per Memcached
Classifiche di gioco
Con i set ordinati Valkey o Redis OSS puoi spostare la complessità computazionale delle classifici dall'applicazione al cluster.
Le classifiche, ad esempio i primi 10 punteggi di una partita, sono complessi da un punto di vista computazionale. Ciò è particolarmente vero quando c'è un gran numero di giocatori concorrenti e punteggi che cambiano continuamente. I set ordinati Valkey e Redis OSS garantiscono sia l'unicità che l'ordine degli elementi. Con i set ordinati, ogni volta che un nuovo elemento viene aggiunto al set ordinato, questo viene riclassificato in tempo reale. Viene quindi aggiunto al set nel corretto ordine numerico.
Nel diagramma seguente, puoi vedere come funziona una classifica di gioco. ElastiCache
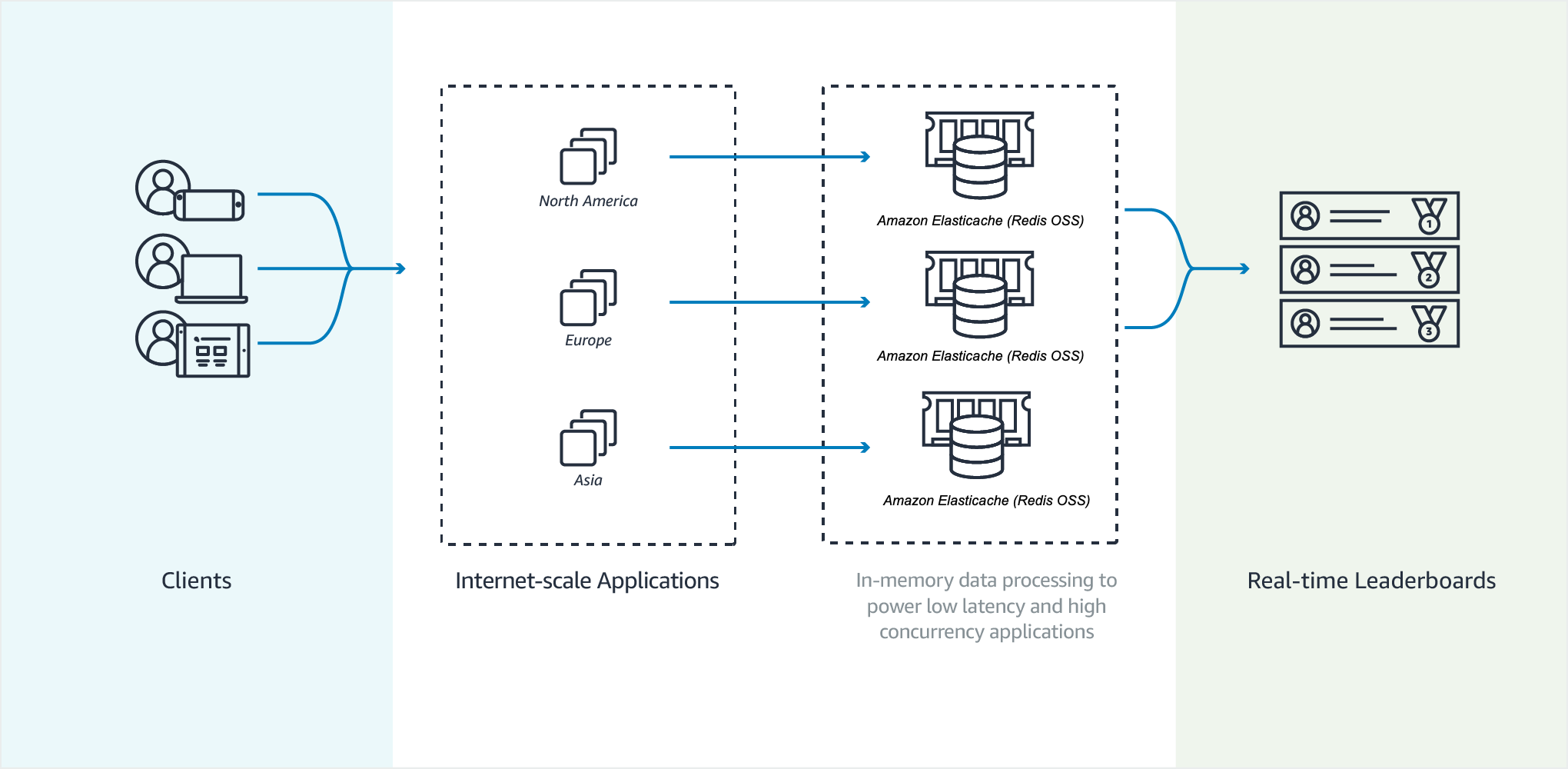
Esempio Classificazione OSS Valkey o Redis
In questo esempio, quattro giocatori e i relativi punteggi vengono inseriti in un elenco ordinato tramite ZADD. Il comando ZREVRANGEBYSCORE elenca i giocatori in base al punteggio, dal più alto al più basso. Quindi, ZADD viene utilizzato per aggiornare il punteggio di June sostituendo la voce esistente. Infine ZREVRANGEBYSCORE elenca i giocatori in base al punteggio, dal più alto al più basso. L’elenco mostra che June è salita di posizione nella classifica.
ZADD leaderboard 132 Robert ZADD leaderboard 231 Sandra ZADD leaderboard 32 June ZADD leaderboard 381 Adam ZREVRANGEBYSCORE leaderboard +inf -inf 1) Adam 2) Sandra 3) Robert 4) June ZADD leaderboard 232 June ZREVRANGEBYSCORE leaderboard +inf -inf 1) Adam 2) June 3) Sandra 4) Robert
Il comando seguente comunica a June qual è il suo posto nella classifica di tutti i giocatori. Poiché la classifica è basata su zero, ZREVRANK restituisce un 1 per June, che si trova in seconda posizione.
ZREVRANK leaderboard June 1
Per ulteriori informazioni, consulta la documentazione di Valkey
Messaggi () Pub/Sub
Quando invii un messaggio e-mail, lo invii a uno o più destinatari specificati. Nel pub/sub paradigma Valkey e Redis OSS, si invia un messaggio a un canale specifico senza sapere chi, se qualcuno, lo riceve. Le persone che ricevono il messaggio sono quelle che hanno effettuato la sottoscrizione al canale. Ad esempio, supponiamo che tu voglia effettuare la sottoscrizione al canale news.sports.golf: Tu e tutti gli iscritti al canale news.sports.golf ricevono tutti i messaggi pubblicati su news.sports.golf.
Pub/sub la funzionalità non ha alcuna relazione con nessuno spazio chiave. Perciò, non interferisce a nessun livello. Nel diagramma seguente, è possibile trovare un'illustrazione della ElastiCache messaggistica con Valkey e Redis OSS.
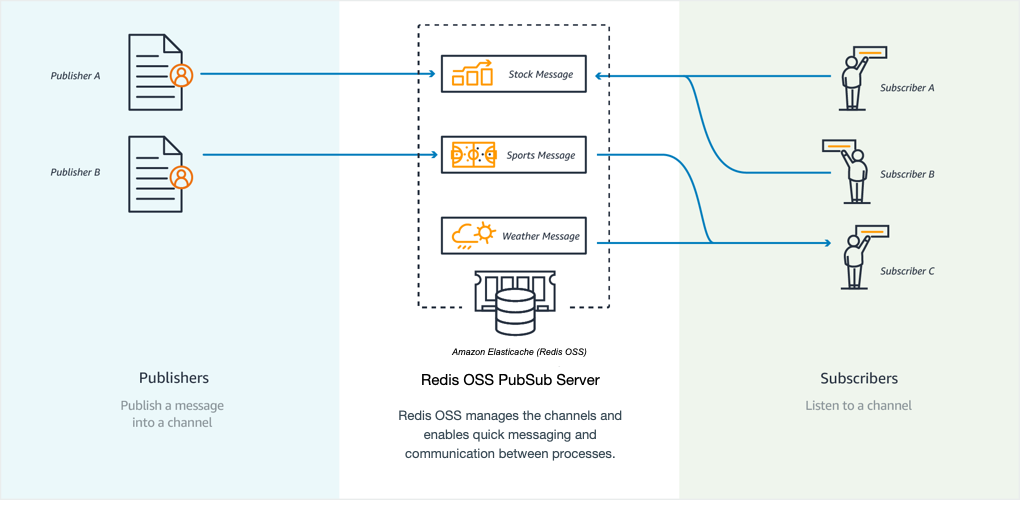
Sottoscrizione in corso
Per ricevere messaggi su un canale, effettua la sottoscrizione al canale. Puoi effettuare la sottoscrizione al canale, a più canali specificati o a tutti i canali che corrispondono a un modello. Per annullare una sottoscrizione, annulli la sottoscrizione dal canale specificato al momento dell’iscrizione. In alternativa, se la sottoscrizione è stata effettuata utilizzando la corrispondenza dei modelli, la si annulla utilizzando lo stesso modello utilizzato in precedenza.
Esempio– Effettuare una sottoscrizione a un singolo canale
Per effettuare una sottoscrizione a un singolo canale, utilizza il comando UNSUBSCRIBE specificando il canale a cui hai effettuato la sottoscrizione. Nell'esempio seguente, un cliente effettua la sottoscrizione al canale news.sports.golf.
SUBSCRIBE news.sports.golf
Trascorso un certo periodo, il cliente annulla la sottoscrizione al canale utilizzando il comando UNSUBSCRIBE specificando il canale dal quale annullare la sottoscrizione.
UNSUBSCRIBE news.sports.golf
Esempio– Sottoscrizioni a più canali specificati
Per annullare una sottoscrizione a più canali specificati, elenca i canali con il comando SUBSCRIBE. Nell'esempio seguente, un cliente effettua la sottoscrizione ai canali news.sports.golf, news.sports.soccer e news.sports.skiing.
SUBSCRIBE news.sports.golf news.sports.soccer news.sports.skiing
Per annullare la sottoscrizione a un canale specificato, utilizza il comando UNSUBSCRIBE specificando il canale dal quale annullare la sottoscrizione.
UNSUBSCRIBE news.sports.golf
Per annullare una sottoscrizione a più canali, utilizza il comando UNSUBSCRIBE e specifica i canali dai quali annullare la sottoscrizione.
UNSUBSCRIBE news.sports.golf news.sports.soccer
Per annullare tutte le sottoscrizioni, usa UNSUBSCRIBE e specifica ogni canale. Oppure usa UNSUBSCRIBE e non specificare un canale.
UNSUBSCRIBE news.sports.golf news.sports.soccer news.sports.skiing
or
UNSUBSCRIBE
Esempio– Sottoscrizioni mediante la corrispondenza di modelli
I clienti possono effettuare la sottoscrizione a tutti i canali corrispondenti a un modello mediante il comando PSUBSCRIBE.
Nell'esempio seguente, un cliente effettua la sottoscrizione a tutti i canali sportivi. Non elenchi tutti i canali sportivi singolarmente, come si farebbe con SUBSCRIBE. Invece, con il comando PSUBSCRIBE si utilizza la corrispondenza del modello.
PSUBSCRIBE news.sports.*
Esempio Annullamento delle sottoscrizioni
Per annullare le sottoscrizioni a questi canali, utilizza il comando PUNSUBSCRIBE.
PUNSUBSCRIBE news.sports.*
Importante
Le stringhe del canale inviate ai comandi [P]SUBSCRIBE e [P]UNSUBSCRIBE devono corrispondere. Non è possibile
PSUBSCRIBEa news.* ePUNSUBSCRIBEda news.sports.* oUNSUBSCRIBEda news.sports.golf.PSUBSCRIBEe nonPUNSUBSCRIBEsono disponibili per ElastiCache Serverless.
Pubblicazione
Per inviare un messaggio a tutti coloro che hanno effettuato la sottoscrizione a un canale, utilizza il comando PUBLISH specificando il canale e il messaggio. L'esempio seguente pubblica il messaggio "It’s Saturday and sunny (è sabato e fa bel tempo. I'm headed to the links. (Vado ai link)”. sul canale news.sports.golf.
PUBLISH news.sports.golf "It's Saturday and sunny. I'm headed to the links."
Un client non può pubblicare su un canale a cui è abbonato.
Per ulteriori informazioni, consulta la Pub/Sub
Dati di raccomandazione (hash)
L'utilizzo di INCR o DECR in Valkey o Redis OSS semplifica la compilazione dei consigli. Ogni volta che un utente mette «Mi piace» a un prodotto, incrementi un contatore articolo:prodotto. ID:like Ogni volta che a un utente «non piace» un prodotto, incrementi un contatore articolo:prodotto. ID:dislike Utilizzando gli hash, puoi anche mantenere un elenco di tutti coloro a cui è piaciuto o non è piaciuto un prodotto.
Esempio- "Mi piace" e "Non mi piace"
INCR item:38923:likes HSET item:38923:ratings Susan 1 INCR item:38923:dislikes HSET item:38923:ratings Tommy -1
Caching semantico per applicazioni di intelligenza artificiale generativa
La gestione di applicazioni di intelligenza artificiale generativa su larga scala può essere difficile a causa del costo e della latenza associati alle chiamate di inferenza verso modelli linguistici di grandi dimensioni (LLM). È possibile utilizzarle ElastiCache per la memorizzazione nella cache semantica nelle applicazioni di intelligenza artificiale generativa, che consente di ridurre il costo e la latenza delle chiamate di inferenza LLM. Con la memorizzazione nella cache semantica, è possibile restituire una risposta memorizzata nella cache utilizzando la corrispondenza vettoriale per trovare somiglianze tra i prompt correnti e quelli precedenti. Se il prompt di un utente è semanticamente simile a un prompt precedente, verrà restituita una risposta memorizzata nella cache anziché effettuare una nuova chiamata di inferenza LLM, riducendo il costo delle applicazioni di intelligenza artificiale generativa e fornendo risposte più rapide che migliorano l'esperienza dell'utente. Puoi controllare quali query vengono indirizzate alla cache configurando soglie di somiglianza per i prompt e applicando tag o filtri di metadati numerici.
Gli aggiornamenti in linea degli indici in tempo reale forniti da vector search for ElastiCache aiutano a garantire che la cache si aggiorni continuamente man mano che arrivano le richieste degli utenti e le risposte LLM. Questa indicizzazione in tempo reale è fondamentale per mantenere aggiornati i risultati memorizzati nella cache e le percentuali di accesso alla cache, in particolare in caso di traffico con picchi di traffico. Inoltre, ElastiCache semplifica le operazioni di caching semantico attraverso primitive di cache mature come TTL per chiave, strategie di sfratto configurabili, operazioni atomiche e una ricca struttura di dati e supporto per lo scripting.
Memoria per assistenti e agenti di intelligenza artificiale generativa
È possibile utilizzarla ElastiCache per fornire risposte più personalizzate e sensibili al contesto implementando meccanismi di memoria che restituiscono agli LLM la cronologia delle conversazioni tra sessioni. La memoria conversazionale consente agli assistenti e agli agenti di intelligenza artificiale generativa di conservare e utilizzare le interazioni passate per personalizzare le risposte e migliorare la pertinenza. Tuttavia, la semplice aggregazione di tutte le interazioni precedenti nel prompt è inefficace poiché i token aggiuntivi irrilevanti aumentano i costi, degradano la qualità della risposta e rischiano di superare la finestra contestuale del LLM. È invece possibile utilizzare la ricerca vettoriale per recuperare e fornire solo i dati più rilevanti nel contesto per ogni chiamata LLM.
ElastiCache for Valkey fornisce integrazioni con livelli di memoria open source, fornendo connettori integrati per archiviare e recuperare memorie per applicazioni e agenti LLM. La ricerca vettoriale ElastiCache fornisce aggiornamenti rapidi dell'indice, mantiene la memoria aggiornata e rende immediatamente ricercabili nuovi ricordi. La ricerca vettoriale a bassa latenza velocizza le ricerche nella memoria, consentendone l'implementazione nel percorso online di ogni richiesta, non solo nelle attività in background. Oltre alla ricerca vettoriale, ElastiCache for Valkey fornisce anche primitive di memorizzazione nella cache per lo stato della sessione, le preferenze dell'utente e i flag delle funzionalità, fornendo un unico servizio per archiviare lo stato della sessione di breve durata e le «memorie» a lungo termine in un unico datastore.
Generazione aumentata di recupero (RAG)
RAG è il processo che fornisce ai LLM informazioni aggiornate al fine di migliorare la pertinenza delle risposte. RAG riduce le allucinazioni e migliora l'accuratezza dei fatti basando i risultati su fonti di dati reali. Le applicazioni RAG utilizzano la ricerca vettoriale per recuperare contenuti semanticamente rilevanti da una knowledge base. La ricerca vettoriale a bassa latenza fornita da la ElastiCache rende adatta all'implementazione di RAG in carichi di lavoro con set di dati di grandi dimensioni con milioni di vettori e oltre. Inoltre, il supporto per gli aggiornamenti degli indici vettoriali online lo rende ElastiCache adatto agli assistenti con flussi di lavoro di caricamento che devono garantire che i dati caricati siano immediatamente ricercabili. RAG nei sistemi di intelligenza artificiale agentic garantisce che gli agenti dispongano di informazioni aggiornate per azioni accurate. La ricerca vettoriale a bassa latenza è fondamentale anche per RAG nei sistemi di intelligenza artificiale agentica, in cui una singola query può attivare più chiamate LLM e aumentare la latenza della ricerca vettoriale sottostante.
Il diagramma seguente illustra un esempio di architettura utilizzato ElastiCache per implementare una cache semantica, meccanismi di memoria e RAG per migliorare un'applicazione AI generativa in produzione.

Ricerca semantica
La ricerca vettoriale recupera i dati di testo, parlato, immagine o video più pertinenti in base alla vicinanza nel significato o nelle caratteristiche. Questa funzionalità consente applicazioni di machine learning che si basano sulla ricerca di similarità tra diverse modalità di dati, inclusi motori di raccomandazione, rilevamento delle anomalie, personalizzazione e sistemi di gestione della conoscenza. I sistemi di raccomandazione utilizzano rappresentazioni vettoriali per acquisire modelli complessi nel comportamento degli utenti e nelle caratteristiche degli elementi, consentendo loro di suggerire i contenuti più pertinenti. Vector search for ElastiCache è ideale per queste applicazioni grazie agli aggiornamenti quasi in tempo reale e alla bassa latenza, che consentono confronti di similarità che forniscono consigli istantanei e altamente pertinenti basati sulle interazioni degli utenti in tempo reale.
ElastiCache Testimonianze dei clienti
Per scoprire in che modo aziende come Airbnb, PBS, Esri e altre utilizzano Amazon ElastiCache per far crescere le proprie attività con una migliore esperienza cliente, consulta Come gli altri utilizzano Amazon
Puoi anche guardare i video del tutorial per altri casi d'uso da ElastiCache parte dei clienti.
