Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Best practice per ottimizzare le prestazioni di S3 Express One Zone
Durante la creazione di applicazioni che caricano e recuperano oggetti da Amazon S3 Express One Zone, segui le nostre linee guida sulle best practice per ottimizzare le prestazioni. Per utilizzare la classe di archiviazione S3 Express One Zone, devi creare una directory di bucket S3. La classe di archiviazione S3 Express One Zone non è supportata per l'utilizzo con bucket per uso generico S3.
Per le linee guida sulle prestazioni per tutte le altre classi di archiviazione Amazon S3 e i bucket per uso generico S3, consulta Best practice e modelli di progettazione: ottimizzazione delle prestazioni di Amazon S3.
Per prestazioni e scalabilità ottimali con la classe di archiviazione S3 Express One Zone e i bucket di directory in carichi di lavoro su larga scala, è importante capire in che modo i bucket di directory sono diversi dai bucket generici. Pertanto, di seguito sono fornite le best practice per allineare le applicazioni al modo in cui funzionano i bucket di directory.
Come funzionano i bucket di directory
La classe di archiviazione Amazon S3 Express One Zone può supportare carichi di lavoro con un massimo di 2.000.000 transazioni GET e fino a 200.000 transazioni PUT al secondo (TPS) per ogni bucket di directory. Con S3 Express One Zone, i dati sono archiviati in bucket di directory S3 situati nelle zone di disponibilità. Gli oggetti nei bucket di directory sono accessibili all’interno di un namespace gerarchico, simile a un file system, a differenza dei bucket per uso generico S3 che hanno un namespace semplice. A differenza dei bucket per uso generico, i bucket di directory organizzano le chiavi in maniera gerarchica in directory anziché prefissi. Un prefisso è una stringa di caratteri all’inizio del nome della chiave dell’oggetto. È possibile utilizzare i prefissi per organizzare i dati e gestire un’architettura di archiviazione degli oggetti semplice in bucket per uso generico. Per ulteriori informazioni, consulta Organizzazione degli oggetti utilizzando i prefissi.
Nei bucket di directory, gli oggetti sono organizzati in un namespace gerarchico utilizzando la barra (/) come unico delimitatore supportato. Quando carichi un oggetto con una chiave come dir1/dir2/file1.txt, le directory dir1/ e dir2/ vengono create e gestite automaticamente da Amazon S3. Le directory vengono create durante le operazioni PutObject o CreateMultiPartUpload e rimosse automaticamente quando sono vuote dopo le operazioni DeleteObject o AbortMultiPartUpload. Non esiste alcun limite massimo al numero di oggetti e sottodirectory presenti in una directory.
Le directory create quando gli oggetti vengono caricati nei bucket di directory possono scalare istantaneamente per ridurre la possibilità di errori HTTP 503 (Slow Down). Questo dimensionamento automatico consente alle applicazioni di parallelizzare le richieste di lettura e scrittura all'interno e tra le directory in base alle esigenze. Per S3 Express One Zone, le singole directory sono progettate per supportare la frequenza massima di richieste di un bucket di directory. Non è necessario applicare la randomizzazione dei prefissi delle chiavi per ottenere prestazioni ottimali perché il sistema distribuisce automaticamente gli oggetti con una distribuzione uniforme del carico, ma di conseguenza, le chiavi non vengono archiviate in base all’ordine lessicografico nei bucket di directory. Questo comportamento è in contrasto con i bucket per uso generico S3, in cui è più probabile che le chiavi simili dal punto di vista lessicografico siano collocate sullo stesso server.
Per ulteriori informazioni sugli esempi di operazioni di bucket di directory e interazioni tra directory, consulta Esempi di funzionamento del bucket di directory e di interazione con le directory.
Best practice
Segui le best practice per ottimizzare le prestazioni del bucket di directory e consentire ai carichi di lavoro di scalare nel tempo.
Utilizzare directory contenenti molte voci (oggetti o sottodirectory)
I bucket di directory offrono prestazioni elevate per impostazione predefinita per tutti i carichi di lavoro. Per un’ottimizzazione ancora maggiore delle prestazioni con determinate operazioni, il consolidamento di più voci (ossia oggetti o sottodirectory) nelle directory comporta una latenza inferiore e una frequenza di richieste più elevata:
Le operazioni API mutanti, come
PutObject,DeleteObject,CreateMultiPartUploadeAbortMultiPartUpload, ottengono prestazioni ottimali se implementate con un numero contenuto di directory più dense con migliaia di voci, anziché con un numero elevato di directory più piccole.Le operazioni
ListObjectsV2funzionano meglio quando si devono attraversare meno directory per popolare una pagina di risultati.
Non utilizzare l’entropia nei prefissi
Nelle operazioni di Amazon S3, l’entropia si riferisce alla randomizzazione nella denominazione dei prefissi che aiuta a distribuire i carichi di lavoro in modo uniforme tra le partizioni di archiviazione. Tuttavia, poiché i bucket di directory gestiscono internamente la distribuzione del carico, non è consigliabile utilizzare l’entropia nei prefissi per migliorare le prestazioni. Questo perché per i bucket di directory, l’entropia può rallentare le richieste non riutilizzando le directory che sono già state create.
Un modello di chiave come $HASH/directory/object potrebbe finire per creare molte directory intermedie. Nel seguente esempio, tutti i job-1 sono directory diverse perché gli elementi principali sono diversi. Le directory saranno piccole e le richieste di mutazione e di elenco saranno più lente. In questo esempio ci sono 12 directory intermedie che hanno tutte una singola voce.
s3://my-bucket/0cc175b9c0f1b6a831c399e269772661/job-1/file1 s3://my-bucket/92eb5ffee6ae2fec3ad71c777531578f/job-1/file2 s3://my-bucket/4a8a08f09d37b73795649038408b5f33/job-1/file3 s3://my-bucket/8277e0910d750195b448797616e091ad/job-1/file4 s3://my-bucket/e1671797c52e15f763380b45e841ec32/job-1/file5 s3://my-bucket/8fa14cdd754f91cc6554c9e71929cce7/job-1/file6
Per ottenere prestazioni ottimali, è possibile rimuovere il componente $HASH e consentire a job-1 di diventare una singola directory, migliorando la densità della directory. Nell’esempio seguente, la singola directory intermedia con sei voci può ottenere prestazioni migliori rispetto all’esempio precedente.
s3://my-bucket/job-1/file1 s3://my-bucket/job-1/file2 s3://my-bucket/job-1/file3 s3://my-bucket/job-1/file4 s3://my-bucket/job-1/file5 s3://my-bucket/job-1/file6
Questo vantaggio in termini di prestazioni si verifica perché quando una chiave dell’oggetto viene inizialmente creata e il relativo nome della chiave include una directory, la directory viene creata automaticamente per l’oggetto. I successivi caricamenti di oggetti nella stessa directory non richiedono la creazione della directory, riducendo pertanto la latenza su caricamenti di oggetti nelle directory esistenti.
Usa un separatore diverso dal delimitatore/per separare le parti della chiave se non hai bisogno della possibilità di raggruppare logicamente gli oggetti durante le chiamate V2 ListObjects
Poiché il delimitatore / è trattato in modo speciale per i bucket di directory, deve essere utilizzato intenzionalmente. Sebbene i bucket di directory non dispongano gli oggetti in base all’ordine lessicografico, gli oggetti all’interno di una directory sono comunque raggruppati in output ListObjectsV2. Se non è necessaria questa funzionalità, puoi sostituire / con un altro carattere come separatore per evitare la creazione di directory intermedie.
Ad esempio, supponi che le seguenti chiavi siano nel modello di prefisso YYYY/MM/DD/HH/
s3://my-bucket/2024/04/00/01/file1 s3://my-bucket/2024/04/00/02/file2 s3://my-bucket/2024/04/00/03/file3 s3://my-bucket/2024/04/01/01/file4 s3://my-bucket/2024/04/01/02/file5 s3://my-bucket/2024/04/01/03/file6
Se non è necessario raggruppare gli oggetti in base all’ora o al giorno nei risultati di ListObjectsV2, ma è necessario raggruppare gli oggetti in base al mese, il seguente modello di chiave YYYY/MM/DD-HH- consente di ridurre notevolmente il numero di directory e di migliorare le prestazioni dell’operazione ListObjectsV2.
s3://my-bucket/2024/04/00-01-file1 s3://my-bucket/2024/04/00-01-file2 s3://my-bucket/2024/04/00-01-file3 s3://my-bucket/2024/04/01-02-file4 s3://my-bucket/2024/04/01-02-file5 s3://my-bucket/2024/04/01-02-file6
Utilizzare operazioni con elenchi delimitati se possibile
Una richiesta ListObjectsV2 senza delimiter esegue l’attraversamento ricorsivo depth-first di tutte le directory. Una richiesta ListObjectsV2 con delimiter recupera solo le voci nella directory specificata dal parametro prefix, riducendo la latenza della richiesta e aumentando le chiavi aggregate al secondo. Per i bucket di directory, utilizza operazioni con elenchi delimitati, ove possibile. Gli elenchi delimitati fanno sì che le directory vengano visitate meno volte, il che comporta più chiavi al secondo e una minore latenza delle richieste.
Ad esempio, considera le directory e gli oggetti seguenti presenti nel bucket di directory:
s3://my-bucket/2024/04/12-01-file1 s3://my-bucket/2024/04/12-01-file2 ... s3://my-bucket/2024/05/12-01-file1 s3://my-bucket/2024/05/12-01-file2 ... s3://my-bucket/2024/06/12-01-file1 s3://my-bucket/2024/06/12-01-file2 ... s3://my-bucket/2024/07/12-01-file1 s3://my-bucket/2024/07/12-01-file2 ...
Per migliorare le prestazioni di ListObjectsV2, utilizza un elenco delimitato per elencare le sottodirectory e gli oggetti, se la logica dell’applicazione lo consente. Ad esempio, puoi eseguire il comando seguente per l’operazione con elenco delimitato:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/' --delimiter '/'
L’output è l’elenco delle sottodirectory.
{ "CommonPrefixes": [ { "Prefix": "2024/04/" }, { "Prefix": "2024/05/" }, { "Prefix": "2024/06/" }, { "Prefix": "2024/07/" } ] }
Per elencare ogni sottodirectory con le prestazioni migliori, puoi eseguire un comando simile all’esempio seguente.
Comando:
aws s3api list-objects-v2 --bucket my-bucket --prefix '2024/04' --delimiter '/'
Output:
{ "Contents": [ { "Key": "2024/04/12-01-file1" }, { "Key": "2024/04/12-01-file2" } ] }
Co-locate Storage S3 Express One Zone con le tue risorse di elaborazione
Con S3 Express One Zone, ogni bucket di directory si trova in una singola zona di disponibilità che selezioni quando crei il bucket. Puoi iniziare creando un nuovo bucket di directory in una zona di disponibilità locale nei carichi di lavoro o nelle risorse di calcolo. Quindi, puoi iniziare immediatamente letture e scritture a latenza molto bassa. I bucket di directory sono un tipo di bucket S3 in cui puoi scegliere la zona di disponibilità in modo da ridurre la latenza tra Regione AWS elaborazione e archiviazione.
Se accedi ai bucket di directory tra zone di disponibilità, è possibile che si verifichi un leggero aumento della latenza. Per ottimizzare le prestazioni, ti consigliamo di accedere a un bucket di directory dalle istanze di Amazon Elastic Container Service, Amazon Elastic Kubernetes Service e Amazon Elastic Compute Cloud che si trovano nella stessa zona di disponibilità, se possibile.
Utilizzare connessioni simultanee per ottenere un throughput elevato con oggetti superiori a 1 MB
Puoi ottenere prestazioni ottimali inviando più richieste simultanee ai bucket di directory per distribuire le richieste su connessioni separate per massimizzare la larghezza di banda accessibile. Come per i bucket per uso generico, S3 Express One Zone non impone limiti al numero di connessioni effettuate al bucket di directory. Le singole directory possono dimensionare le prestazioni orizzontalmente e automaticamente quando si verifica un numero elevato di scritture simultanee nella stessa directory.
Le singole connessioni TCP ai bucket di directory hanno un limite massimo fisso per il numero di byte che possono essere caricati o scaricati al secondo. Quando gli oggetti diventano più grandi, i tempi di richiesta vengono dominati dallo streaming di byte anziché dall’elaborazione della transazione. Per utilizzare più connessioni per parallelizzare il caricamento o il download di oggetti di grandi dimensioni, puoi ridurre la latenza end-to-end. Se utilizzi Java 2.x SDK, dovrai prendere in considerazione l’utilizzo di S3 Transfer Manager, che sfrutta i miglioramenti delle prestazioni come le operazioni API di caricamento in più parti e il recupero di intervalli di byte per accedere ai dati in parallelo.
Utilizzare gli endpoint VPC del gateway
Gli endpoint del gateway forniscono la connessione diretta dal VPC ai bucket di directory, senza richiedere un gateway Internet o un dispositivo NAT per il VPC. Per ridurre il tempo che i pacchetti trascorrono sulla rete, è necessario configurare il VPC con un endpoint VPC del gateway per i bucket di directory. Per ulteriori informazioni, consulta Collegamento in rete per i bucket di directory.
Utilizzare l’autenticazione della sessione e riutilizzare i token di sessione finché validi
I bucket di directory forniscono un meccanismo di autenticazione dei token di sessione per ridurre la latenza sulle operazioni API sensibili alle prestazioni. È possibile effettuare una singola chiamata a CreateSession per ottenere un token di sessione valido per tutte le richieste nei 5 minuti successivi. Per ottenere la latenza più bassa nelle chiamate API, assicurati di acquisire un token di sessione e riutilizzarlo per la sua intera durata prima di aggiornarlo.
Se utilizzi gli SDK, AWS gli SDK gestiscono automaticamente gli aggiornamenti dei token di sessione per evitare interruzioni del servizio alla scadenza di una sessione. Ti consigliamo di utilizzare gli AWS SDK per avviare e gestire le richieste relative al funzionamento dell'API. CreateSession
Per ulteriori informazioni su CreateSession, consultare Autorizzazione delle operazioni API dell'endpoint di zona con CreateSession.
Usa un client CRT-based
AWS Common Runtime (CRT) è un insieme di librerie modulari, performanti ed efficienti scritte in C e pensate per fungere da base degli AWS SDK. CRT offre un maggiore throughput, una migliore gestione delle connessioni e tempi di avvio più rapidi. Il CRT è disponibile tramite tutti gli SDK tranne Go. AWS
Per ulteriori informazioni su come configurare il CRT per l'SDK che utilizzi, consulta le librerie AWS Common Runtime (CRT), Accelerazione del throughput di Amazon S3 con AWS Common Runtime, Introduzione del
Usa la versione più recente di AWS SDK
Gli AWS SDK forniscono supporto integrato per molte delle linee guida consigliate per l'ottimizzazione delle prestazioni di Amazon S3. Gli SDK offrono un’API più semplice per utilizzare al meglio Amazon S3 internamente a un’applicazione e vengono aggiornati regolarmente in modo da seguire le best practice più recenti. Ad esempio, gli SDK riprovano automaticamente le richieste dopo gli errori HTTP 503 e gestiscono le risposte di connessioni lente.
Se utilizzi l'Java 2.xSDK, dovresti prendere in considerazione l'utilizzo di S3 Transfer Manager, che ridimensiona automaticamente le connessioni orizzontalmente per raggiungere migliaia di richieste al secondo utilizzando richieste con intervallo di byte, se necessario. Byte-range le richieste possono migliorare le prestazioni perché è possibile utilizzare connessioni simultanee a S3 per recuperare intervalli di byte diversi dall'interno dello stesso oggetto. Questa operazione ti permette di ottenere un throughput aggregato superiore rispetto a una singola richiesta whole-object. È quindi importante utilizzare l'ultima versione degli AWS SDK per ottenere le più recenti funzionalità di ottimizzazione delle prestazioni.
Risoluzione dei problemi relativi alle prestazioni
Si impostano le richieste dei tentativi per applicazioni sensibili alla latenza?
S3 Express One Zone è progettato appositamente per offrire livelli costanti di alte prestazioni senza ulteriori regolazioni. Tuttavia, l'impostazione di valori di timeout aggressivi e nuovi tentativi possono contribuire ulteriormente a garantire latenza e prestazioni costanti. Gli AWS SDK dispongono di valori di timeout e riprova configurabili che puoi regolare in base alle tolleranze della tua applicazione specifica.
Stai usando AWS Librerie Common Runtime (CRT) e tipi di istanze Amazon EC2 ottimali?
Le applicazioni che eseguono un elevato numero di operazioni di lettura e scrittura richiedono una capacità di memoria o calcolo superiore rispetto alle applicazioni che non eseguono tali operazioni. Durante il lancio delle istanze Amazon Elastic Compute Cloud (Amazon EC2) per carichi di lavoro esigenti in termini di prestazioni, scegli i tipi di istanza che dispongono della quantità di risorse necessaria per l'applicazione. L'archiviazione ad alte prestazioni S3 Express One Zone è abbinata idealmente a tipi di istanza più recenti con quantità maggiori di memoria di sistema, nonché CPU e GPU più potenti che possono sfruttare l'archiviazione ad alte prestazioni. Consigliamo inoltre di utilizzare le versioni più recenti degli CRT-enabled AWS SDK, che possono accelerare meglio le richieste di lettura e scrittura in parallelo.
Stai usando AWS SDK per l'autenticazione basata sulla sessione?
Con Amazon S3, puoi anche ottimizzare le prestazioni quando utilizzi le richieste API REST HTTP seguendo le stesse best practice che fanno parte degli AWS SDK. Tuttavia, con il meccanismo di autorizzazione e autenticazione basato sulla sessione utilizzato da S3 Express One Zone, ti consigliamo vivamente di utilizzare gli AWS SDK per la gestione e il relativo token di sessione gestitoCreateSession. Gli AWS SDK creano e aggiornano automaticamente i token per tuo conto utilizzando l'operazione API. CreateSession Utilizza la CreateSession latenza di andata e ritorno (IAM) per ogni richiesta per autorizzare AWS Identity and Access Management ogni richiesta.
Esempi di funzionamento del bucket di directory e di interazione con le directory
Di seguito vengono illustrati tre esempi su come funzionano i bucket di directory.
Esempio 1: in che modo le richieste PutObject S3 a un bucket di directory interagiscono con le directory
-
Quando l’operazione
PUT(<bucket>, "documents/reports/quarterly.txt")viene eseguita in un bucket vuoto, viene creata la directorydocuments/all’interno della root del bucket, viene creata la directoryreports/all’interno didocuments/e viene creato l’oggettoquarterly.txtall’interno direports/. Per questa operazione, sono state create due directory oltre all’oggetto.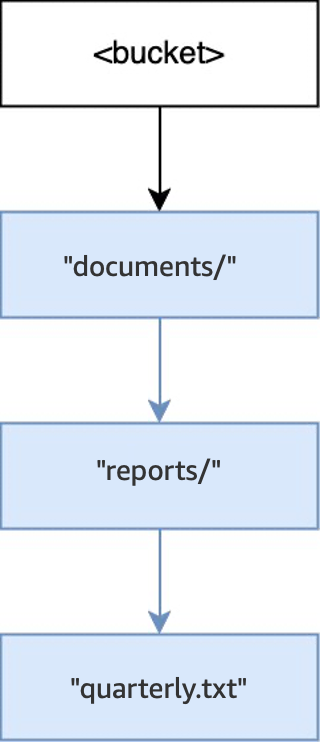
-
Quindi, quando viene eseguita un’altra operazione
PUT(<bucket>, "documents/logs/application.txt"), la directorydocuments/esiste già, la directorylogs/non esiste all’interno didocuments/e viene creata e viene creato l’oggettoapplication.txtall’interno dilogs/. Per questa operazione, è stata creata una sola directory oltre all’oggetto.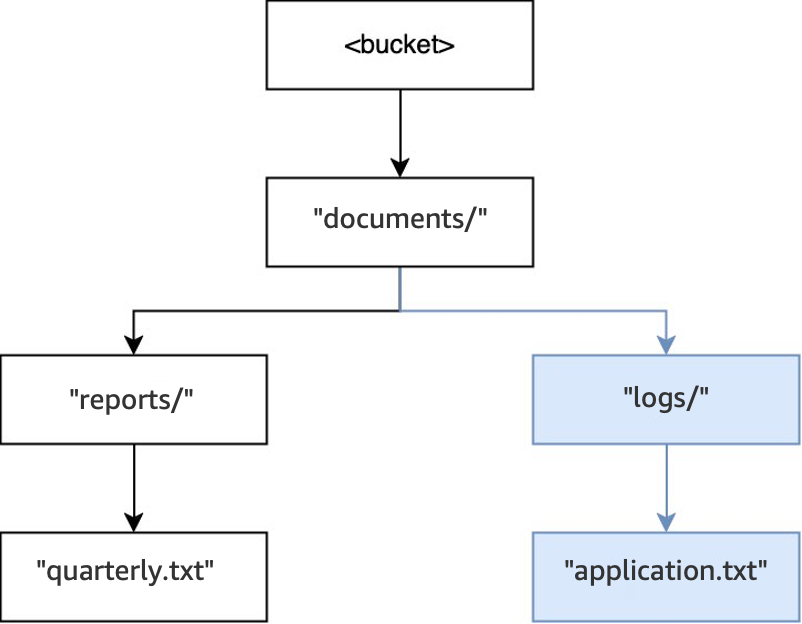
-
Infine, quando viene eseguita un’operazione
PUT(<bucket>, "documents/readme.txt"), la directorydocuments/all’interno della root esiste già e l’oggettoreadme.txtviene creato. Per questa operazione, non viene creata alcuna directory.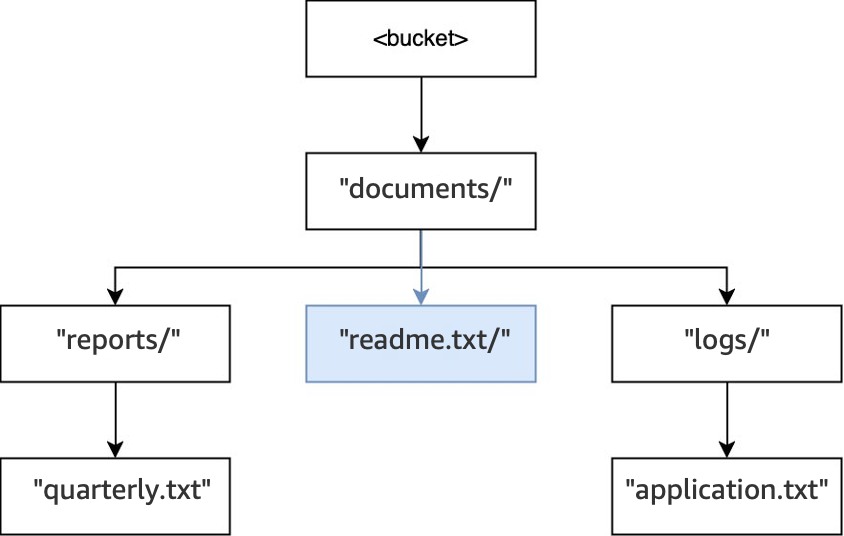
Esempio 2: come le richieste S3 ListObjectsV2 a un bucket di directory interagiscono con le directory
Per le richieste ListObjectsV2 S3 senza un delimitatore, un bucket viene attraversato in modalità depth-first. Gli output vengono restituiti in un ordine coerente. Tuttavia, sebbene questa disposizione rimanga la stessa tra le richieste, non è in ordine lessicografico. Per il bucket e le directory creati nell’esempio precedente:
-
Quando viene eseguito
LIST(<bucket>), la directorydocuments/viene inserita e ha inizio l’attraversamento. -
La sottodirectory
logs/viene inserita e ha inizio l’attraversamento. -
L’oggetto
application.txtsi trova all’interno dilogs/. -
All’interno di
logs/non esistono altre voci. L’operazione List esce dalogs/ed entra nuovamente indocuments/. -
La directory
documents/continua a essere attraversata e l’oggettoreadme.txtviene trovato. -
La directory
documents/continua a essere attraversata, la sottodirectoryreports/viene inserita e l’attraversamento ha inizio. -
L’oggetto
quarterly.txtsi trova all’interno direports/. -
All’interno di
reports/non esistono altre voci. L’elenco esce dareports/ed entra di nuovo indocuments/. -
Non esistono altre voci all’interno di
documents/e viene restituito l’elenco.
In questo esempio, logs/ viene ordinato prima di readme.txt e readme.txt viene ordinato prima di reports/.
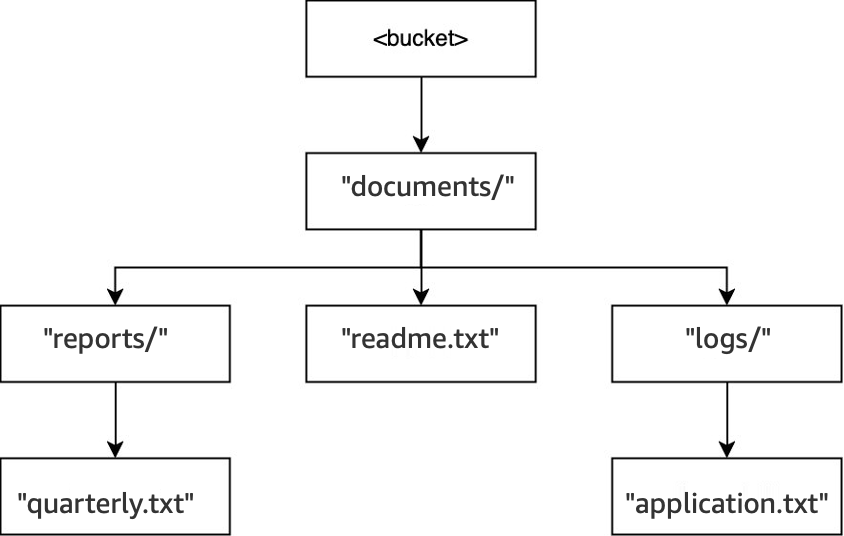
Esempio 3: in che modo le richieste DeleteObject S3 a un bucket di directory interagiscono con le directory
-
Nello stesso bucket, quando viene eseguita l’operazione
DELETE(<bucket>, "documents/reports/quarterly.txt"), l’oggettoquarterly.txtviene eliminato, lasciando la directoryreports/vuota e provocandone l’eliminazione immediata. La directorydocuments/non è vuota perché contiene sia la directorylogs/sia l’oggettoreadme.txt, quindi non viene eliminata. Per questa operazione, sono stati eliminati un solo oggetto e una sola directory.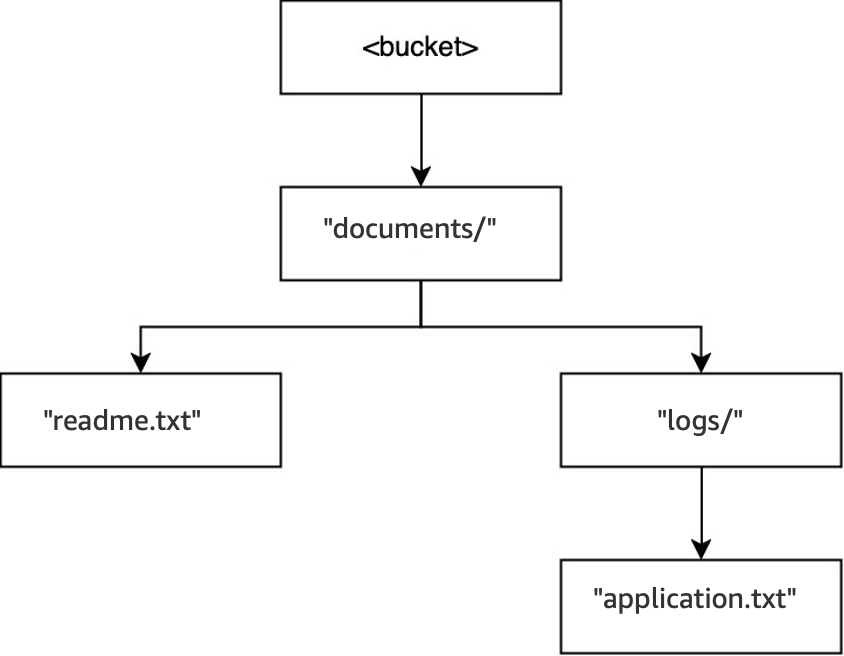
-
Quando l’operazione
DELETE(<bucket>, "documents/readme.txt")viene eseguita, l’oggettoreadme.txtviene eliminato.documents/non è ancora vuota perché contiene la directorylogs/, quindi non viene eliminata. Per questa operazione, non viene eliminata alcuna directory e viene eliminato solo l’oggetto.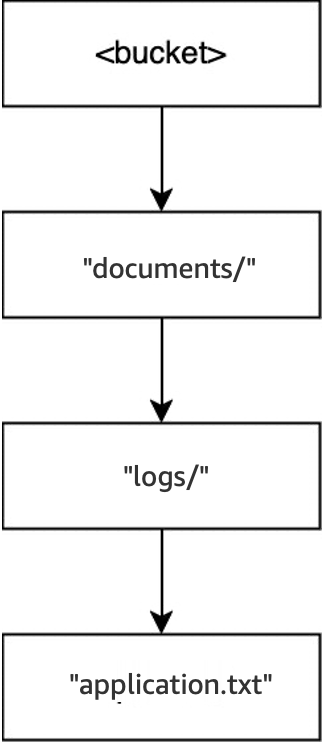
-
Infine, quando viene eseguita l’operazione
DELETE(<bucket>, "documents/logs/application.txt"),application.txtviene eliminato, lasciandologs/vuota e provocandone l’eliminazione immediata. Questa operazione lasciadocuments/vuota e viene anch’essa eliminata immediatamente. Per questa operazione, vengono eliminati due directory e un oggetto. Il bucket ora è vuoto.
