Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Risoluzione dei problemi di intelligenza artificiale generativa per Apache Spark in AWS Aderenza
La risoluzione dei problemi di intelligenza artificiale generativa per i lavori di Apache Spark in AWS Glue è una nuova funzionalità che aiuta i data engineer e gli scienziati a diagnosticare e risolvere i problemi nelle loro applicazioni Spark con facilità. Utilizzando tecnologie di machine learning e IA generativa, questa funzionalità analizza i problemi nei processi Spark e fornisce un'analisi dettagliata delle cause principali insieme a consigli pratici per risolverli. La risoluzione dei problemi di intelligenza artificiale generativa per Apache Spark è disponibile per i lavori in esecuzione su AWS Glue versione 4.0 e successive.
|
Trasforma la risoluzione dei problemi di Apache Spark con il nostro AI-powered Troubleshooting Agent, che ora supporta tutte le principali modalità di implementazione tra cui AWS Glue, Amazon, EMR-EC2 Amazon e EMR-Serverless Amazon SageMaker AI Notebooks. Questo potente agente elimina complessi processi di debug combinando interazioni in linguaggio naturale, analisi del carico di lavoro in tempo reale e consigli sul codice intelligente in un'esperienza senza interruzioni. Per i dettagli sull'implementazione, consulta Cos'è l'agente di risoluzione dei problemi di Apache Spark per Amazon EMR. Guarda la seconda dimostrazione in Using the Troubleshooting Agent for AWS Glue: esempi di risoluzione dei problemi. |
Come funzione la risoluzione dei problemi relativi all'IA generativa per Apache Spark?
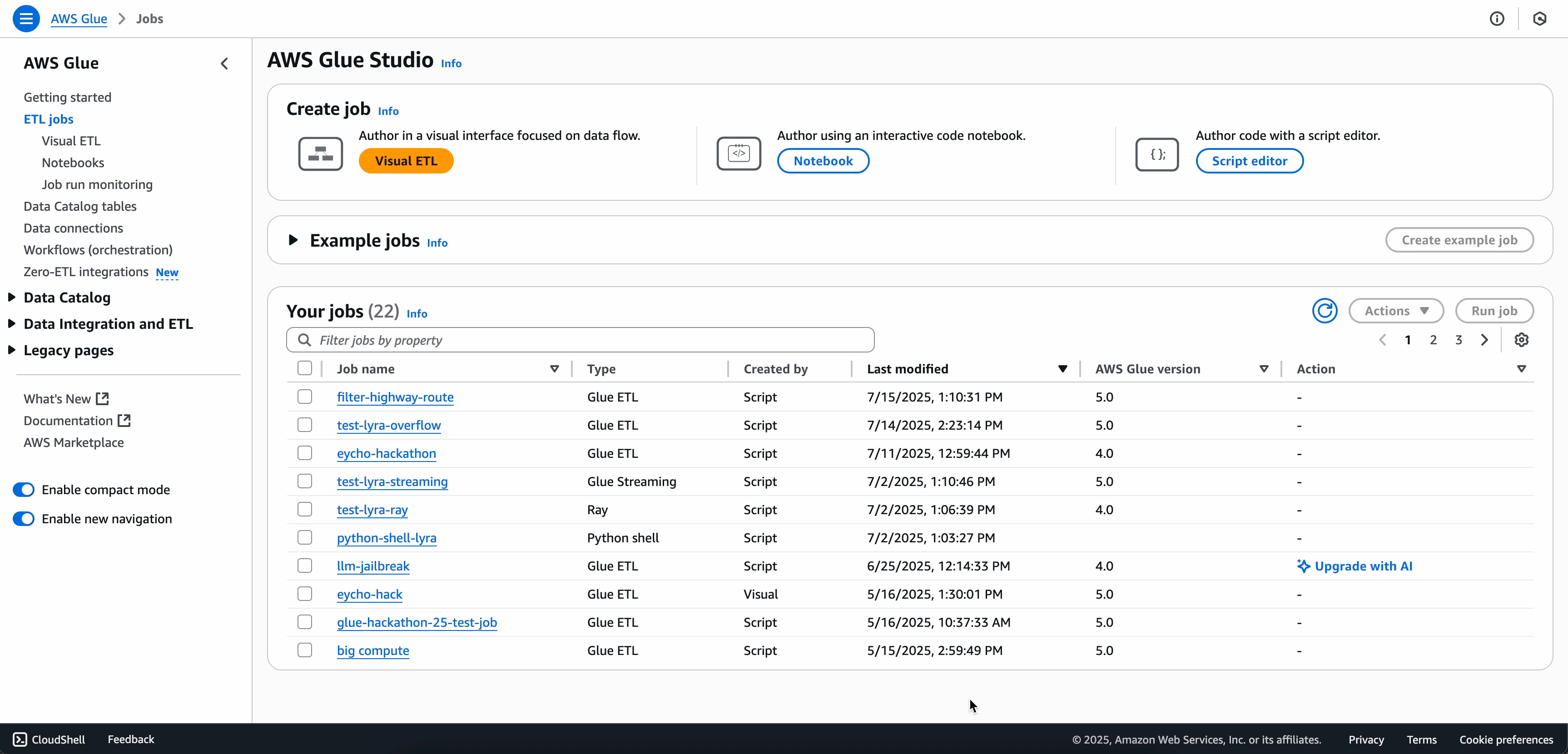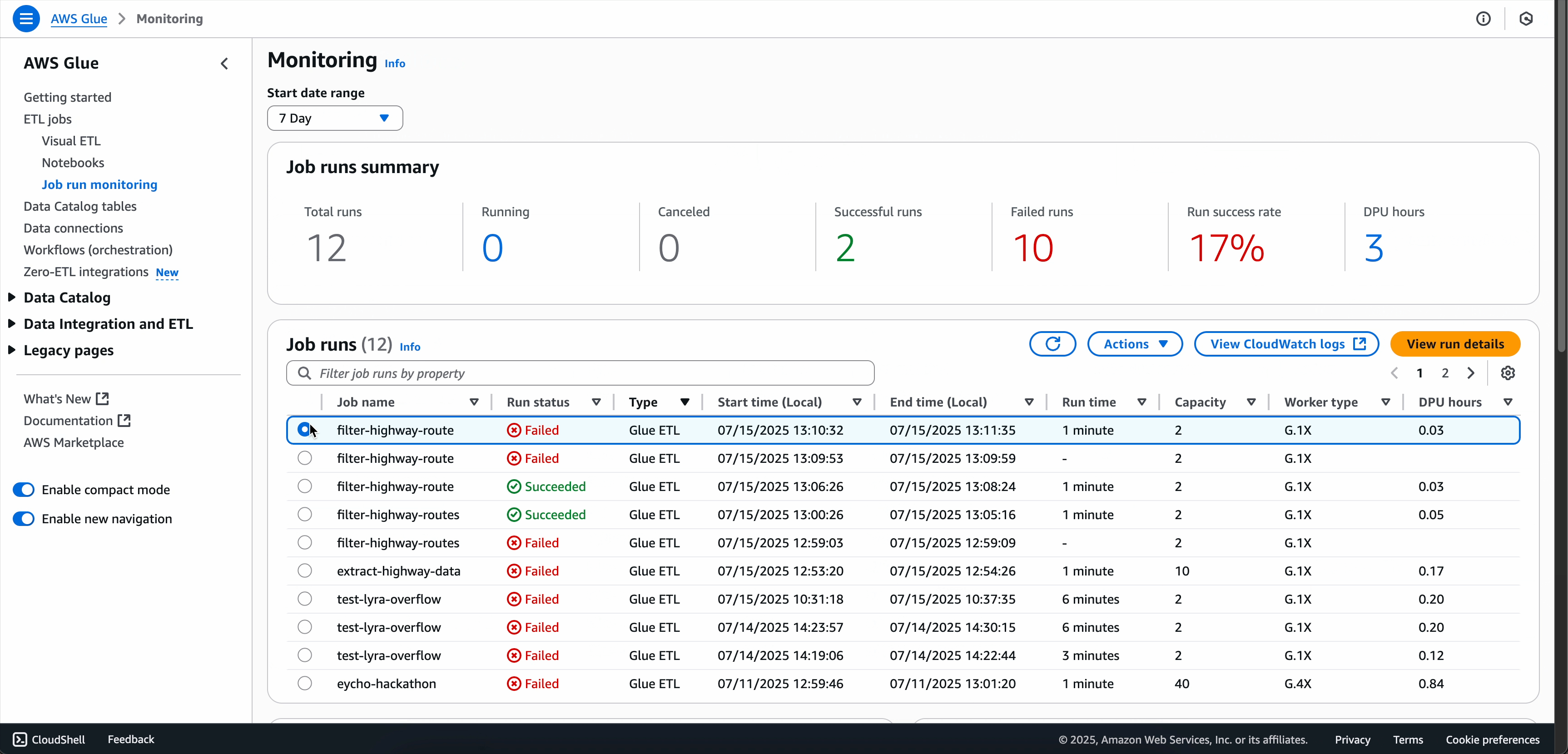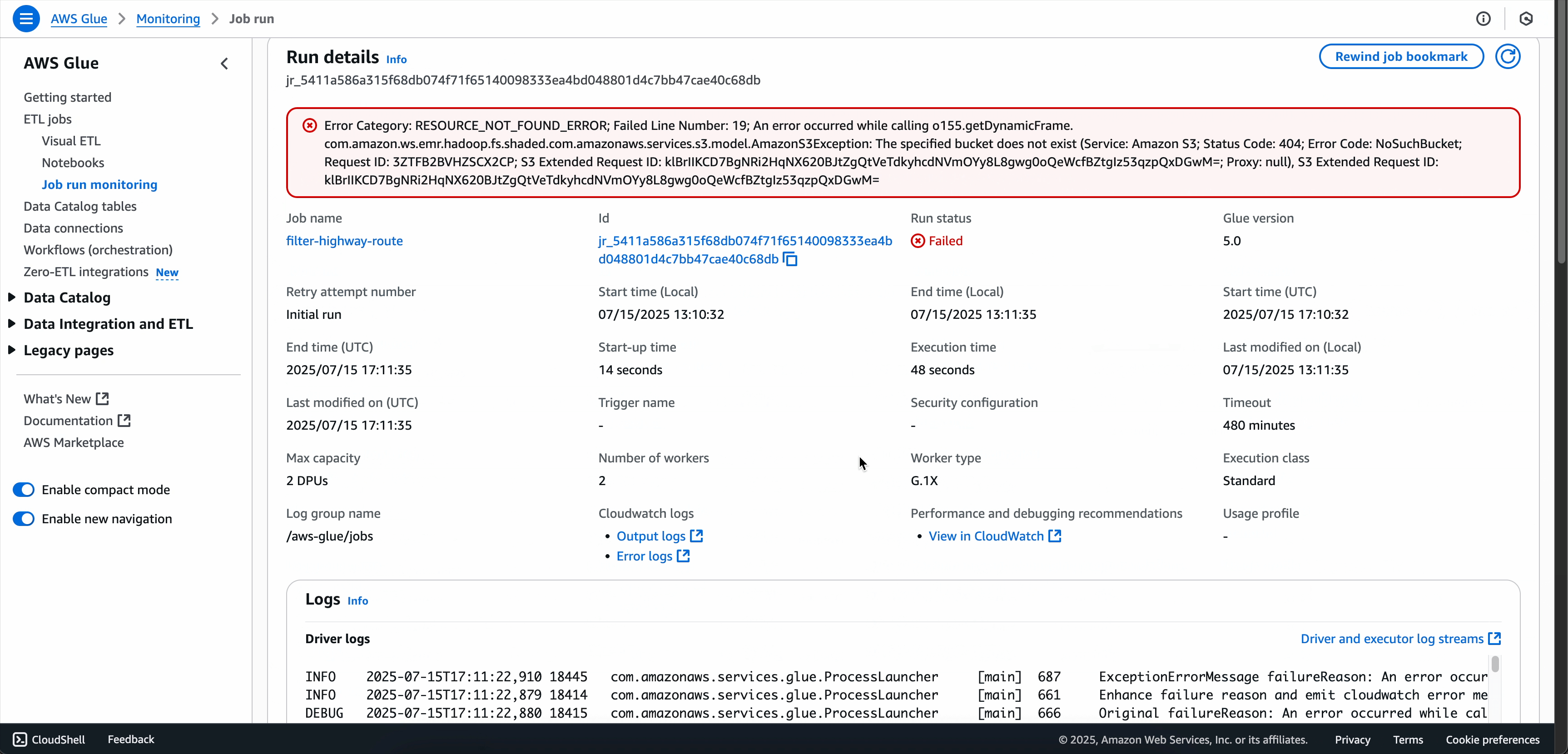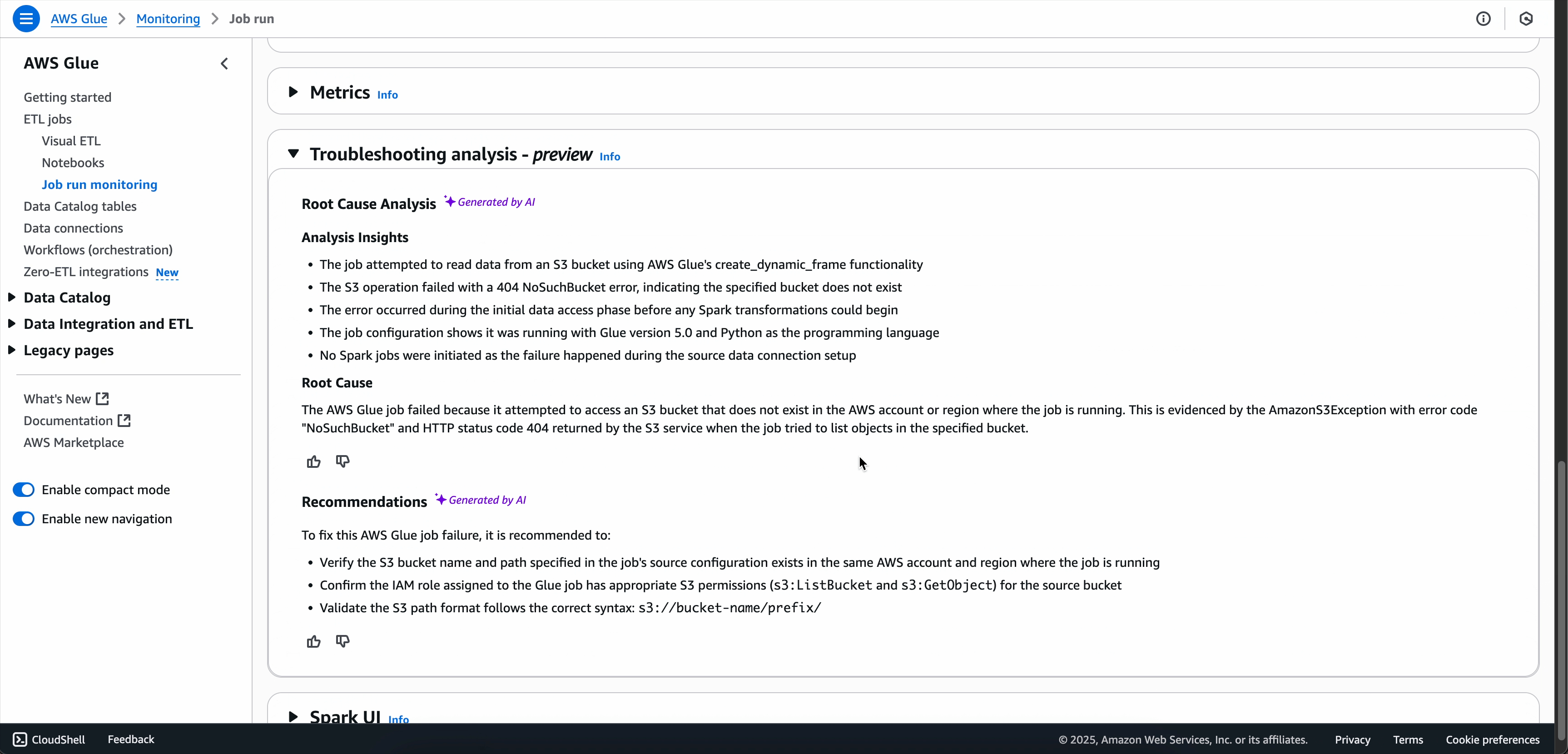
Per i job Spark non riusciti, Generative AI Troubleshooting analizza i metadati del lavoro e le metriche e i log precisi associati alla firma di errore del job per generare un'analisi della causa principale e consiglia soluzioni e best practice specifiche per aiutare a risolvere i problemi del lavoro.
Configurare la risoluzione dei problemi relativi all'IA generativa per Apache Spark per i processi
Configurazione delle autorizzazioni IAM
La concessione delle autorizzazioni alle API utilizzate da Spark Troubleshooting per i tuoi lavori in AWS Glue richiede le autorizzazioni IAM appropriate. Puoi ottenere le autorizzazioni allegando la seguente AWS policy personalizzata alla tua identità IAM (ad esempio un utente, un ruolo o un gruppo).
Nota
Le seguenti due API vengono utilizzate nella policy IAM per abilitare questa esperienza tramite la console AWS Glue Studio: StartCompletion eGetCompletion.
Assegnare le autorizzazioni
Per fornire l’accesso, aggiungi autorizzazioni agli utenti, gruppi o ruoli:
-
Per utenti e gruppi nel Centro identità IAM: Creazione di un set di autorizzazioni. Seguire le istruzioni riportate nella pagina Creazione di un set di autorizzazioni nella Guida per l'utente del Centro identità IAM.
-
Per utenti gestiti in IAM tramite un provider di identità: crea un ruolo per la federazione delle identità. Seguire le istruzioni riportate nella pagina Creazione di un ruolo per un provider di identità di terze parti (federazione) nella Guida per l'utente di IAM.
-
Per utenti IAM: Creare un ruolo che l'utente è in grado di assumere. Seguire le istruzioni riportate nella pagina Creazione di un ruolo per un utente IAM della Guida per l'utente di IAM.
Esecuzione dell'analisi della risoluzione dei problemi da un'esecuzione non riuscita di un processo
È possibile accedere alla funzionalità di risoluzione dei problemi tramite più percorsi nella console AWS Glue. Ecco come iniziare:
Opzione 1: dalla pagina Elenco dei processi
-
Apri la console AWS Glue all'indirizzo https://console.aws.amazon.com/glue/
. -
Nel riquadro di navigazione, scegliere Processi.
-
Individuare il processo non riuscito nell'elenco dei processi.
-
Selezionare la scheda Esecuzioni nella sezione dei dettagli del processo.
-
Fare clic sull'esecuzione del processo non riuscito che si desidera analizzare.
-
Scegliere Risoluzione dei problemi con IA per avviare l'analisi.
-
Una volta completata l'analisi della risoluzione dei problemi, è possibile visualizzare l'analisi della causa principale e i consigli nella scheda Analisi della risoluzione dei problemi nella parte inferiore dello schermo.
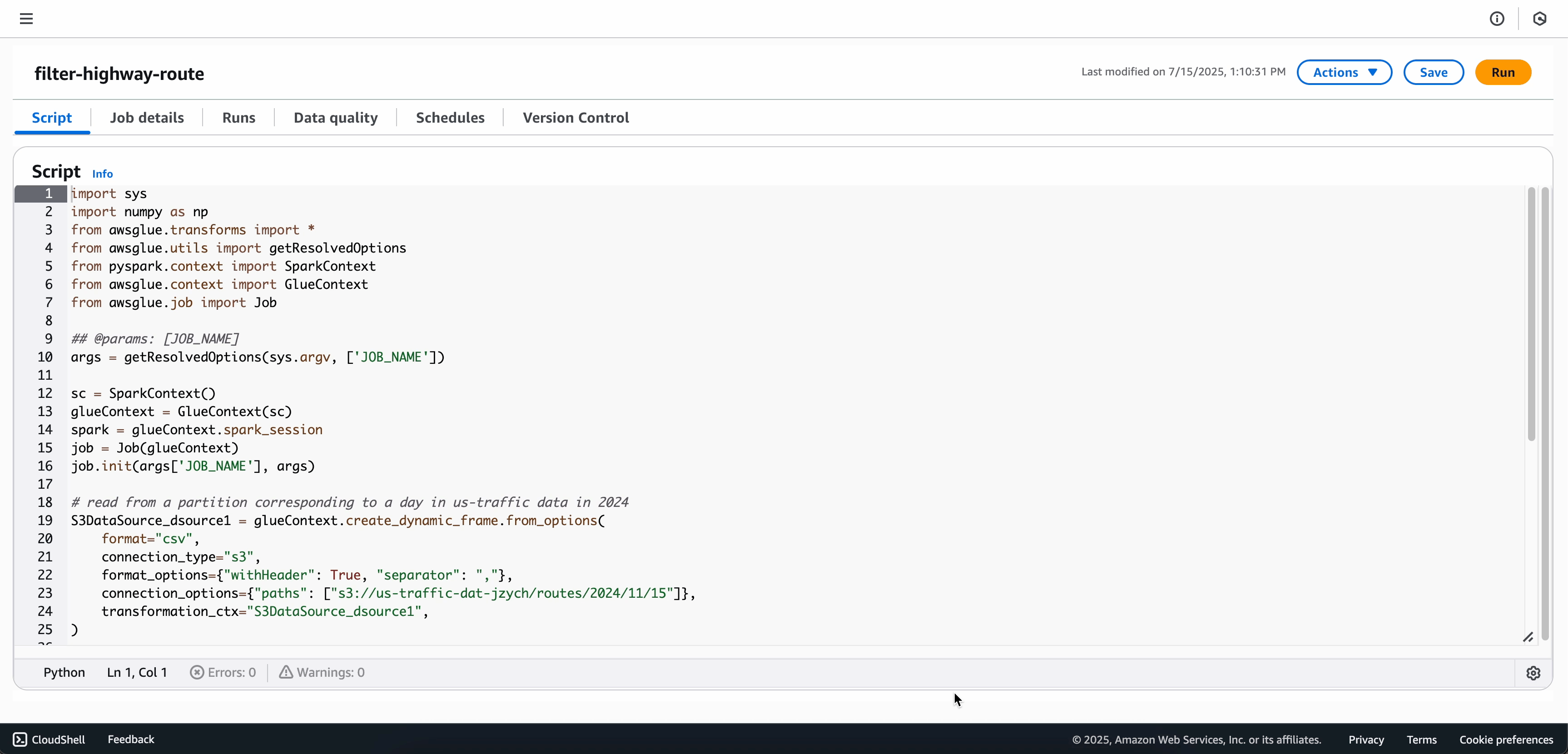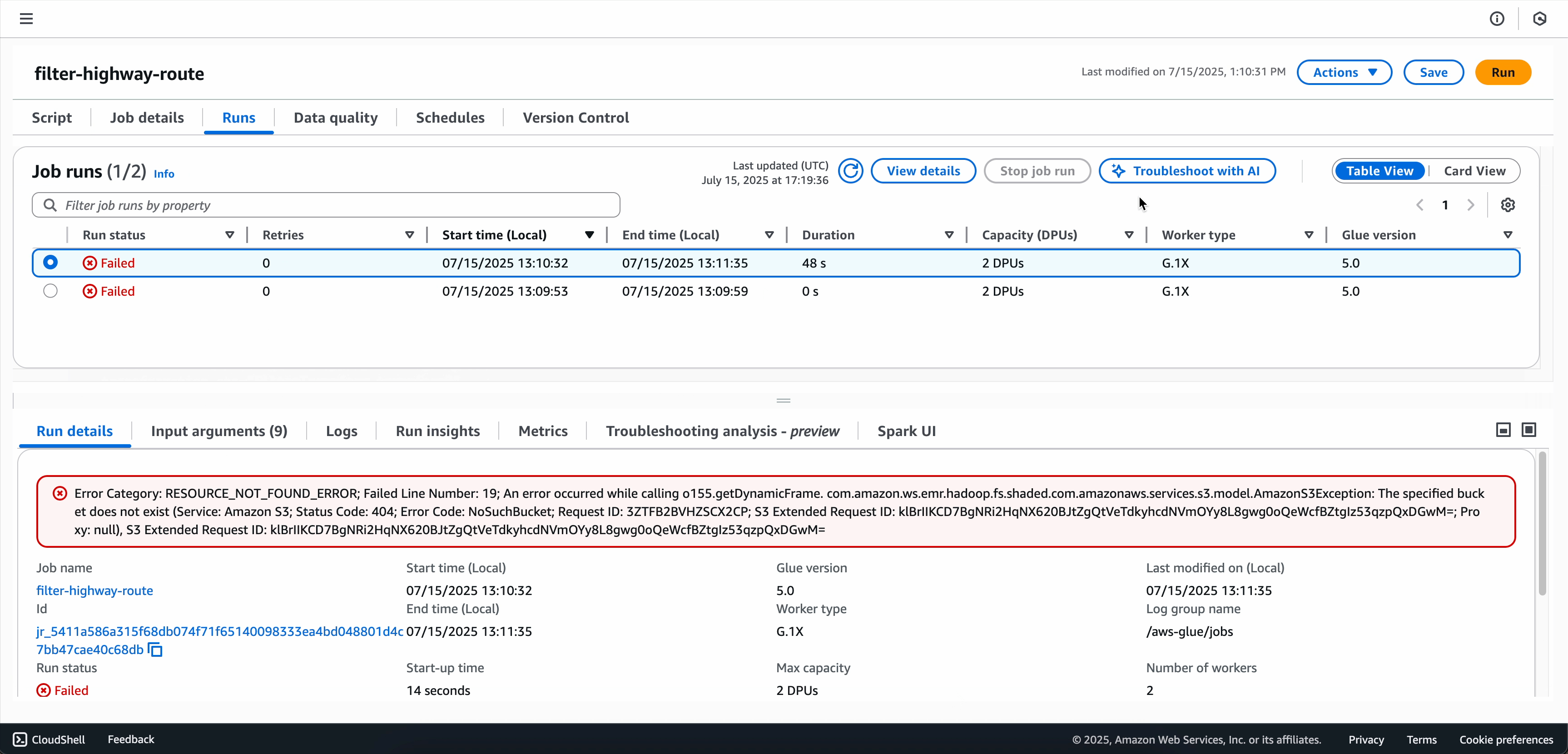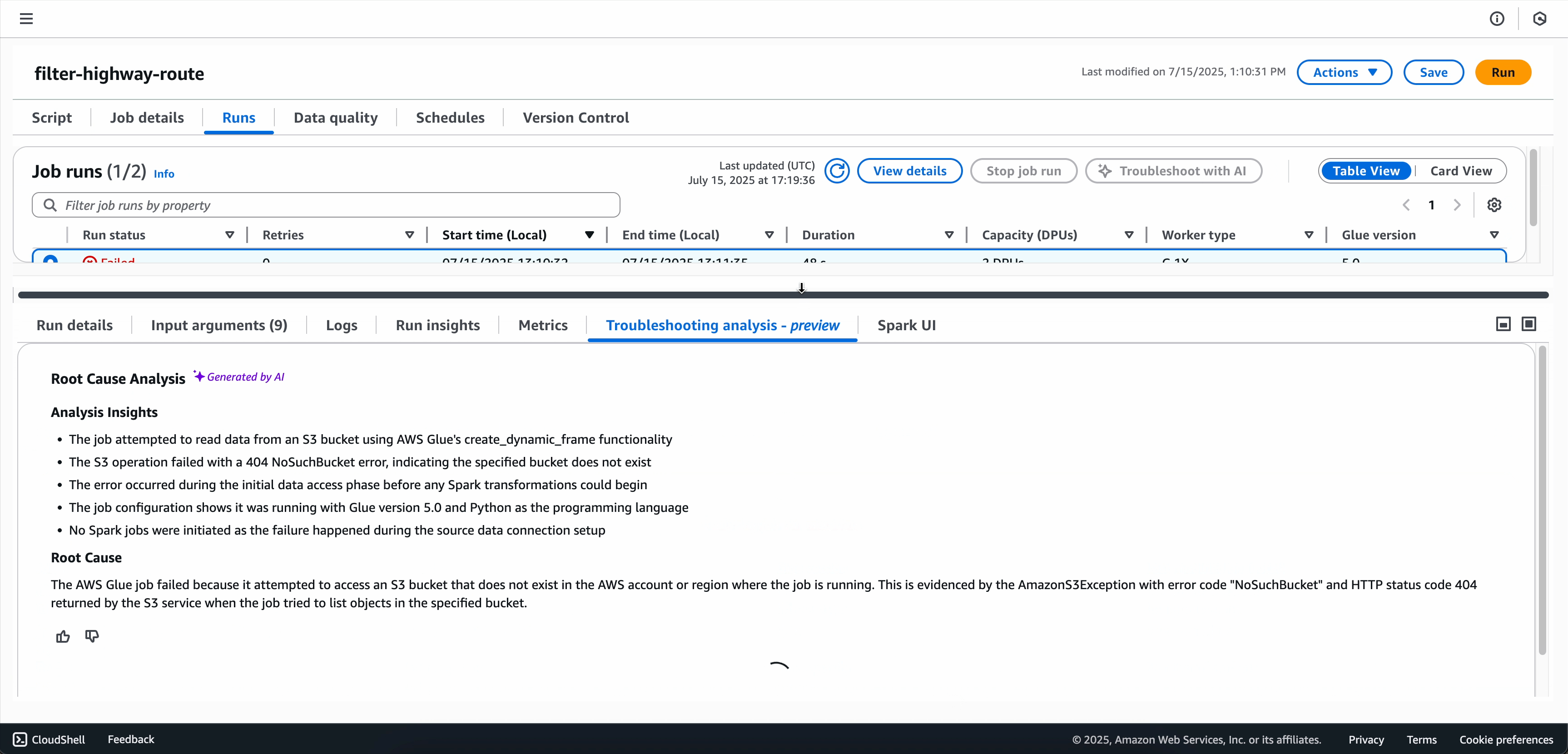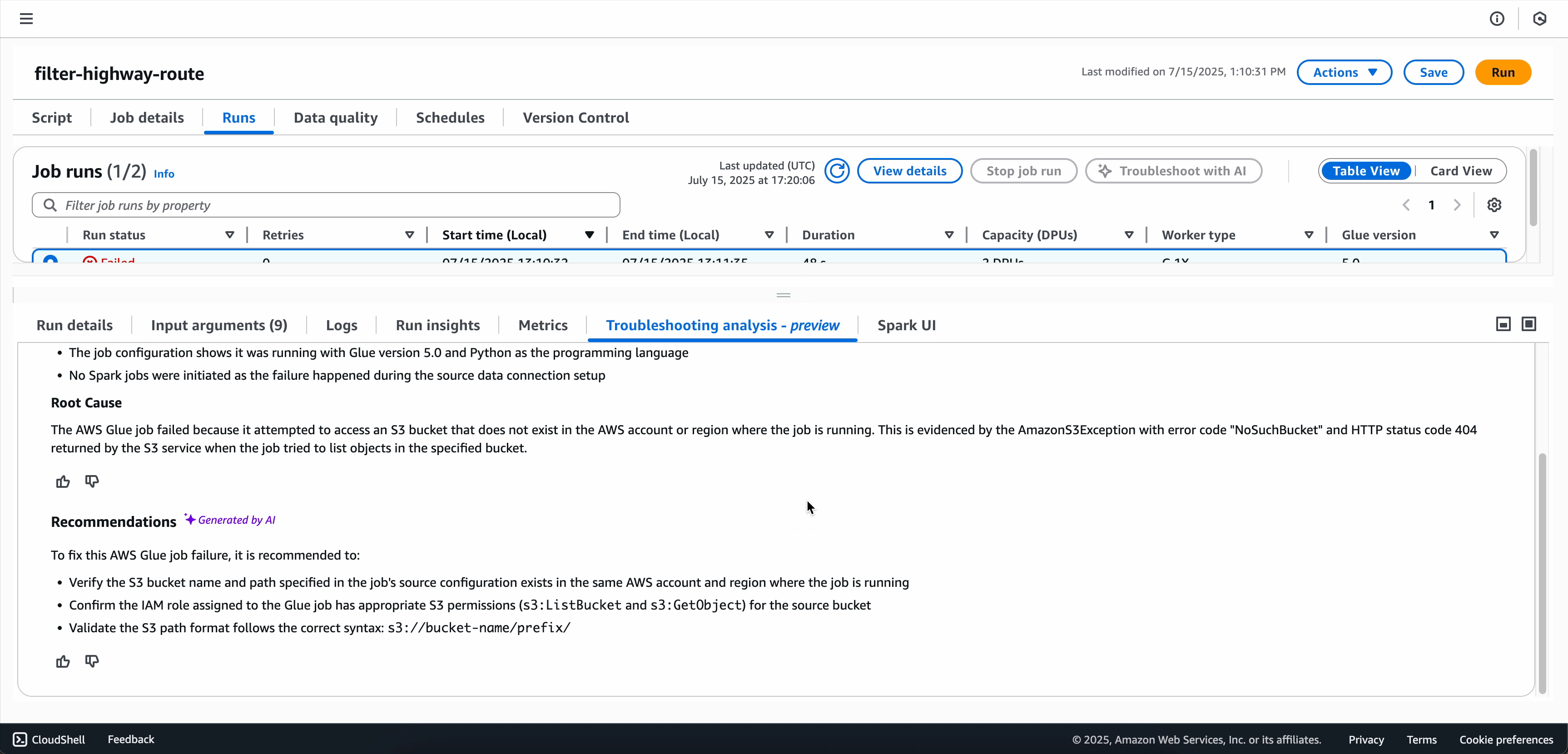
Opzione 2: usare la pagina Monitoraggio dell'esecuzione dei processi
-
Andare alla pagina Monitoraggio dell'esecuzione dei processi.
-
Individuare l'esecuzione del processo non riuscito.
-
Selezionare il menu a discesa Operazioni.
-
Scegliere Risoluzione dei problemi con IA.
Opzione 3: dalla pagina Dettagli dell'esecuzione dei processi
-
Andare sulla pagina dei dettagli dell'esecuzione del processo non riuscito facendo clic su Visualizza dettagli su un'esecuzione non riuscita dalla scheda Esecuzioni o selezionando il processo eseguito dalla pagina Monitoraggio dell'esecuzione dei processi.
-
Nella pagina dei dettagli dell'esecuzione del processo, individuare la scheda Analisi della risoluzione dei problemi.
Categorie di risoluzione dei problemi supportate
Questo servizio si concentra su tre categorie principali di problemi che gli scienziati dei dati e gli sviluppatori affrontano frequentemente nelle loro applicazioni Spark:
-
Errori di configurazione e accesso alle risorse: quando si eseguono applicazioni Spark in AWS Glue, gli errori di configurazione e accesso alle risorse sono tra i problemi più comuni ma difficili da diagnosticare. Questi errori si verificano spesso quando l'applicazione Spark tenta di interagire con AWS le risorse ma riscontra problemi di autorizzazione, risorse mancanti o problemi di configurazione.
-
Problemi di memoria del driver Spark e dell'executor: Memory-related gli errori nei job di Apache Spark possono essere complessi da diagnosticare e risolvere. Questi errori si verificano spesso quando i requisiti di elaborazione dei dati superano le risorse di memoria disponibili, sul nodo driver o sui nodi esecutori.
-
Problemi di capacità del disco Spark: Storage-related gli errori nei job di AWS Glue Spark spesso emergono durante le operazioni di shuffle, la fuoriuscita di dati o quando si tratta di trasformazioni di dati su larga scala. Questi errori possono essere particolarmente complicati perché potrebbero verificarsi solo dopo un certo periodo di esecuzione del processo, con il rischio di sprecare risorse di elaborazione e tempo preziosi.
-
Errori di esecuzione delle query: gli errori di query in Spark SQL e nelle DataFrame operazioni possono essere difficili da risolvere perché i messaggi di errore potrebbero non indicare chiaramente la causa principale e le query che funzionano bene con set di dati di piccole dimensioni possono improvvisamente fallire su larga scala. Questi errori diventano ancora più difficili quando si verificano all'interno di pipeline di trasformazione complesse, dove il vero problema può derivare da problemi di qualità dei dati nelle fasi precedenti piuttosto che dalla logica di interrogazione stessa.
Nota
Prima di implementare le modifiche suggerite nell'ambiente di produzione, esaminare attentamente le modifiche suggerite. Il servizio fornisce consigli basati su modelli e best practice, ma il caso d'uso specifico potrebbe richiedere ulteriori considerazioni.
Regioni supportate
La risoluzione dei problemi di intelligenza artificiale generativa per Apache Spark è disponibile nelle seguenti regioni:
-
Africa: Città del Capo (af-south-1)
-
Asia Pacifico: Hong Kong (ap-east-1), Tokyo (ap-northeast-1), Seul (ap-northeast-2), Osaka (ap-northeast-3), Mumbai (ap-south-1), Singapore (ap-southeast-1)), Sydney (ap-southeast-2) e Giacarta (ap-southeast-3)
-
Europa: Francoforte (eu-central-1), Stoccolma (eu-north-1), Milano (eu-south-1), Irlanda (eu-west-1), Londra (eu-west-2) e Parigi (eu-west-3)
-
Medio Oriente: Bahrein (me-south-1) e Emirati Arabi Uniti (me-central-1)
-
Nord America: Canada (ca-central-1)
-
Sud America: San Paolo (sa-east-1)
-
Stati Uniti: Virginia del Nord (us-east-1), Ohio (us-east-2), California del Nord (us-west-1) e Oregon (us-west-2)
