Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Arricchimento semantico automatico per Amazon Service OpenSearch
Introduzione
Amazon OpenSearch Service utilizza la corrispondenza parola per parola (ricerca lessicale) per trovare risultati, in modo simile ad altri motori di ricerca tradizionali. Questo approccio funziona bene per domande specifiche come codici di prodotto o numeri di modello, ma ha difficoltà con le ricerche astratte in cui la comprensione delle intenzioni dell'utente diventa fondamentale. Ad esempio, quando cerchi «scarpe per la spiaggia», la ricerca lessicale trova le singole parole «scarpe», «spiaggia», «per» e «il» negli articoli del catalogo, quindi potrebbero mancare prodotti pertinenti come «sandali impermeabili» o «calzature da surf» che non contengono i termini di ricerca esatti.
L'arricchimento semantico automatico risolve questa limitazione considerando sia le corrispondenze delle parole chiave sia il significato contestuale delle ricerche. Questa funzionalità comprende l'intento di ricerca e migliora la pertinenza della ricerca fino al 20%. Abilita questa funzionalità per i campi di testo dell'indice per migliorare i risultati di ricerca.
Nota
L'arricchimento semantico automatico è disponibile per i domini di OpenSearch servizio che eseguono la versione 2.19 o successiva. Inoltre, anche i domini con OpenSearch versione 2.19 devono disporre dell'ultimo aggiornamento della versione del software di servizio. Attualmente, la funzionalità è disponibile per i domini pubblici e i domini VPC non sono supportati.
Dettagli del modello e benchmark delle prestazioni
Sebbene questa funzionalità gestisca le complessità tecniche dietro le quinte senza esporre il modello sottostante, forniamo trasparenza attraverso una breve descrizione del modello e risultati di benchmark per aiutarvi a prendere decisioni informate sull'adozione delle funzionalità nei vostri carichi di lavoro critici.
L'arricchimento semantico automatico utilizza un modello sparso preaddestrato e gestito dai servizi che funziona in modo efficace senza richiedere regolazioni di precisione personalizzate. Il modello analizza i campi specificati, espandendoli in vettori sparsi basati su associazioni apprese da diversi dati di addestramento. I termini estesi e i relativi pesi di significatività vengono archiviati nel formato di indice Lucene nativo per un recupero efficiente. Abbiamo ottimizzato questo processo utilizzando la modalità solo documento, in cui la codifica avviene solo durante l'inserimento
La nostra convalida delle prestazioni durante lo sviluppo delle funzionalità ha utilizzato il set di dati MS MARCO
-
Lingua inglese - Miglioramento della pertinenza del 20% rispetto alla ricerca lessicale. Ha inoltre ridotto la latenza di ricerca P90 del 7,7% rispetto alla ricerca lessicale (BM25 è di 26 ms e l'arricchimento semantico automatico è di 24 ms).
-
Multi-lingual - Miglioramento della pertinenza del 105% rispetto alla ricerca lessicale, mentre la latenza di ricerca P90 è aumentata del 38,4% rispetto alla ricerca lessicale (BM25 è di 26 ms e l'arricchimento semantico automatico è di 36 ms).
Data la natura unica di ogni carico di lavoro, ti invitiamo a valutare questa funzionalità nel tuo ambiente di sviluppo utilizzando i tuoi criteri di benchmarking prima di prendere decisioni di implementazione.
Lingue supportate
La funzionalità supporta l'inglese. Inoltre, il modello supporta anche arabo, bengalese, cinese, finlandese, francese, hindi, indonesiano, giapponese, coreano, persiano, russo, spagnolo, swahili e telugu.
Imposta un indice di arricchimento semantico automatico per i domini
La configurazione di un indice con l'arricchimento semantico automatico abilitato per i campi di testo è semplice e puoi gestirlo tramite la console, le API e CloudFormation i modelli durante la creazione di nuovi indici. Per abilitarlo per un indice esistente, è necessario ricreare l'indice con l'arricchimento semantico automatico abilitato per i campi di testo.
Esperienza da console: la AWS console consente di creare facilmente un indice con campi di arricchimento semantico automatico. Dopo aver selezionato un dominio, troverai il pulsante di creazione dell'indice nella parte superiore della console. Dopo aver fatto clic sul pulsante di creazione dell'indice, troverai le opzioni per definire campi di arricchimento semantico automatico. In un indice, puoi avere combinazioni di arricchimento semantico automatico per l'inglese e campi multilingue, oltre che lessicali.
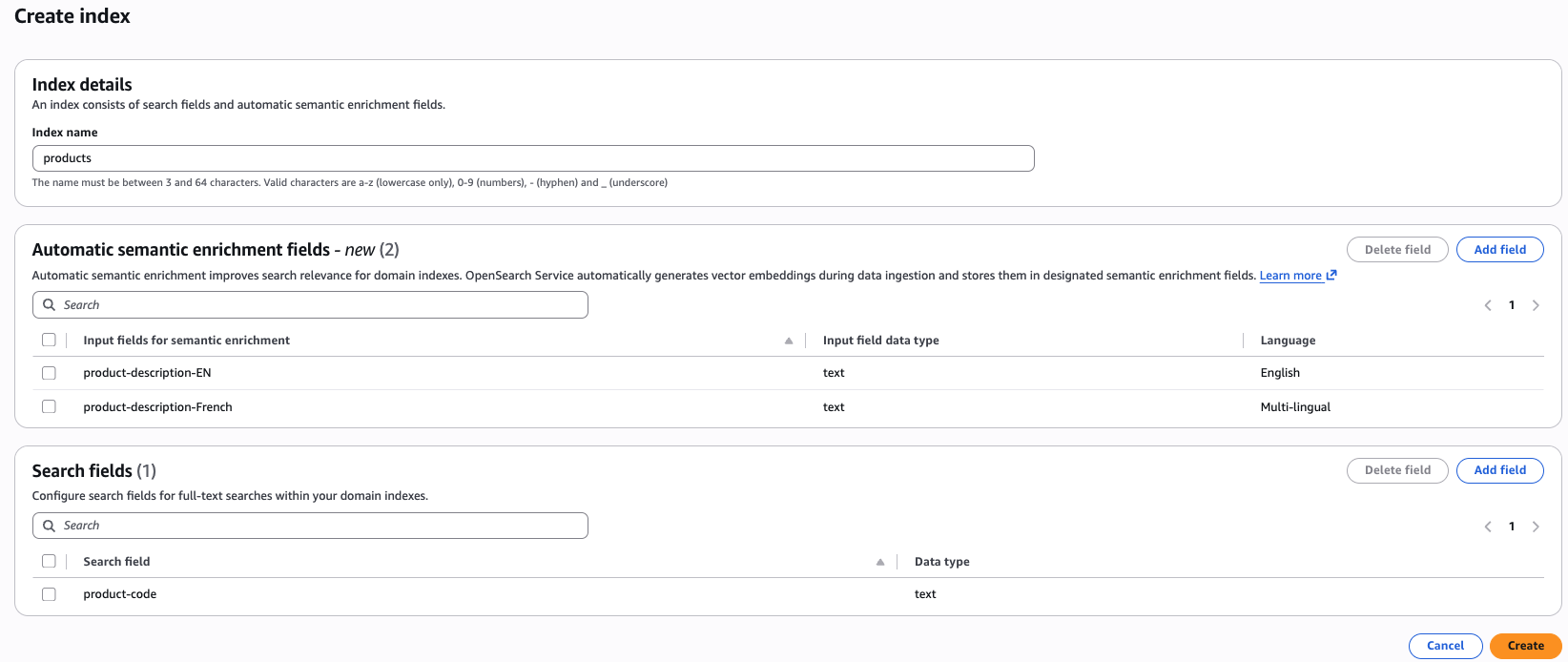
Esperienza API - Per creare un indice di arricchimento semantico automatico utilizzando l'interfaccia a riga di AWS comando (AWS CLI), usa il comando create-index:
aws opensearch create-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body] \
Nell'esempio seguente index-schema, il campo title_semantic ha un tipo di campo impostato su text e il parametro semantic_richment è impostato sullo stato ENABLED. L'impostazione del parametro semantic_enrichment abilita l'arricchimento semantico automatico nel campo title_semantic. Puoi usare il campo language_options per specificare l'inglese o. MULTI-LINGUAL
aws opensearch create-index \ --id XXXXXXXXX \ --index-name 'product-catalog' \ --index-schema '{ "mappings": { "properties": { "product_id": { "type": "keyword" }, "title_semantic": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } }, "title_non_semantic": { "type": "text" } } } }'
Per descrivere l'indice creato, usa il seguente comando:
aws opensearch get-index \ --domain-name [domain_name] \ --index-name [index_name] \
Aggiornare un indice esistente
È possibile aggiornare un indice esistente per aggiungere nuovi campi di arricchimento semantico, abilitare o disabilitare l'arricchimento semantico su campi esistenti o aggiungere campi di testo non semantici. Usa il update-index comando e fornisci solo i campi che desideri modificare in. index-schema I campi non inclusi nella richiesta vengono lasciati invariati.
Nota
L'indice settings non può essere aggiornato. Se includi un settings blocco nella richiesta, l'operazione restituisce un errore di convalida. Per modificare le impostazioni dell'indice, è necessario eliminare e ricreare l'indice.
Per aggiornare un indice utilizzando il AWS CLI, usa il update-index comando:
aws opensearch update-index \ --domain-name [domain_name] \ --index-name [index_name] \ --index-schema [index_body]
Aggiungi un nuovo campo di arricchimento semantico
È possibile aggiungere un nuovo text campo con arricchimento semantico abilitato a un indice esistente. Il servizio configura automaticamente il modello ML, la pipeline di importazione e la pipeline di ricerca richiesti. I nuovi documenti indicizzati dopo l'aggiornamento vengono arricchiti automaticamente.
Importante
I documenti esistenti non vengono riempiti. Per compilare il campo di arricchimento semantico sui documenti esistenti, è necessario reinserirli dopo l'aggiornamento. Fino a quando non verranno reinseriti, i documenti esistenti non trarranno vantaggio dalla ricerca semantica nel nuovo campo.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "description": { "type": "text", "semantic_enrichment": { "status": "ENABLED", "language_options": "english" } } } } }'
Disabilita l'arricchimento semantico su un campo
Per disabilitare l'arricchimento semantico su un campo in cui è attualmente abilitato, imposta su. status DISABLED Il campo viene rimosso dalle pipeline di acquisizione e ricerca. Il campo di testo sottostante e il relativo campo di incorporamento rimangono nell'indice ma non vengono più arricchiti.
aws opensearch update-index \ --domain-name my-domain \ --index-name product-catalog \ --index-schema '{ "mappings": { "properties": { "title_semantic": { "type": "text", "semantic_enrichment": { "status": "DISABLED" } } } } }'
Aggiorna le limitazioni
Le seguenti operazioni non sono supportate update-index e richiedono l'eliminazione e la ricreazione dell'indice:
-
Modifica
language_optionsin un campo su cui attualmente è abilitato l'arricchimento semantico. Disattiva prima il campo, quindi riattivalo con la nuova opzione di lingua. -
Aggiornamento dei campi annidati. L'arricchimento semantico è supportato solo nei campi di primo livello.
text -
Aggiornamento dell'indice.
settings
Nota
Se l'indice ha una pipeline di acquisizione o ricerca personalizzata che non è stata creata mediante l'arricchimento semantico automatico, l'operazione di aggiornamento è bloccata. Rimuovi la pipeline personalizzata prima di aggiungere campi di arricchimento semantico.
Inserimento e ricerca di dati
Dopo aver creato un indice con l'arricchimento semantico automatico abilitato, la funzionalità funziona automaticamente durante il processo di inserimento dei dati, senza bisogno di configurazioni aggiuntive.
Inserimento di dati: quando aggiungi documenti all'indice, il sistema automaticamente:
-
Analizza i campi di testo che hai designato per l'arricchimento semantico
-
Genera codifiche semantiche utilizzando il modello sparse gestito dal servizio OpenSearch
-
Memorizza queste rappresentazioni arricchite insieme ai dati originali
Questo processo utilizza i OpenSearch connettori ML e le pipeline di importazione integrati, che vengono creati e gestiti automaticamente dietro le quinte.
Ricerca: i dati di arricchimento semantico sono già indicizzati, quindi le query vengono eseguite in modo efficiente senza richiamare nuovamente il modello ML. Ciò significa che ottieni una maggiore pertinenza della ricerca senza alcun sovraccarico di latenza di ricerca aggiuntivo.
Configurazione delle autorizzazioni per l'arricchimento semantico automatico
Prima di creare un indice con arricchimento semantico automatico, devi configurare le autorizzazioni richieste. Questa sezione spiega le autorizzazioni necessarie per le diverse operazioni di indicizzazione e come configurarle sia per scenari di controllo degli accessi AWS Identity and Access Management (IAM) che per scenari di controllo degli accessi dettagliati.
autorizzazioni IAM
Le seguenti autorizzazioni IAM sono necessarie per le operazioni di arricchimento semantico automatico. Queste autorizzazioni variano a seconda della specifica operazione di indicizzazione che si desidera eseguire.
CreateIndex Autorizzazioni API
Per creare un indice con arricchimento semantico automatico, sono necessarie le seguenti autorizzazioni IAM:
-
es:CreateIndex— Crea un indice con funzionalità di arricchimento semantico. -
es:ESHttpHead— Esegue richieste HEAD per verificare l'esistenza dell'indice. -
es:ESHttpPut— Esegue richieste PUT per la creazione dell'indice. -
es:ESHttpPost— Esegue richieste POST per le operazioni sull'indice.
UpdateIndex Autorizzazioni API
Per aggiornare un indice esistente con l'arricchimento semantico automatico, sono necessarie le seguenti autorizzazioni IAM:
-
es:UpdateIndex— Aggiorna le impostazioni e le mappature dell'indice. -
es:ESHttpPut— Esegue richieste PUT per gli aggiornamenti degli indici. -
es:ESHttpGet— Esegue richieste GET per recuperare le informazioni sull'indice. -
es:ESHttpPost— Esegue richieste POST per le operazioni di indicizzazione.
GetIndex Autorizzazioni API
Per recuperare informazioni su un indice con arricchimento semantico automatico, sono necessarie le seguenti autorizzazioni IAM:
-
es:GetIndex— Recupera le informazioni e le impostazioni dell'indice. -
es:ESHttpGet— Esegue richieste GET per recuperare i dati dell'indice.
DeleteIndex Autorizzazioni API
Per eliminare un indice con arricchimento semantico automatico, sono necessarie le seguenti autorizzazioni IAM:
-
es:DeleteIndex— Eliminare un indice e i relativi componenti di arricchimento semantico. -
es:ESHttpDelete— Esegue richieste DELETE per la rimozione dell'indice.
Policy IAM di esempio
Il seguente esempio di politica di accesso basata sull'identità fornisce le autorizzazioni necessarie a un utente per gestire gli indici con arricchimento semantico automatico:
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowSemanticEnrichmentIndexOperations", "Effect": "Allow", "Action": [ "es:CreateIndex", "es:UpdateIndex", "es:GetIndex", "es:DeleteIndex", "es:ESHttpHead", "es:ESHttpGet", "es:ESHttpPut", "es:ESHttpPost", "es:ESHttpDelete" ], "Resource": "arn:aws:es:aws-region:111122223333:domain/domain-name" } ] }
Sostituisci aws-region e con i tuoi valori specifici. 111122223333 domain-name È possibile limitare ulteriormente l'accesso specificando particolari modelli di indice nell'ARN della risorsa.
Fine-grained autorizzazioni di controllo degli accessi
Se il tuo dominio Amazon OpenSearch Service ha abilitato il controllo granulare degli accessi, hai bisogno di autorizzazioni aggiuntive oltre alle autorizzazioni IAM. Le seguenti autorizzazioni sono necessarie per ogni operazione di indicizzazione.
CreateIndex Autorizzazioni API
Quando è abilitato il controllo granulare degli accessi, sono necessarie le seguenti autorizzazioni aggiuntive per creare un indice con arricchimento semantico automatico:
-
indices:admin/create— Creazione di operazioni di indicizzazione. -
indices:admin/mapping/put— Creare e aggiornare le mappature degli indici. -
cluster:admin/opensearch/ml/create_connector— Crea connettori di apprendimento automatico per l'elaborazione semantica. -
cluster:admin/opensearch/ml/register_model— Registra modelli di apprendimento automatico per l'arricchimento semantico. -
cluster:admin/ingest/pipeline/put— Crea pipeline di importazione per l'elaborazione dei dati. -
cluster:admin/search/pipeline/put— Crea pipeline di ricerca per l'elaborazione delle query.
UpdateIndex Autorizzazioni API
Quando è abilitato il controllo granulare degli accessi, sono necessarie le seguenti autorizzazioni aggiuntive per aggiornare un indice con arricchimento semantico automatico:
-
indices:admin/get— Recupera le informazioni sull'indice. -
indices:admin/settings/update— Aggiorna le impostazioni dell'indice. -
indices:admin/mapping/put— Aggiorna le mappature degli indici. -
cluster:admin/opensearch/ml/create_connector— Crea connettori per l'apprendimento automatico. -
cluster:admin/opensearch/ml/register_model— Registra modelli di apprendimento automatico. -
cluster:admin/ingest/pipeline/put— Crea pipeline di importazione. -
cluster:admin/search/pipeline/put— Crea pipeline di ricerca. -
cluster:admin/ingest/pipeline/get— Recupera le informazioni sulla pipeline di importazione. -
cluster:admin/search/pipeline/get— Recupera le informazioni sulla pipeline di ricerca.
GetIndex Autorizzazioni API
Quando è abilitato il controllo granulare degli accessi, sono necessarie le seguenti autorizzazioni aggiuntive per recuperare informazioni su un indice con arricchimento semantico automatico:
-
indices:admin/get— Recupera le informazioni sull'indice. -
cluster:admin/ingest/pipeline/get— Recupera le informazioni sulla pipeline di importazione. -
cluster:admin/search/pipeline/get— Recupera le informazioni sulla pipeline di ricerca.
DeleteIndex Autorizzazioni API
Quando è abilitato il controllo granulare degli accessi, è richiesta la seguente autorizzazione aggiuntiva per eliminare un indice con arricchimento semantico automatico:
-
indices:admin/delete— Operazioni di eliminazione dell'indice.
Riscritture delle query
L'arricchimento semantico automatico converte automaticamente le query «match» esistenti in query di ricerca semantiche senza richiedere modifiche alle query. Se una query di corrispondenza fa parte di una query composta, il sistema analizza la struttura delle query, trova le query di corrispondenza e le sostituisce con query sparse neurali. Attualmente, la funzionalità supporta solo la sostituzione delle query «match», indipendentemente dal fatto che si tratti di una query autonoma o di parte di una query composta. «multi_match» non è supportato. Inoltre, la funzionalità supporta tutte le query composte per sostituire le relative query di corrispondenza annidate. Le query composte includono: bool, boosting, constant_score, dis_max, function_score e hybrid.
Limitazioni dell'arricchimento semantico automatico
La ricerca semantica automatica è più efficace se applicata a campi di piccole e medie dimensioni contenenti contenuti in linguaggio naturale, come titoli di film, descrizioni di prodotti, recensioni e riassunti. Sebbene la ricerca semantica aumenti la pertinenza per la maggior parte dei casi d'uso, potrebbe non essere ottimale per determinati scenari. Prendi in considerazione le seguenti limitazioni quando decidi se implementare l'arricchimento semantico automatico per il tuo caso d'uso specifico.
-
Documenti molto lunghi: l'attuale modello sparso elabora solo i primi 8.192 token di ogni documento in inglese. Per i documenti multilingue, sono 512 token. Per articoli lunghi, prendi in considerazione l'implementazione della suddivisione in blocchi dei documenti per garantire l'elaborazione completa dei contenuti.
-
Carichi di lavoro di analisi dei log: l'arricchimento semantico aumenta in modo significativo la dimensione dell'indice, il che potrebbe non essere necessario per l'analisi dei log, dove in genere è sufficiente una corrispondenza esatta. Il contesto semantico aggiuntivo raramente migliora l'efficacia della ricerca nei log abbastanza da giustificare i maggiori requisiti di archiviazione.
-
L'arricchimento semantico automatico non è compatibile con la funzionalità Derived Source.
-
Limitazione: le richieste di inferenza di indicizzazione sono attualmente limitate a 200 TPS per i domini di servizio. OpenSearch Si tratta di un limite non vincolante; contatta il AWS servizio Support per ottenere limiti più elevati.
Prezzi
Amazon OpenSearch Service fattura l'arricchimento semantico automatico in base alle unità di OpenSearch calcolo (OCU) utilizzate durante la generazione di vettori sparsi al momento dell'indicizzazione. Ti viene addebitato solo l'utilizzo effettivo durante l'indicizzazione dei campi di testo in cui hai abilitato l'arricchimento semantico automatico. One Semantic Search OCU può elaborare 11,1 milioni di token per contenuti in inglese. Per elaborare 2,4 miliardi di token, occorrono circa 216 Semantic Search OCU-hours (2,4 miliardi/11,10 milioni). Con un prezzo di 0,24 dollari per ricerca semantica OCU-hour, il costo per l'elaborazione di 10 GB di dati per la ricerca semantica automatica sarebbe di 51 dollari (216 x 0 dollari). OCU-hours 24/OCU-ora). Non sono previsti costi aggiuntivi per la ricerca semantica (OCU) durante le operazioni di ricerca o per l'archiviazione dei dati.
Puoi monitorare questo consumo utilizzando il CloudWatch parametro SemanticSearchOCU Amazon. Per dettagli specifici sui limiti dei token del modello, sul throughput di volume per OCU e un esempio di calcolo di esempio, visita OpenSearch Service Pricing.
Supportata Regioni AWS
L'arricchimento semantico automatico è disponibile nelle seguenti versioni: Regioni AWS
Stati Uniti orientali (Virginia settentrionale)
Stati Uniti orientali (Ohio)
Stati Uniti occidentali (Oregon)
Asia Pacifico (Mumbai)
Asia Pacifico (Singapore)
Asia Pacifico (Sydney)
Asia Pacifico (Tokyo)
Europa (Francoforte)
Europa (Irlanda)
Europa (Stoccolma)
Europa (Spagna)
