Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Valori asimmetrici di Shapley
La soluzione di spiegazione del modello di previsione delle serie temporali SageMaker Clarify è un metodo di attribuzione delle funzionalità radicato nella teoria dei giochi cooperativi, simile nello spirito a SHAP.
Contesto
L’obiettivo è calcolare le attribuzioni per le funzionalità di input in un determinato modello di previsione f. Il modello di previsione accetta gli input seguenti:
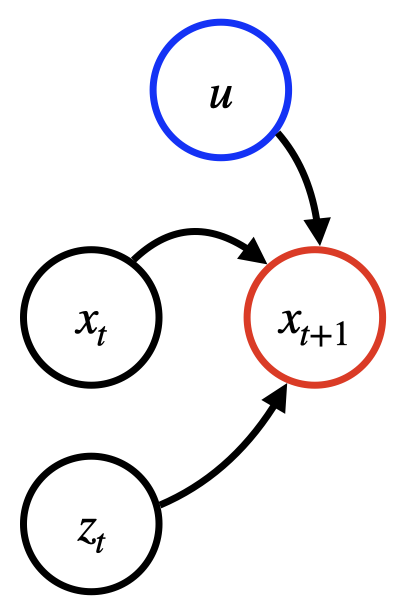
Serie temporali passate (TS di destinazione). Ad esempio, potrebbe trattarsi di passeggeri ferroviari che ogni giorno percorrevano il Paris-Berlin tragitto, indicati con x. t
(Facoltativo) Una serie temporale covariata. Ad esempio, potrebbe trattarsi di festività e dati meteorologici, indicati con zt ∈ RS. Se utilizzata, la TS covariata potrebbe essere disponibile solo per le fasi temporali passate oppure anche per quelle future (incluse nel calendario delle festività).
(Facoltativo) Le covariate statiche, ad esempio la qualità del servizio (ad esempio, prima o seconda classe), sono indicate da u ∈ RE.
Le covariate statiche, le covariate dinamiche o entrambe possono essere omesse, a seconda dello scenario applicativo specifico. Dato un orizzonte di previsione K ≥ 0 (ad esempio K = 30 giorni), la previsione tramite modello può essere caratterizzata dalla formula: f(x[1:T], z[1:T+K], u) = x[T+1:T +K+1].
Il diagramma seguente mostra una struttura delle dipendenze per un modello di previsione tipico. La previsione nel momento t+1 dipende dai tre tipi di input menzionati in precedenza.
Metodo
Le spiegazioni vengono calcolate eseguendo query sul modello delle serie temporali f su una serie di punti derivati dall’input originale. Seguendo i costrutti della teoria dei giochi, Clarify calcola la media delle differenze nelle previsioni dovute all’offuscamento (ovvero all’impostazione di un valore baseline) iterativo di parti degli input. La struttura temporale può essere esplorata in ordine cronologico, anticronologico o entrambi. Le spiegazioni cronologiche vengono create aggiungendo informazioni in modo iterativo dalla prima fase temporale, mentre per le spiegazioni anticronologiche si inizia dall’ultima fase. Quest’ultima modalità può essere più adatta per i bias di novità, ad esempio quando si prevedono i prezzi delle azioni. Una proprietà importante delle spiegazioni calcolate è che si sommano all’output del modello originale se il modello fornisce risultati deterministici.
Attribuzioni risultanti
Le attribuzioni risultanti sono punteggi che valutano i contributi individuali di specifiche fasi temporali o funzionalità di input alla previsione finale in ogni fase temporale prevista. Clarify offre le due granularità per le spiegazioni:
Le spiegazioni temporali non sono costose e forniscono informazioni mirate su fasi temporali specifiche, ad esempio in che misura le informazioni del 19° giorno nel passato hanno contribuito alla previsione del 1° giorno nel futuro. Queste attribuzioni non spiegano singolarmente le covariate statiche e le spiegazioni aggregate delle serie temporali di destinazione e covariate. Le attribuzioni sono una matrice A in cui ogni Atk è l’attribuzione della fase temporale t rispetto alla previsione della fase temporale T+k. Nota che se il modello accetta covariate future, t può essere maggiore di T.
Fine-grained le spiegazioni sono più impegnative dal punto di vista computazionale e forniscono una suddivisione completa di tutte le attribuzioni delle variabili di input.
Nota
Fine-grained le spiegazioni supportano solo l'ordine cronologico.
Le attribuzioni risultanti sono una tripletta composta da:
Matrice Ax ∈ RT×K relativa alla serie temporale di input, dove Atkx è l’attribuzione di xt rispetto alla fase di previsione T+k
Tensore Az ∈ RT+K×S×K relativo alla serie temporale covariata, dove Atskz è l’attribuzione di zts (ad esempio, la s° TS covariata) rispetto alla fase di previsione T+k
Matrice Au ∈ RE×K relativa alle covariate statiche, dove Aeku è l’attribuzione di ue (la covariata statica e°) rispetto alla fase di previsione T+k
Indipendentemente dalla granularità, la spiegazione contiene anche un vettore di offset B ∈ RK che rappresenta il “comportamento di base” del modello quando tutti i dati sono offuscati.
