Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Introduzione alla libreria di parallelismo dei dati distribuiti per l' SageMaker intelligenza artificiale
La libreria SageMaker AI distributed data parallelism (SMDDP) è una libreria di comunicazione collettiva che migliora le prestazioni di calcolo dell'addestramento parallelo di dati distribuiti. La libreria SMDDP risponde al sovraccarico di comunicazioni delle principali operazioni di comunicazione collettiva offrendo quanto segue.
-
La libreria offre offerte ottimizzate per.
AllReduceAWSAllReduceè un'operazione chiave utilizzata per sincronizzare i gradienti tra le GPU alla fine di ogni iterazione di addestramento durante l'addestramento distribuito dei dati. -
La libreria offre offerte ottimizzate per.
AllGatherAWSAllGatherè un'altra operazione chiave utilizzata nello sharded data parallel training, una tecnica di parallelismo dei dati efficiente in termini di memoria offerta da librerie popolari come la libreria SageMaker AI model parallelism (SMP), DeepSpeed Zero Redundancy Optimizer (Zero) e Fully Sharded Data Parallelism (FSDP). PyTorch -
La libreria esegue comunicazioni ottimizzate da nodo a nodo utilizzando appieno l'infrastruttura di AWS rete e la topologia dell'istanza Amazon EC2.
La libreria SMDDP può incrementare la velocità di addestramento offrendo un miglioramento delle prestazioni allo scalare del cluster di addestramento, con un’efficienza di dimensionamento quasi lineare.
Nota
Le librerie di formazione distribuite sull' SageMaker intelligenza artificiale sono disponibili tramite i contenitori di AWS deep learning PyTorch e Hugging Face all'interno della piattaforma Training. SageMaker Per utilizzare le librerie, è necessario utilizzare SageMaker Python SDK o le SageMaker API tramite SDK for Python (Boto3) o. AWS Command Line Interface In tutta la documentazione, le istruzioni e gli esempi si concentrano su come utilizzare le librerie di formazione distribuite con SageMaker Python SDK.
Operazioni di comunicazione collettiva SMDDP ottimizzate per AWS risorse di calcolo e infrastruttura di rete
La libreria SMDDP fornisce implementazioni AllReduce e operazioni AllGather collettive ottimizzate per le risorse di AWS calcolo e l'infrastruttura di rete.
Operazione collettiva AllReduce SMDDP
La libreria SMDDP consente una sovrapposizione ottimale dell’operazione AllReduce con il passaggio indietro, migliorando significativamente l’utilizzo della GPU. Raggiunge un’efficienza di dimensionamento quasi lineare e una maggiore velocità di addestramento ottimizzando le operazioni del kernel tra CPU e GPU. La libreria esegue AllReduce in parallelo mentre la GPU calcola i gradienti senza eliminare cicli della GPU aggiuntivi, consentendo alla libreria di conseguire un addestramento più rapido.
-
Utilizzo ottimale delle CPU: la libreria utilizza le CPU per eseguire
AllReducesui gradienti, liberando le GPU da questa attività. -
Utilizzo migliorato della GPU: le GPU del cluster si concentrano sui gradienti di calcolo, migliorandone l'utilizzo durante l'addestramento.
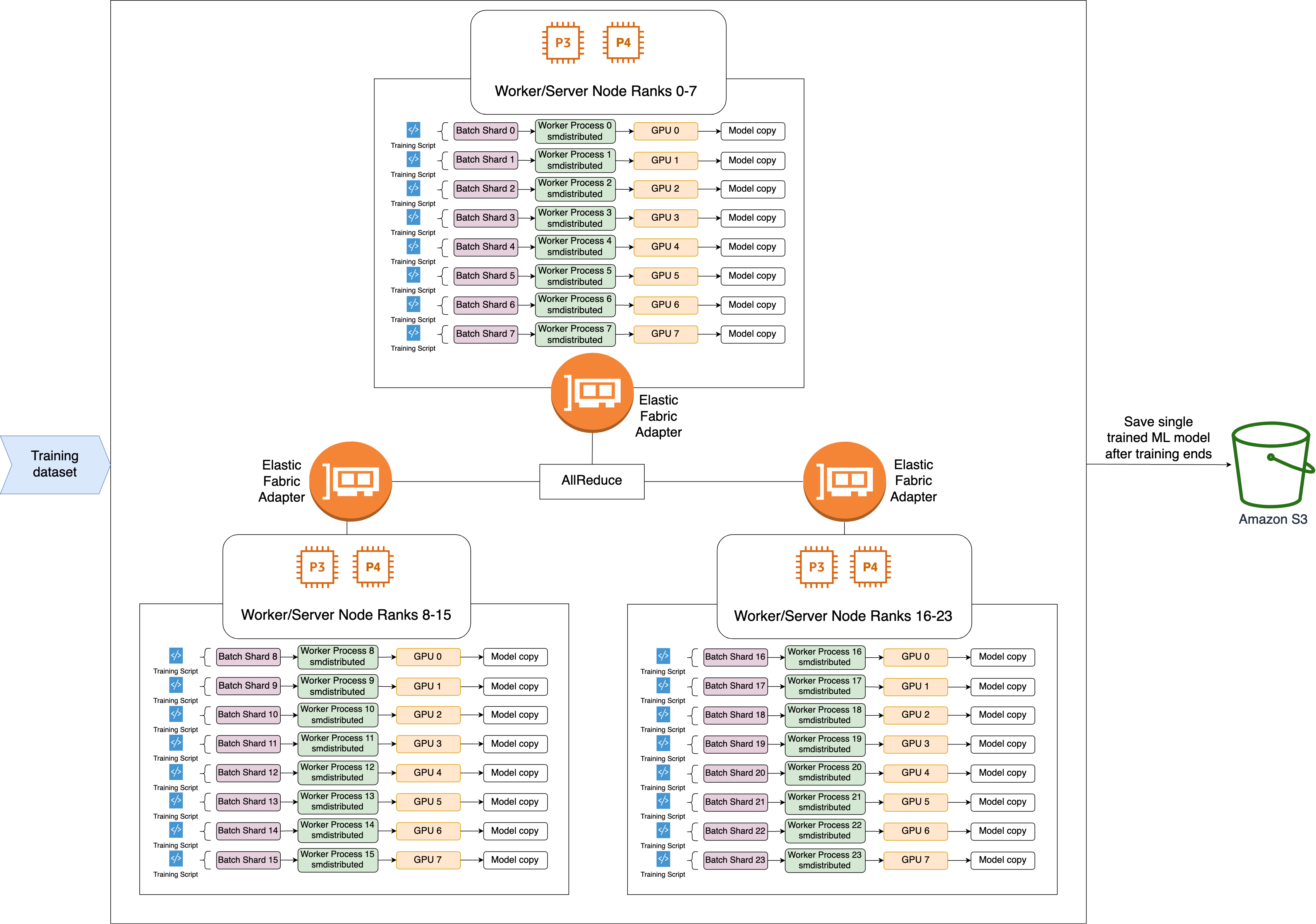
Di seguito è riportato il flusso di lavoro di alto livello dell’operazione AllReduce SMDDP.
-
La libreria assegna i ranghi alle GPU (worker).
-
Ad ogni iterazione, la libreria divide ogni batch globale per il numero totale di worker (dimensione mondiale) e assegna piccoli lotti (frammenti di batch) ai worker.
-
La dimensione del batch globale è
(number of nodes in a cluster) * (number of GPUs per node) * (per batch shard). -
Un batch shard (small batch) è un sottoinsieme di set di dati assegnato a ciascuna GPU (worker) per iterazione.
-
-
La libreria lancia uno script di addestramento per ogni worker.
-
La libreria gestisce le copie dei pesi e dei gradienti dei modelli fornite dai worker alla fine di ogni iterazione.
-
La libreria sincronizza i pesi e i gradienti dei modelli tra i worker per aggregare un unico modello addestrato.
Il seguente diagramma di architettura mostra un esempio di come la libreria imposta il parallelismo dei dati per un cluster di 3 nodi.
Operazione collettiva AllGather SMDDP
AllGather è un’operazione collettiva in cui ogni worker inizia con un buffer di input e quindi concatena o raccoglie i buffer di input di tutti gli altri worker in un buffer di output.
Nota
L'operazione AllGather collettiva SMDDP è disponibile in AWS Deep Learning Containers (DLC) per PyTorch la versione 2.0.1 smdistributed-dataparallel>=2.0.1 e successive.
L’operazione AllGather è ampiamente diffusa nelle tecniche di addestramento distribuito come la parallelizzazione dei dati con sharding, in cui ogni singolo worker detiene una frazione di un modello o un livello con sharding. I worker chiamano AllGather prima dei passaggi avanti e indietro per ricostruire i livelli con sharding. I passaggi avanti e indietro continuano dopo aver raccolto tutti i parametri. Durante il passaggio indietro, ogni worker chiama ReduceScatter anche per raccogliere (ridurre) i gradienti e suddividerli in shard di gradienti per aggiornare il livello con sharding corrispondente. Per maggiori dettagli sul ruolo di queste operazioni collettive nel parallelismo dei dati condivisi, consulta l'implementazione del parallelismo dei dati condivisi da parte della libreria SMP, Zero
Poiché le operazioni collettive AllGather vengono richiamate in ogni iterazione, sono le principali responsabili del sovraccarico di comunicazione con la GPU. Un calcolo più rapido di queste operazioni collettive si traduce direttamente in un tempo di addestramento più breve, senza effetti collaterali sulla convergenza. A tal fine, la libreria SMDDP offre operazioni AllGather ottimizzate per le istanze P4d
AllGather SMDDP utilizza le seguenti tecniche per migliorare le prestazioni di calcolo sulle istanze P4d.
-
Trasferisce dati tra istanze (tra nodi) tramite la rete Elastic Fabric Adapter (EFA)
con una topologia mesh. EFA è la soluzione di rete a AWS bassa latenza e ad alto throughput. Una topologia mesh per la comunicazione di rete tra nodi è più adatta alle caratteristiche dell'EFA e dell'infrastruttura di rete. AWS Rispetto alla topologia ad anello o ad albero di NCCL che prevede più hop di pacchetti, SMDDP evita l’accumulo di latenza da più hop, in quanto ne richiede solo uno. SMDDP implementa un algoritmo di controllo della velocità di rete che bilancia il carico di lavoro per ciascun peer di comunicazione in una topologia mesh e raggiunge un throughput di rete globale superiore. -
Adotta una libreria di copie di memoria GPU a bassa latenza basata sulla tecnologia NVIDIA GPUDirect RDMA (GDRCopy)
per coordinare il traffico di rete EFA e NVLink locale. GDRCopy, una libreria di copie di memoria GPU a bassa latenza offerta da NVIDIA, fornisce comunicazioni a bassa latenza tra i processi della CPU e i kernel CUDA della GPU. Con questa tecnologia, la libreria SMDDP è in grado di eseguire in pipeline lo spostamento dei dati all’interno dei nodi e tra un nodo e l’altro. -
Riduce l’utilizzo di multiprocessori di streaming sulla GPU per aumentare la potenza di calcolo per l’esecuzione dei kernel del modello. Le istanze P4d e P4de sono dotate di GPU NVIDIA A100, ognuna con 108 multiprocessori di streaming. Mentre NCCL impiega fino a 24 multiprocessori di streaming per eseguire operazioni collettive, SMDDP ne utilizza meno di 9. I kernel di calcolo dei modelli raccolgono i multiprocessori di streaming salvati per un calcolo più rapido.
