Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Panoramica dell'apprendimento automatico con Amazon SageMaker AI
Questa sezione descrive un tipico flusso di lavoro di machine learning (ML) e descrive come eseguire tali attività con Amazon SageMaker AI.
Con il machine learning, insegni a un computer a effettuare previsioni o eseguire inferenze. In primo luogo, utilizzi un algoritmo e i dati di esempio per addestrare un modello. Quindi integri il tuo modello nell’applicazione per generare inferenze in tempo reale e su qualsiasi scala.
Il seguente diagramma mostra il flusso di lavoro tipico per la creazione di un modello ML. Include tre fasi di un flusso circolare che tratteremo più dettagliatamente procedendo nel diagramma:
-
Generazione di dati di esempio
-
Addestramento di un modello
-
Implementazione del modello
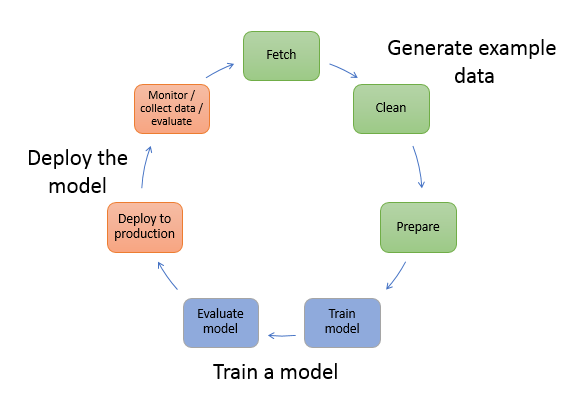
Il diagramma mostra come eseguire le seguenti attività negli scenari più comuni:
-
Generazione di dati di esempio - Per addestrare un modello, hai bisogno di dati di esempio. Il tipo di dati dei quali hai bisogno dipende dal problema di business che il modello deve risolvere. Si tratta essenzialmente delle inferenze che il modello deve generare. Ad esempio, immagina di voler creare un modello per prevedere un numero in base a un’immagine di input di una cifra scritta a mano. Per addestrare questo modello, hai bisogno di immagini di esempio di numeri scritti a mano.
I data scientist spesso dedicano tempo a esaminare e pre-elaborare dati di esempio prima di utilizzarli per l’addestramento dei modelli. Per pre-elaborare i dati, in genere devi eseguire le seguenti operazioni:
-
Recupero dei dati - Potresti avere internamente alcuni repository di dati di esempio oppure potresti utilizzare set di dati disponibili pubblicamente. In genere, estrai uno o più set di dati in un unico repository.
-
Pulizia dei dati - Per migliorare l’addestramento del modello, ispeziona i dati e puliscili in base alle esigenze. Ad esempio, se i tuoi dati hanno un attributo
country namecon valoriUnited StateseUS, puoi modificare i dati per mantenere coerenza. -
Preparazione o trasformazione dei dati - Per migliorare le prestazioni, puoi eseguire trasformazioni di dati aggiuntive. Ad esempio, potresti scegliere di combinare gli attributi per un modello che preveda le condizioni che richiedono la rimozione di ghiaccio da un aereo. Invece di utilizzare gli attributi di temperatura e umidità separatamente, puoi combinarli in un nuovo attributo per ottenere un modello migliore.
Nell' SageMaker intelligenza artificiale, puoi preelaborare dati di esempio utilizzando SageMaker API con SageMaker Python SDK
in un ambiente di sviluppo integrato (IDE). Con SDK per Python (Boto3) è possibile recuperare, esplorare e preparare i dati per l’addestramento dei modelli. Per informazioni sulla preparazione, sull’elaborazione e sulla trasformazione dei dati, consulta Consigli per scegliere il giusto strumento di preparazione dei dati nell' SageMaker intelligenza artificiale, Carichi di lavoro di trasformazione dei dati con Processing SageMaker e Creazione, archiviazione e condivisione di funzionalità con l’archivio delle caratteristiche. -
-
Addestramento di un modello - L’addestramento del modello comprende l’addestramento e la valutazione del modello, come segue:
-
Addestramento del modello - Per addestrare un modello, è necessario un algoritmo o un modello di base preaddestrato. L'algoritmo che scegli dipende da un numero di fattori. Per una soluzione integrata, puoi utilizzare uno degli algoritmi forniti. SageMaker Per un elenco degli algoritmi forniti da SageMaker e le relative considerazioni, vedere. Built-in algoritmi e modelli preaddestrati in Amazon SageMaker Per una soluzione UI-based di formazione che fornisce algoritmi e modelli, vedere. SageMaker JumpStart modelli preaddestrati
Hai bisogno di risorse di calcolo per l’addestramento. L’utilizzo delle risorse dipende dalle dimensioni del set di dati di addestramento e dai tempi entro cui servono i risultati. È possibile utilizzare diverse risorse, da una singola istanza per uso generico a un cluster distribuito di istanze di GPU. Per ulteriori informazioni, consulta Addestra un modello con Amazon SageMaker.
-
Valutazione del modello - Dopo aver addestrato il modello, valutalo per determinare se l’accuratezza delle inferenze è accettabile. Per addestrare e valutare il tuo modello, usa l'SDK SageMaker Python
per inviare richieste al modello per inferenze tramite uno degli IDE disponibili. Per ulteriori informazioni sulla valutazione di un modello, consulta Monitoraggio della qualità di dati e modelli con Amazon SageMaker Model Monitor.
-
-
Implementazione del modello - In genere si riprogetta un modello prima di integrarlo con l’applicazione e implementarlo. Con i servizi di hosting SageMaker AI, puoi implementare il tuo modello in modo indipendente, separandolo dal codice dell'applicazione. Per ulteriori informazioni, consulta Implementa modelli per l'inferenza.
Il machine learning è un ciclo continuo. Dopo l’implementazione di un modello, monitora le inferenze, raccogli più dati di alta qualità e valuta il modello per identificare eventuali derive. Quindi aumenta l’accuratezza delle inferenze aggiornando i tuoi dati di addestramento in modo che includano i nuovi dati di alta qualità raccolti. Con la disponibilità di maggiori quantità di dati di esempio, puoi ripetere l’addestramento del modello per aumentarne l’accuratezza.
