Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Generazione potenziata da recupero dati
I modelli di fondazione vengono generalmente addestrati offline, il che rende il modello indipendente dai dati creati dopo l'addestramento del modello. Inoltre, i modelli di fondazione vengono addestrati su corpora di dominio molto generici, il che li rende meno efficaci per le attività specifiche del dominio. È possibile utilizzare Retrieval Augmented Generation (RAG) per recuperare dati dall'esterno di un modello di fondazione e aumentare i prompt aggiungendo i dati recuperati pertinenti nel contesto. Per ulteriori informazioni sulle architetture dei modelli RAG, vedete Retrieval-Augmented Generation for NLP Tasks. Knowledge-Intensive
Con RAG, i dati esterni utilizzati per aumentare i prompt possono provenire da più fonti di dati, come archivi di documenti, database o API. La prima fase consiste nel convertire i documenti e le eventuali richieste degli utenti in un formato compatibile per eseguire ricerche pertinenti. Per rendere compatibili i formati, una raccolta di documenti o una libreria di conoscenze e le query inviate dall'utente vengono convertite in rappresentazioni numeriche mediante modelli linguistici incorporati. L'incorporamento è il processo mediante il quale al testo viene fornita una rappresentazione numerica in uno spazio vettoriale. Le architetture dei modelli RAG confrontano gli incorporamenti delle query degli utenti all'interno del vettore della libreria di conoscenze. Al prompt utente originale viene quindi aggiunto il contesto pertinente tratto da documenti simili presenti nella libreria di conoscenze. Questo prompt aumentato viene quindi inviato al modello di fondazione. È possibile aggiornare le librerie di conoscenze e i relativi incorporamenti in modo asincrono.
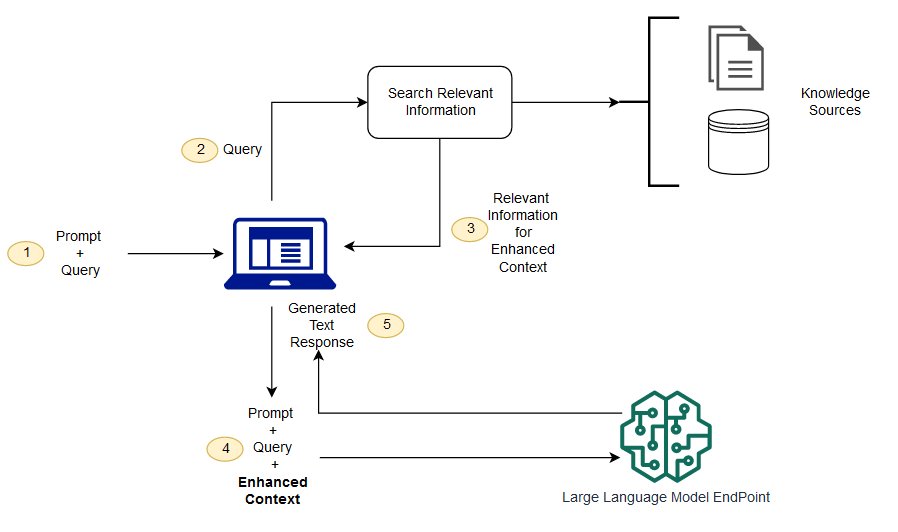
Il documento recuperato deve essere sufficientemente grande da contenere un contesto utile per potenziare il prompt, ma abbastanza piccolo da adattarsi alla lunghezza massima della sequenza del prompt. È possibile utilizzare JumpStart modelli specifici per le attività, come il modello General Text Embeddings (GTE) di, per fornire gli incorporamenti per i prompt e i documenti Hugging Face della Knowledge Library. Dopo aver confrontato gli embedding dei prompt e dei documenti per individuare i documenti più rilevanti, crea un nuovo prompt con il contesto supplementare. Quindi, passa il prompt potenziato a un modello di generazione di testo di tua scelta.
Notebook di esempio
Per ulteriori informazioni sulle soluzioni dei modelli di fondazione RAG, consulta i seguenti notebook di esempio:
Puoi clonare l'archivio degli esempi di Amazon SageMaker AI
