Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Configurazione di job di addestramento per accedere ai set di dati
Quando crei un job di addestramento, specifichi la posizione dei set di dati di addestramento in un archivio dati di tua scelta e la modalità di input dei dati per il job. Amazon SageMaker AI supporta Amazon Simple Storage Service (Amazon S3), Amazon Elastic File System (Amazon EFS) e Amazon FSx for Lustre. Puoi scegliere una delle modalità di input per trasmettere in streaming in tempo reale o scaricare l’intero set di dati all’inizio del job di addestramento.
Nota
Il set di dati deve risiedere nello stesso Regione AWS ambito del processo di formazione.
SageMaker Modalità di input AI e AWS opzioni di archiviazione cloud
Questa sezione fornisce una panoramica delle modalità di immissione dei file supportate da SageMaker per i dati archiviati in Amazon EFS e Amazon FSx for Lustre.
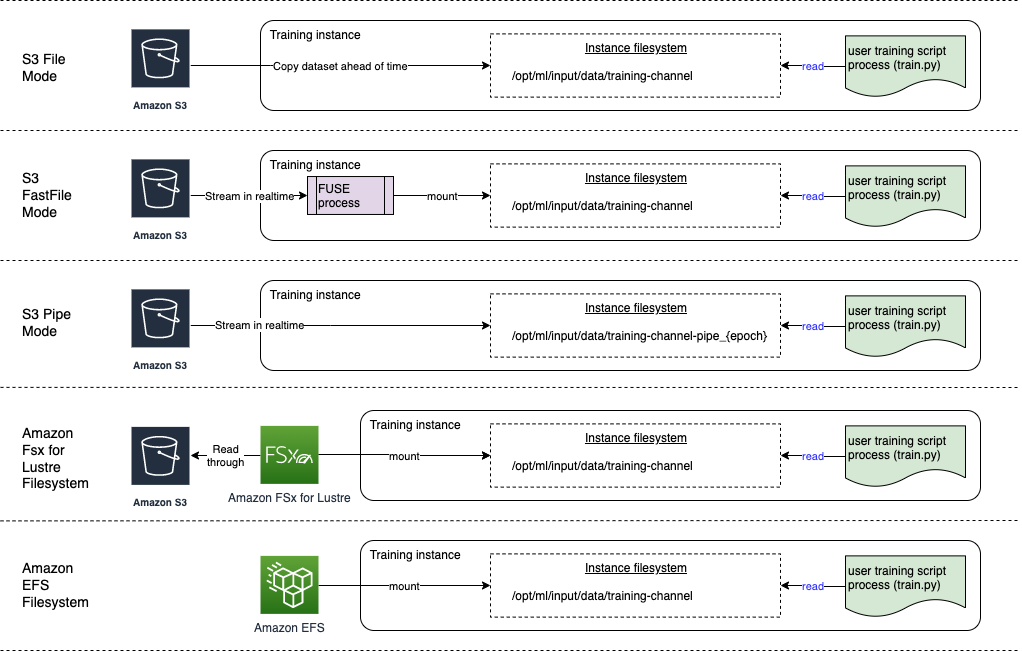
-
La modalità dei file presenta una vista del file system del set di dati nel container di addestramento. Questa è la modalità di input predefinita se non specifichi esplicitamente una delle altre due opzioni. Se utilizzi la modalità file, SageMaker AI scarica i dati di addestramento dalla posizione di archiviazione in una directory locale nel contenitore Docker. L’addestramento inizia dopo il download del set di dati completo. Nella modalità dei file, l'istanza di addestramento deve disporre di spazio di storage sufficiente per contenere l'intero set di dati. La velocità di download nella modalità dei file dipende dalle dimensioni del set di dati, dalle dimensioni medie dei file e dal numero di file. Puoi configurare il set di dati per la modalità dei file fornendo un prefisso Amazon S3, un file manifesto o un file manifesto aumentato. Devi utilizzare un prefisso S3 quando tutti i file del set di dati si trovano all'interno di un prefisso S3 comune. La modalità file è compatibile con la modalità locale SageMaker AI
(avvio interattivo di un contenitore di SageMaker formazione in pochi secondi). Per l'addestramento distribuito, puoi ripartire il set di dati su più istanze con l'opzione ShardedByS3Key. -
La modalità dei file veloce fornisce l'accesso al file system a un'origine dati Amazon S3 sfruttando al contempo il vantaggio prestazionale della modalità pipe. All'inizio dell'addestramento, la modalità dei file veloce identifica i file di dati, ma non li scarica. L'addestramento può iniziare senza attendere il download dell'intero set di dati. Ciò significa che l'avvio dell’addestramento richiede meno tempo quando ci sono meno file nel prefisso Amazon S3 fornito.
A differenza della modalità pipe, la modalità dei file veloce funziona con accesso casuale ai dati. Tuttavia, funziona meglio quando i dati vengono letti in sequenza. La modalità dei file veloce non supporta i file manifesto aumentati.
La modalità file veloce espone gli oggetti S3 utilizzando un'interfaccia di POSIX-compliant file system, come se i file fossero disponibili sul disco locale dell'istanza di addestramento. Trasmette in streaming i contenuti S3 on demand man mano che lo script di addestramento utilizza i dati. Ciò significa che non è più necessario che il set di dati si adatti allo spazio di archiviazione dell'istanza di addestramento nel suo complesso e non è necessario attendere che il set di dati venga scaricato sull'istanza di addestramento prima che abbia inizio l’addestramento. Attualmente la modalità dei file veloce supporta solo i prefissi S3 (non supporta file manifesto e manifesto aumentati). La modalità file veloce è compatibile con la modalità locale SageMaker AI.
Nota
L'utilizzo della modalità Fast File potrebbe comportare un aumento CloudTrail dei costi a causa della registrazione aggiuntiva di:
-
Eventi relativi ai dati di Amazon S3 (se abilitati). CloudTrail
-
AWS KMS eventi di decrittografia quando si accede a oggetti Amazon S3 crittografati con chiavi. AWS KMS
-
Eventi di gestione relativi alle operazioni. AWS KMS
Controlla i costi CloudTrail di configurazione e monitoraggio se hai abilitato CloudTrail la registrazione per questi tipi di eventi.
-
-
La modalità pipe trasmette in streaming i dati direttamente da un'origine dati Amazon S3. Lo streaming può fornire tempi di avvio più rapidi e un throughput migliore rispetto alla modalità dei file.
Quando esegui lo streaming diretto dei dati, puoi ridurre le dimensioni dei volumi Amazon EBS utilizzati dall'istanza di addestramento. La modalità Pipe richiede solo lo spazio su disco sufficiente per l'archiviazione degli artefatti del modello finale.
È un'altra modalità streaming che viene in gran parte sostituita dalla modalità dei file veloce più recente e più semplice da usare. In modalità pipe, i dati vengono prerecuperati da Amazon S3 con una velocità effettiva e simultanea elevati e trasmessi in streaming in una pipe denominata, nota anche come pipe (FIFO) per il suo First-In-First-Out comportamento. Ogni pipe può essere letta solo da un processo singolo. Un'estensione specifica per l' SageMaker intelligenza artificiale per integrare TensorFlow comodamente la modalità Pipe nel caricatore di TensorFlow dati nativo
per lo streaming di testo, TFRecords o ReCordio in formati di file ReCordio. La modalità pipe supporta anche il partizionamento e il mescolamento dei dati. -
Amazon S3 Express One Zone è una classe di storage a singola zona di disponibilità ad alte prestazioni in grado di fornire un accesso ai dati coerente a una cifra di millisecondi per le applicazioni più sensibili alla latenza, incluso il training dei modelli. SageMaker Amazon S3 Express One Zone consente ai clienti di collocare le proprie risorse di elaborazione e storage di oggetti in un'unica zona di AWS disponibilità, ottimizzando le prestazioni e i costi di elaborazione con una maggiore velocità di elaborazione dei dati. Per aumentare ulteriormente la velocità di accesso e supportare centinaia di migliaia di richieste al secondo, i dati vengono archiviati in un nuovo tipo di bucket, il bucket di directory Amazon S3.
SageMaker La formazione sui modelli AI supporta i bucket di directory Amazon S3 Express One Zone ad alte prestazioni come posizione di input dei dati per la modalità file, la modalità file veloce e la modalità pipe. Per utilizzare Amazon S3 Express One Zone, inserisci la posizione del bucket di directory Amazon S3 Express One Zone anziché un bucket Amazon S3. Fornisci l’ARN per il ruolo IAM con la policy di controllo degli accessi e delle autorizzazioni richiesta. Fare riferimento a AmazonSageMakerFullAccesspolicy per ulteriori dettagli. Puoi crittografare i dati di output SageMaker AI solo in bucket di directory con crittografia lato server con chiavi gestite di Amazon S3 (). SSE-S3 Server-side la crittografia con AWS KMS keys (SSE-KMS) non è attualmente supportata per la memorizzazione dei dati di output SageMaker AI in bucket di directory. Per ulteriori informazioni, consulta Amazon S3 Express One Zone.
-
Amazon FSx for Lustre: FSx for Lustre è scalabile fino a centinaia di gigabyte di throughput e milioni di IOPS con recupero di file a bassa latenza. Quando si avvia un processo di formazione, l' SageMaker intelligenza artificiale monta il file system FSx for Lustre sul file system dell'istanza di formazione, quindi avvia lo script di addestramento. Il montaggio stesso è un'operazione relativamente veloce che non dipende dalle dimensioni del set di dati archiviato in FSx for Lustre.
Per accedere a FSx for Lustre, il processo di formazione deve connettersi a un Amazon Virtual Private Cloud (VPC), che richiede configurazione DevOps e coinvolgimento. Per evitare costi di trasferimento dati, il file system utilizza una singola zona di disponibilità ed è necessario specificare una sottorete VPC mappata su questo ID zona di disponibilità durante l'esecuzione del processo di addestramento.
-
Amazon EFS: per utilizzare Amazon EFS come origine dati, i dati devono già risiedere in Amazon EFS prima della formazione. SageMaker L'intelligenza artificiale monta il file system Amazon EFS specificato sull'istanza di formazione, quindi avvia lo script di formazione. Il processo di addestramento deve connettersi a un VPC per accedere ad Amazon EFS.
Suggerimento
Per saperne di più su come specificare la configurazione del VPC per gli estimatori SageMaker AI, consulta Utilizzare i file system come input di addestramento
nella documentazione di AI SageMaker Python SDK.
