Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Concetti della parallelizzazione dei modelli
La parallelizzazione dei modelli è un metodo di addestramento distribuito in cui il modello di deep learning (DL) è partizionato su più dispositivi, all’interno o tra istanze. La SageMaker model parallel library v2 (SMP v2) è compatibile con le PyTorch API e le funzionalità native. In questo modo è facile adattare lo script di formazione PyTorch Fully Sharded Data Parallel (FSDP) alla piattaforma Training e sfruttare il miglioramento SageMaker delle prestazioni offerto da SMP v2. In questa pagina introduttiva sono disponibili una panoramica generale della parallelizzazione dei modelli e una descrizione di come questa può aiutare a superare i problemi che sorgono durante l’addestramento di modelli di deep learning (DL), che in genere sono di dimensioni molto grandi. Fornisce inoltre esempi di ciò che offre la libreria parallela del SageMaker modello per aiutare a gestire le strategie parallele dei modelli e il consumo di memoria.
Cos’è la parallelizzazione dei modelli?
L'aumento delle dimensioni dei modelli di deep learning (livelli e parametri) consente di ottenere una maggiore precisione per attività complesse come la visione artificiale e l'elaborazione del linguaggio naturale. Tuttavia, esiste un limite alla dimensione massima del modello che è possibile inserire nella memoria di una singola GPU. Durante l'addestramento dei modelli DL, le limitazioni della memoria della GPU possono rappresentare un ostacolo nei seguenti modi:
-
Limitano le dimensioni del modello che è possibile addestrare, poiché l’ingombro di memoria di un modello si ridimensiona proporzionalmente al numero di parametri.
-
Limitano la dimensione del batch per GPU durante l'addestramento, riducendo l'utilizzo della GPU e l'efficienza dell'addestramento.
Per superare i limiti associati all'addestramento di un modello su una singola GPU, l' SageMaker IA fornisce la libreria parallela di modelli per aiutare a distribuire e addestrare i modelli DL in modo efficiente su più nodi di calcolo. Inoltre, con la libreria, è possibile ottenere un addestramento distribuito ottimizzato utilizzando EFA-supported dispositivi, che migliorano le prestazioni della comunicazione tra nodi con bassa latenza, throughput elevato e bypass del sistema operativo.
Stima dei requisiti di memoria prima di utilizzare la parallelizzazione dei modelli
Prima di utilizzare la libreria SageMaker model parallel, considera quanto segue per avere un'idea dei requisiti di memoria necessari per l'addestramento di modelli DL di grandi dimensioni.
Per un job di addestramento che utilizza ottimizzatori con precisione mista automatica, come float16 (FP16) o bfloat16 (BF16) e Adam, la memoria GPU richiesta per parametro è di circa 20 byte, che possiamo suddividere come segue:
-
Un parametro FP16 o BF16 ~ 2 byte
-
Un gradiente FP16 o BF16 ~ 2 byte
-
Uno stato di ottimizzazione FP32 ~ 8 byte basato sugli ottimizzatori Adam
-
Una copia FP32 del parametro ~ 4 byte (necessaria per il funzionamento
optimizer apply(OA)) -
Una copia FP32 di gradiente ~ 4 byte (necessaria per il funzionamento OA)
Anche per un modello DL relativamente piccolo con 10 miliardi di parametri, può richiedere almeno 200 GB di memoria, che è molto più grande della tipica memoria GPU (ad esempio, NVIDIA A100 con 40GB/80GB memoria) disponibile su una singola GPU. Oltre ai requisiti di memoria per gli stati del modello e dell’ottimizzatore, occorre tenere in considerazione anche altri consumatori di memoria, come le attivazioni generate nel passaggio in avanti. La memoria richiesta può essere molto superiore a 200 GB.
Per l’addestramento distribuito, ti consigliamo di utilizzare istanze Amazon EC2 P4 e P5 con GPU NVIDIA A100 e H100 Tensor Core rispettivamente. Per ulteriori dettagli sulle specifiche quali core della CPU, RAM, volume di archiviazione collegato e larghezza di banda della rete, consulta la sezione Elaborazione accelerata nella pagina Tipi di istanze Amazon EC2
Anche con le istanze di elaborazione accelerata, i modelli con circa 10 miliardi di parametri come Megatron-LM T5 e i modelli ancora più grandi con centinaia di miliardi di parametri come GPT-3, non possono inserire repliche di modelli in ogni dispositivo GPU.
In che modo la libreria utilizza la parallelizzazione dei modelli e le tecniche di risparmio della memoria
La libreria comprende vari tipi di funzionalità di parallelismo dei modelli e funzionalità di risparmio di memoria come il partizionamento dello stato dell'ottimizzatore, il checkpoint di attivazione e l'offload dell'attivazione. Tutte queste tecniche possono essere combinate per addestrare in modo efficiente modelli di grandi dimensioni composti da centinaia di miliardi di parametri.
Argomenti
Parallelizzazione dei dati sottoposti a sharding
La parallelizzazione dei dati sottoposti a sharding è una tecnica di addestramento distribuito a risparmio di memoria che suddivide lo stato di un modello (parametri del modello, gradienti e stati dell’ottimizzatore) tra le GPU all’interno di un gruppo parallelo di dati.
Puoi applicare la parallelizzazione dei dati sottoposti a sharding al modello come strategia standalone. Inoltre, se utilizzi le istanze GPU più performanti dotate di GPU NVIDIA A100 Tensor Coreml.p4de.24xlarge, puoi sfruttare la maggiore velocità di formazione derivante dalle AllGather operazioni offerte dalla libreria SageMaker Data Parallelism (SMDDP). ml.p4d.24xlarge
Per approfondire la parallelizzazione dei dati sottoposti a sharding e imparare a configurarla o utilizzarla in combinazione con altre tecniche come la parallelizzazione tensoriale e l’addestramento di precisione misto, consulta Parallelizzazione dei dati sottoposti a sharding.
Parallelizzazione degli esperti
SMP v2 si integra con NVIDIA
Un modello MoE è un tipo di modello di trasformatore composto da più esperti, ciascuno costituito da una rete neurale, in genere una rete feed-forward (FFN). Una rete di porte chiamata router determina quali token vengono inviati a quale esperto. Gli esperti sono specializzati nell’elaborazione di aspetti specifici dei dati di input, per consentire un addestramento più rapido del modello e una riduzione dei costi di calcolo, ottenendo al contempo la stessa qualità delle prestazioni del modello ad alta densità equivalente. Inoltre, la parallelizzazione degli esperti è una tecnica di parallelizzazione che consente di suddividere gli esperti di un modello MoE tra dispositivi GPU.
Per informazioni su come addestrare i modelli MoE con SMP v2, consulta Parallelizzazione degli esperti.
Parallelizzazione tensoriale
La parallelizzazione tensoriale divide i singoli livelli, o nn.Modules, tra dispositivi, per essere eseguiti in parallelo. La figura seguente mostra l’esempio più semplice di come la libreria divide un modello con quattro livelli per ottenere una parallelizzazione tensoriale bidirezionale ("tensor_parallel_degree": 2). Nella figura seguente, le notazioni per il gruppo parallelo di modelli, il gruppo parallelo di tensori e il gruppo parallelo di dati sono MP_GROUP, TP_GROUP e DP_GROUP rispettivamente. I livelli di ogni replica del modello sono divisi in due e distribuiti in due GPU. La libreria gestisce la comunicazione tra le repliche del modello distribuite dai tensori.
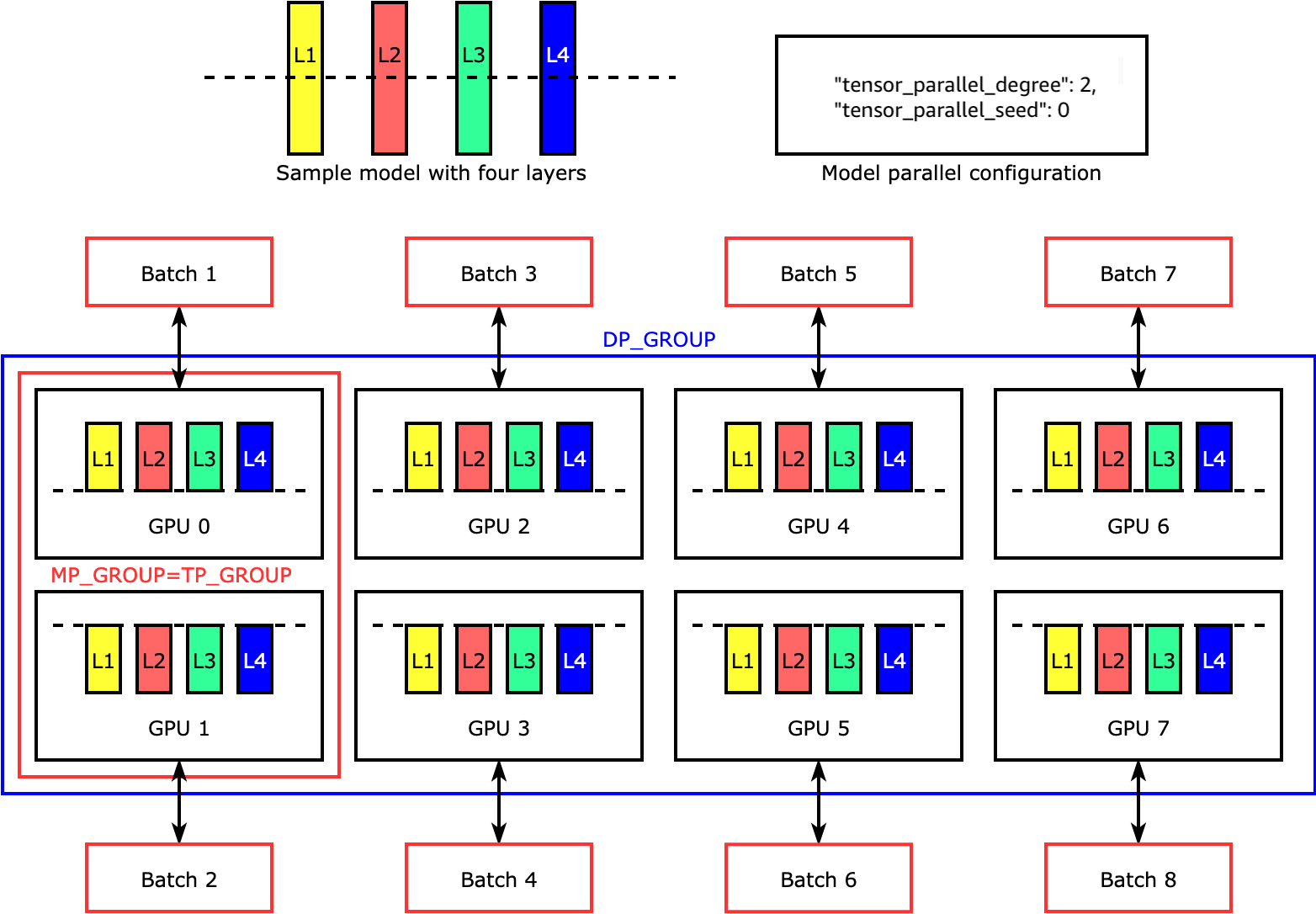
Per approfondire il parallelismo tensoriale e altre funzionalità di risparmio di memoria e per imparare a impostare una combinazione delle funzionalità principali PyTorch, consulta. Parallelizzazione tensoriale
Checkpoint e offload di attivazione
Per risparmiare memoria della GPU, la libreria supporta il checkpoint di attivazione per evitare di memorizzare le attivazioni interne nella memoria della GPU per i moduli specificati dall'utente durante il passaggio in avanti. La libreria ricalcola queste attivazioni durante il passaggio all'indietro. Inoltre, la funzione di offload dell’attivazione le consente di eseguire l’offload delle attivazioni archiviate nella memoria della CPU e recuperarle sulla GPU durante il passaggio all’indietro, in modo da ridurre ulteriormente l’ingombro della memoria di attivazione. Per ulteriori informazioni su come utilizzare queste funzionalità, consulta Checkpoint di attivazione e Offload di attivazione.
Scelta delle tecniche giuste per il modello
Per ulteriori informazioni sulla scelta delle tecniche e delle configurazioni corrette, consulta SageMaker best practice per il parallelismo dei modelli distribuiti.
