Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
# Implementazione di modelli per l’inferenza in tempo reale
**Importante**
Le politiche IAM personalizzate che consentono ad Amazon SageMaker Studio o Amazon SageMaker Studio Classic di creare SageMaker risorse Amazon devono inoltre concedere le autorizzazioni per aggiungere tag a tali risorse. L’autorizzazione per aggiungere tag alle risorse è necessaria perché Studio e Studio Classic applicano automaticamente tag a tutte le risorse che creano. Se una policy IAM consente a Studio e Studio Classic di creare risorse ma non consente l'etichettatura, possono verificarsi errori AccessDenied "" durante il tentativo di creare risorse. Per ulteriori informazioni, consulta [Fornisci le autorizzazioni per etichettare SageMaker le risorse AI](security_iam_id-based-policy-examples.md#grant-tagging-permissions).
[AWS politiche gestite per Amazon SageMaker AI](security-iam-awsmanpol.md)che danno i permessi per creare SageMaker risorse includono già le autorizzazioni per aggiungere tag durante la creazione di tali risorse.
Esistono diverse opzioni per implementare un modello utilizzando i servizi di hosting SageMaker AI. È possibile distribuire un modello in modo interattivo con Studio. SageMaker In alternativa, puoi distribuire un modello a livello di codice utilizzando un AWS SDK, come Python SDK o SDK for SageMaker Python (Boto3). È inoltre possibile eseguire la distribuzione utilizzando. AWS CLI
## Prima di iniziare
Prima di implementare un modello di SageMaker intelligenza artificiale, individua e prendi nota di quanto segue:
+ Regione AWS Dove si trova il tuo bucket Amazon S3
+ Il percorso URI Amazon S3 in cui sono archiviati gli artefatti del modello
+ Il ruolo di IAM per l'IA SageMaker
+ Il percorso del registro URI Docker Amazon ECR per l'immagine personalizzata che contiene il codice di inferenza o il framework e la versione di un'immagine Docker integrata supportata e da AWS
Per un elenco delle opzioni Servizi AWS disponibili in ciascuna di esse Regione AWS, consulta [Region Maps](https://aws.amazon.com/about-aws/global-infrastructure/regional-product-services/) and Edge Networks. Per ulteriori informazioni sulla creazione di un ruolo IAM, consultare [Creazione di ruoli IAM](https://docs.aws.amazon.com/IAM/latest/UserGuide/id_roles_create.html).
**Importante**
Il bucket Amazon S3 in cui sono archiviati gli artefatti del modello devono trovarsi nella stessa Regione AWS del modello che si sta creando.
## Utilizzo condiviso delle risorse con più modelli
Puoi distribuire uno o più modelli su un endpoint con Amazon SageMaker AI. Quando più modelli condividono un endpoint, utilizzano congiuntamente le risorse ivi ospitate, come le istanze di calcolo ML e gli acceleratori. CPUs Il modo più flessibile per implementare più modelli su un endpoint consiste nel definire ogni modello come *componente di inferenza*.
### Componenti di inferenza
Un componente di inferenza è un oggetto di hosting SageMaker AI che puoi utilizzare per distribuire un modello su un endpoint. Nelle impostazioni del componente di inferenza vengono specificati il modello, l’endpoint e il modo in cui il modello utilizza le risorse ospitate dall’endpoint. Per specificare il modello, puoi specificare un oggetto del modello SageMaker AI oppure puoi specificare direttamente gli artefatti e l'immagine del modello.
Nelle impostazioni è possibile ottimizzare l’utilizzo delle risorse personalizzando il modo in cui i core della CPU, gli acceleratori e la memoria richiesti vengono allocati al modello. È possibile implementare più componenti di inferenza in un endpoint, in cui ogni componente di inferenza contiene un modello e le relative esigenze di utilizzo delle risorse.
Dopo aver distribuito un componente di inferenza, è possibile richiamare direttamente il modello associato quando si utilizza l'azione nell' InvokeEndpoint API. SageMaker
I componenti di inferenza offrono i seguenti vantaggi:
**Flessibilità**
Il componente di inferenza disaccoppia i dettagli dell’hosting del modello dall’endpoint stesso. Ciò offre livelli superiori di flessibilità e controllo sul modo in cui i modelli vengono ospitati e serviti con un endpoint. È possibile ospitare più modelli sulla stessa infrastruttura e aggiungere o rimuovere modelli da un endpoint in base alle esigenze. È possibile aggiornare ogni modello in modo indipendente.
**Scalabilità**
È possibile specificare il numero di copie di ciascun modello da ospitare e impostare un numero minimo di copie per garantire che il modello venga caricato nella quantità necessaria per soddisfare le richieste. È possibile scalare qualsiasi copia di un componente di inferenza fino a zero, lasciando spazio a un’altra copia da aumentare verticalmente.
SageMaker L'intelligenza artificiale impacchetta i tuoi modelli come componenti di inferenza quando li distribuisci utilizzando:
+ SageMaker Studio Classic.
+ L'SDK SageMaker Python per distribuire un oggetto Model (dove si imposta il tipo di endpoint su). `EndpointType.INFERENCE_COMPONENT_BASED`
+ Gli `InferenceComponent` oggetti AWS SDK per Python (Boto3) per definire che si distribuiscono su un endpoint.
## Distribuisci modelli con Studio SageMaker
Completa i seguenti passaggi per creare e distribuire il modello in modo interattivo tramite Studio. SageMaker Per ulteriori informazioni, consulta la documentazione di [Studio](https://docs.aws.amazon.com/sagemaker/latest/dg/studio.html). Per ulteriori informazioni dettagliate sui vari scenari di implementazione, consulta il blog [Package e distribuisci modelli ML classici e in modo semplice LLMs con Amazon SageMaker AI](https://aws.amazon.com/blogs/machine-learning/package-and-deploy-classical-ml-and-llms-easily-with-amazon-sagemaker-part-2-interactive-user-experiences-in-sagemaker-studio/) — Parte 2.
### Preparare gli artefatti e le autorizzazioni
Completa questa sezione prima di creare un modello in Studio. SageMaker
Hai due opzioni per utilizzare artefatti personalizzati e creare un modello in Studio:
1. Puoi utilizzare un archivio `tar.gz` personale preconfezionato, che deve includere gli artefatti del modello, eventuale codice di inferenza personalizzato e tutte le dipendenze elencate in un file `requirements.txt`.
1. SageMaker L'intelligenza artificiale può impacchettare i tuoi artefatti per te. Devi solo inserire gli artefatti del modello grezzo e le eventuali dipendenze in un `requirements.txt` file e l' SageMaker intelligenza artificiale può fornirti il codice di inferenza predefinito (oppure puoi sovrascrivere il codice predefinito con il tuo codice di inferenza personalizzato). SageMaker L'IA supporta questa opzione per i seguenti framework:,. PyTorch XGBoost
Oltre a fornire il modello, il ruolo AWS Identity and Access Management (IAM) e un contenitore Docker (o il framework e la versione desiderati per i quali SageMaker AI dispone di un contenitore predefinito), devi anche concedere le autorizzazioni per creare e distribuire modelli tramite AI Studio. SageMaker
Dovresti avere la [AmazonSageMakerFullAccess](https://docs.aws.amazon.com/aws-managed-policy/latest/reference/AmazonSageMakerFullAccess.html)policy associata al tuo ruolo IAM in modo da poter accedere all' SageMaker intelligenza artificiale e ad altri servizi pertinenti. Per vedere i prezzi dei tipi di istanze in Studio, devi anche allegare la [AWS PriceListServiceFullAccess](https://docs.aws.amazon.com/aws-managed-policy/latest/reference/AWSPriceListServiceFullAccess.html)policy (o, se non vuoi allegare l'intera policy, più specificamente, l'`pricing:GetProducts`azione).
Per caricare gli artefatti del modello durante la creazione di un modello (o caricare un file di payload di esempio per i consigli di inferenza), è necessario creare un bucket Amazon S3. Il nome del bucket deve essere preceduto dalla parola `SageMaker AI`. Sono accettabili anche le capitalizzazioni alternative dell' SageMaker IA: `Sagemaker` o. `sagemaker`
È consigliabile utilizzare la convenzione di denominazione dei bucket `sagemaker-{{{Region}}}-{{{accountID}}}`. Questo bucket viene utilizzato per archiviare gli artefatti caricati.
Dopo aver creato il bucket, collega la seguente policy CORS (Cross-Origin Resource Sharing) al bucket:
```
[
{
"AllowedHeaders": ["*"],
"ExposeHeaders": ["Etag"],
"AllowedMethods": ["PUT", "POST"],
"AllowedOrigins": ['https://*.sagemaker.aws'],
}
]
```
Puoi collegare una policy CORS a un bucket Amazon S3 utilizzando uno dei seguenti metodi:
+ tramite la pagina [Modifica la condivisione delle risorse multiorigine (CORS)](https://s3.console.aws.amazon.com/s3/bucket/bucket-name/property/cors/edit) nella console di Amazon S3;
+ Utilizzo dell'API Amazon S3 [PutBucketCors](https://docs.aws.amazon.com/AmazonS3/latest/API/API_PutBucketCors.html)
+ Utilizzando il put-bucket-cors AWS CLI comando:
```
aws s3api put-bucket-cors --bucket="..." --cors-configuration="..."
```
### Creare un modello implementabile
In questo passaggio, creerai una versione implementabile del tuo modello in SageMaker AI fornendo gli artefatti insieme a specifiche aggiuntive, come il contenitore e il framework desiderati, qualsiasi codice di inferenza personalizzato e le impostazioni di rete.
Crea un modello distribuibile in Studio effettuando le seguenti operazioni: SageMaker
1. Apri l'applicazione SageMaker Studio.
1. Nel riquadro di navigazione a sinistra scegliere **Models (Modelli)**.
1. Scegli la scheda **Modelli implementabili**.
1. Nella pagina **Modelli implementabili**, scegli **Crea**.
1. Nella pagina **Crea modello implementabile**, nel campo **Nome modello**, inserisci un nome per il modello.
Sono presenti altre sezioni da compilare nella pagina **Crea modello implementabile**.
La sezione **Definizione di container** ha l’aspetto del seguente screenshot:
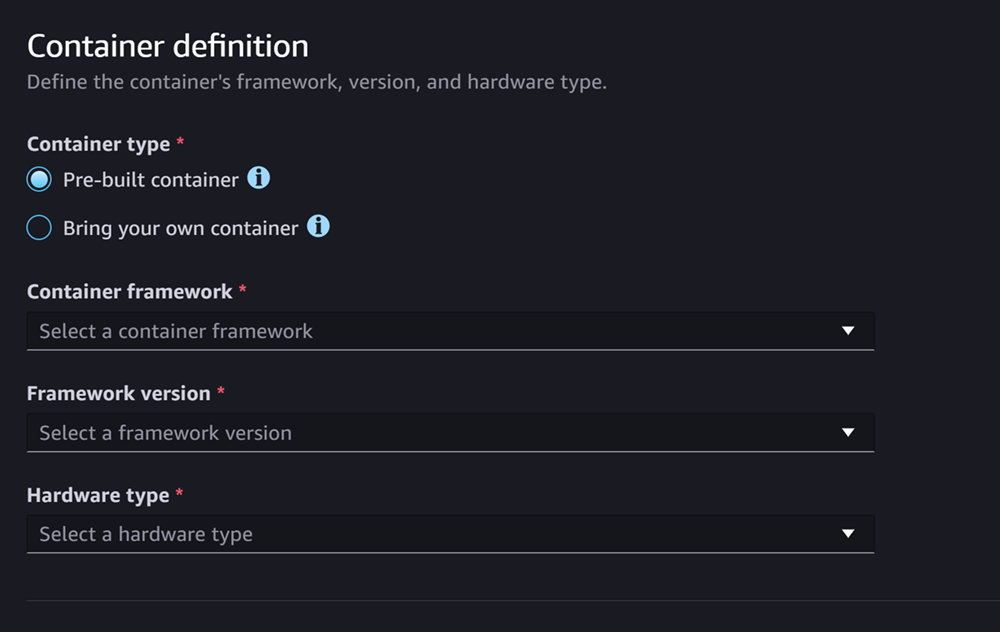
**Per la sezione **Definizione di container** segui questa procedura:**
1. Per **Tipo di contenitore**, seleziona **Contenitore precostruito** se desideri utilizzare un contenitore gestito dall' SageMaker intelligenza artificiale oppure seleziona **Bring your own container** se hai il tuo contenitore.
1. Se hai selezionato **Container predefinito**, seleziona i valori di **Framework del container**, **Versione del framework** e **Tipo di hardware** che desideri utilizzare.
1. Se hai selezionato **Porta il tuo container**, inserisci un percorso Amazon ECR per **Percorso ECR a immagine container**.
Quindi, compila la sezione **Artefatti**, simile al seguente screenshot:

**Per la sezione **Artefatti** segui questa procedura:**
1. **Se utilizzi uno dei framework supportati dall' SageMaker intelligenza artificiale per il packaging degli artefatti del modello (PyTorch o XGBoost), allora per Artifacts, puoi scegliere l'**opzione Carica artefatti**.** Con questa opzione, puoi semplicemente specificare gli artefatti del modello non elaborato, qualsiasi codice di inferenza personalizzato in tuo possesso e il tuo file requirements.txt, e AI gestirà l'imballaggio dell'archivio per te. SageMaker Esegui questa operazione:
1. Per **Artefatti**, seleziona **Carica artefatti** per continuare a fornire i file. Altrimenti, se disponi già di un archivio `tar.gz` che contiene i file del modello, il codice di inferenza e il file `requirements.txt`, seleziona **Inserisci URI S3 per pacchetti di artefatti**.
1. Se hai scelto di caricare i tuoi artefatti, per il bucket **S3, inserisci il percorso Amazon S3 verso un bucket** in cui desideri che l' SageMaker intelligenza artificiale memorizzi i tuoi artefatti dopo averli imballati per te. Quindi, completa questa procedura.
1. Per **Carica artefatti modello**, carica i file del modello.
1. Per il codice di **inferenza, seleziona Usa il codice** **di inferenza predefinito se desideri utilizzare il codice** predefinito fornito dall'intelligenza artificiale per fornire l'inferenza. SageMaker Altrimenti, seleziona **Carica codice di inferenza personalizzato** per utilizzare un codice di inferenza personalizzato.
1. Per **Carica requirements.txt**, carica un file di testo che elenchi tutte le dipendenze da installare in fase di esecuzione.
1. Se non utilizzi un framework supportato dall' SageMaker intelligenza artificiale per il packaging degli artefatti del modello, Studio ti mostra l'opzione Artefatti **preconfezionati e devi fornire tutti gli artefatti** già impacchettati come archivio. `tar.gz` Esegui questa operazione:
1. Per **Pacchetti di artefatti**, seleziona **Inserisci URI S3 per pacchetti di artefatti del modello** se l’archivio `tar.gz` è già stato caricato in Amazon S3. Seleziona **Carica artefatti del modello preconfezionati** se desideri caricare direttamente l'archivio su AI. SageMaker
1. Se hai selezionato **Inserisci URI S3 per pacchetti di artefatti del modello**, inserisci il percorso Amazon S3 dell’archivio per l’**URI S3**. Altrimenti, seleziona e carica l’archivio dal tuo computer locale.
La sezione successiva è **Sicurezza**, simile allo screenshot seguente:
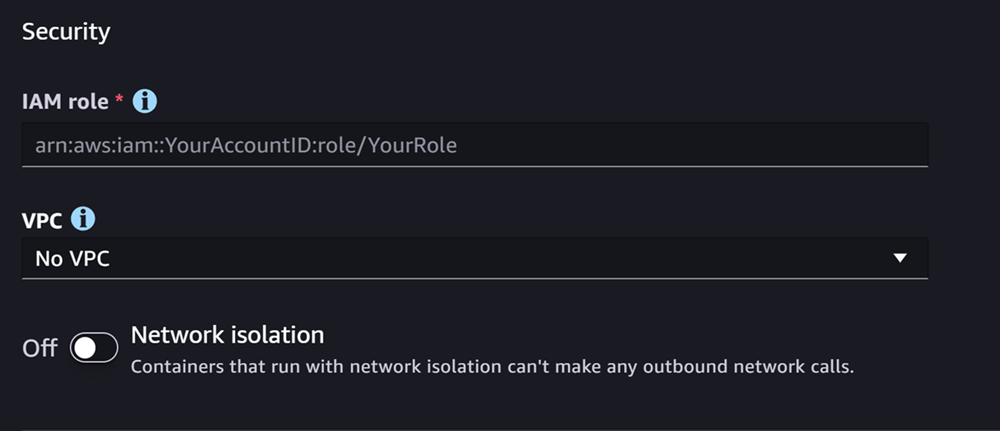
**Per la sezione **Sicurezza**, segui questa procedura:**
1. Per **Ruolo IAM**, inserisci l’ARN per un ruolo IAM.
1. (Facoltativo) Per **Cloud privato virtuale (VPC)**, puoi selezionare un Amazon VPC per archiviare la configurazione e gli artefatti del modello.
1. (Facoltativo) Attiva l’interruttore **Isolamento di rete** per limitare l’accesso a Internet del container.
Infine, è possibile facoltativamente compilare la sezione **Opzioni avanzate**, simile al seguente screenshot:
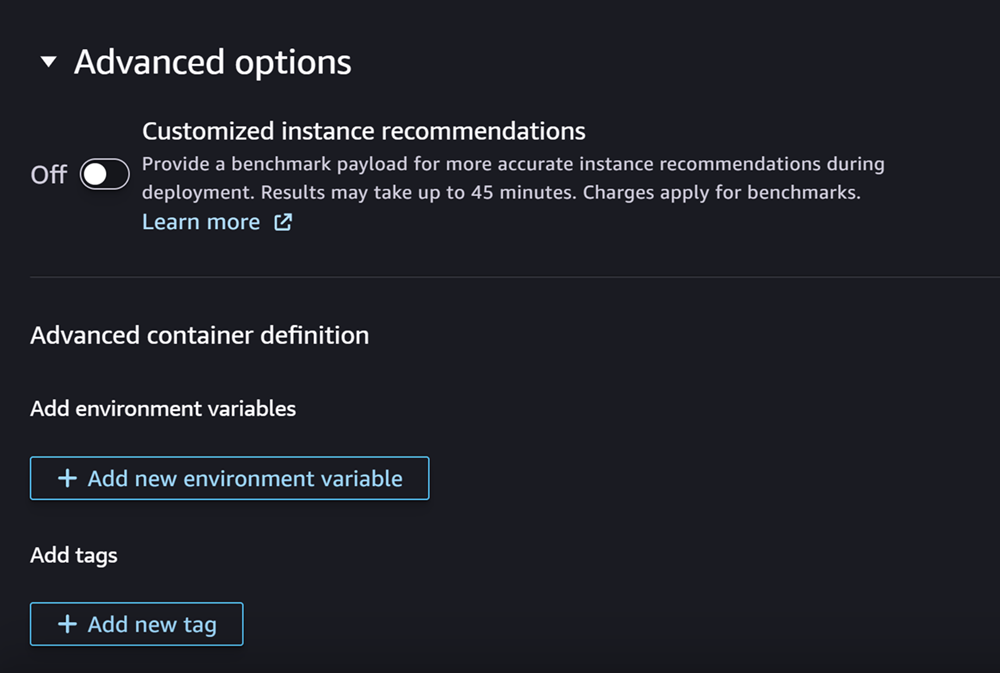
**(Facoltativo) Per la sezione **Opzioni avanzate** segui questa procedura:**
1. Attiva l'opzione **Consigli di istanze personalizzate** se desideri eseguire un job Amazon SageMaker Inference Recommender sul tuo modello dopo la sua creazione. Inference Recommender è una funzionalità che fornisce tipi di istanze consigliati per ottimizzare le prestazioni e i costi dell’inferenza. È possibile visualizzare questi consigli sulle istanze durante la preparazione all’implementazione del modello.
1. Per **Aggiungi variabili di ambiente**, inserisci una variabile di ambiente per il container come coppie chiave-valore.
1. Per **Tag**, inserisci i tag come coppie chiave-valore.
1. Dopo aver completato la configurazione del modello e del container, scegli **Crea modello implementabile**.
Ora dovresti avere un modello in SageMaker Studio pronto per la distribuzione.
### Distribuzione del modello
Infine, è possibile implementare il modello configurato nella fase precedente in un endpoint HTTPS. È possibile implementare un singolo modello o più modelli sull’endpoint.
**Compatibilità tra modelli ed endpoint**
Prima di poter implementare un modello in un endpoint, è necessario che il modello e l’endpoint siano compatibili e abbiano gli stessi valori per le seguenti impostazioni:
Ruolo IAM
Amazon VPC, comprese le sottoreti e i gruppi di sicurezza
Isolamento di rete (abilitato o disabilitato)
Studio impedisce di implementare modelli in endpoint incompatibili nei seguenti modi:
Se tenti di implementare un modello su un nuovo endpoint, SageMaker AI configura l'endpoint con impostazioni iniziali compatibili. Se interrompi la compatibilità modificando queste impostazioni, Studio mostra un avviso e impedisce l’implementazione.
Se tenti di eseguire l’implementazione in un endpoint esistente e tale endpoint è incompatibile, Studio mostra un avviso e impedisce l’implementazione.
Se si tenta di aggiungere più modelli a un’implementazione, Studio impedisce di implementare i modelli incompatibili tra loro.
Quando Studio mostra l’avviso sull’incompatibilità tra modello ed endpoint, è possibile scegliere **Visualizza dettagli** nell’avviso per vedere quali impostazioni sono incompatibili.
Un modo per implementare un modello consiste nel seguire questa procedura in Studio:
1. Apri l'applicazione Studio. SageMaker
1. Nel riquadro di navigazione a sinistra scegliere **Models (Modelli)**.
1. Nella pagina **Modelli**, seleziona uno o più modelli dall'elenco dei modelli SageMaker AI.
1. Seleziona **Implementa**.
1. Per **Nome endpoint**, apri il menu a discesa. È possibile selezionare un endpoint esistente oppure creare un nuovo endpoint in cui implementare il modello.
1. Per **Tipo di istanza**, seleziona il tipo di istanza da utilizzare per l’endpoint. Se in precedenza hai eseguito un processo Inference Recommender per il modello, i tipi di istanza consigliati vengono visualizzati nell’elenco sotto il titolo **Consigliato**. Altrimenti, vedrai alcune **istanze potenziali** che potrebbero essere adatte al tuo modello.
**Compatibilità del tipo di istanza per JumpStart**
Se stai distribuendo un JumpStart modello, Studio mostra solo i tipi di istanza supportati dal modello.
1. Per **Conteggio istanze iniziale**, inserisci il numero iniziale di istanze che desideri fornire per il tuo endpoint.
1. Per **Numero massimo di istanze**, specifica il numero massimo di istanze che l’endpoint può fornire in caso di aumento verticale per far fronte a un incremento di traffico.
1. Se il modello che stai distribuendo è uno dei più utilizzati JumpStart LLMs dal Model Hub, l'opzione **Configurazioni alternative** viene visualizzata dopo i campi Tipo di istanza e Numero di istanze.
Per le più diffuse JumpStart LLMs, AWS dispone di tipi di istanze pre-confrontati per ottimizzarne i costi o le prestazioni. Questi dati possono aiutarti a decidere quale tipo di istanza utilizzare per implementare il tuo LLM. Scegli **Configurazioni alternative** per aprire una finestra di dialogo che contiene i dati prevalutati. Il pannello ha un aspetto simile al seguente screenshot:
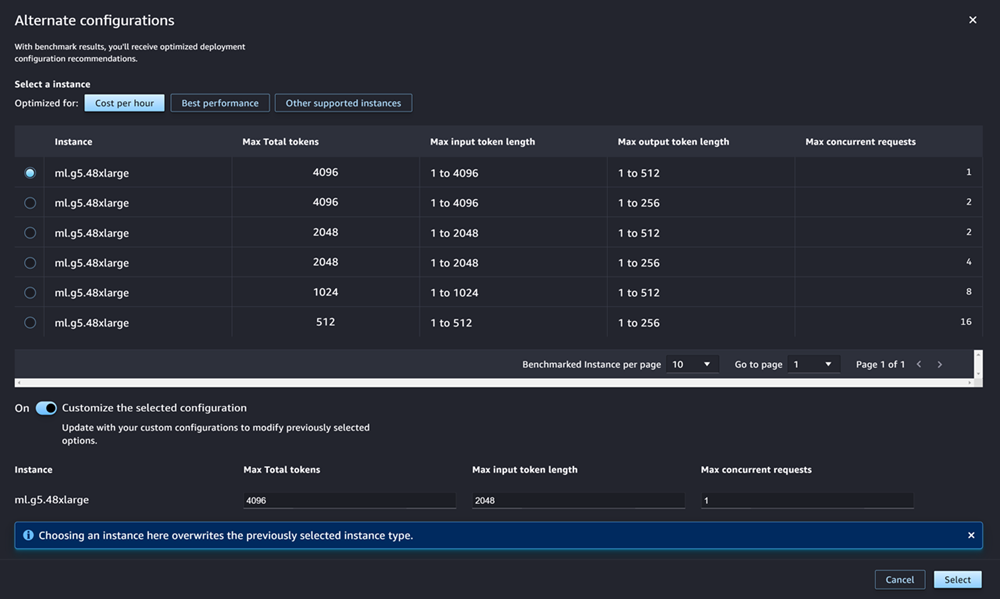
Nella casella **Configurazioni alternative**, segui questa procedura:
1. Selezione di un tipo di istanza. Puoi scegliere **Costo all’ora** o **Prestazioni ottimali** per visualizzare i tipi di istanze che ottimizzano i costi o le prestazioni per il modello specificato. Puoi anche scegliere **Altre istanze supportate** per visualizzare un elenco di altri tipi di istanze compatibili con il modello. JumpStart La selezione di un tipo di istanza qui sovrascrive qualsiasi selezione di istanza precedente specificata nella fase 6.
1. (Facoltativo) Attiva l’interruttore **Personalizza la configurazione selezionata** per specificare i valori di **Numero massimo di token totali** (il numero massimo di token che desideri consentire, ovvero la somma dei token di input e dell’output generato dal modello), **Lunghezza massima di token per input** (il numero massimo di token che desideri consentire per l’input di ogni richiesta) e **Numero massimo di richieste simultanee** (il numero massimo di richieste che il modello può elaborare simultaneamente).
1. Scegli **Seleziona** per confermare il tipo di istanza e le impostazioni di configurazione.
1. Il campo **Modello** dovrebbe già essere compilato con il nome del modello o dei modelli che stai implementando. Puoi scegliere **Aggiungi modello** per aggiungere altri modelli all’implementazione. Per ogni modello aggiunto, compila i seguenti campi:
1. Per **Numero di core CPU**, inserisci i core CPU che desideri dedicare all’utilizzo del modello.
1. Per **Numero minimo di copie**, inserisci il numero minimo di copie del modello che desideri ospitare sull’endpoint in un dato momento.
1. Per **Memoria CPU minima (MB)**, inserisci la quantità minima di memoria (in MB) richiesta dal modello.
1. Per **Memoria CPU massima (MB)**, inserisci la quantità massima di memoria (in MB) che desideri consentire al modello di utilizzare.
1. (Facoltativo) Per **Opzioni avanzate**, segui questa procedura:
1. Per il **ruolo IAM**, utilizza il ruolo di esecuzione IAM SageMaker AI predefinito o specifica il tuo ruolo con le autorizzazioni necessarie. Questo ruolo IAM deve essere lo stesso del ruolo specificato durante la creazione del modello implementabile.
1. Per **Cloud privato virtuale (VPC)**, puoi specificare un VPC in cui ospitare l’endpoint.
1. Per la **chiave Encryption KMS**, seleziona una AWS KMS chiave per crittografare i dati sul volume di storage collegato all'istanza di calcolo ML che ospita l'endpoint.
1. Attiva l’interruttore **Abilita l’isolamento di rete** per limitare l’accesso a Internet del container.
1. Per la **Configurazione del timeout**, inserisci i valori per i campi **Timeout per il download dei dati del modello (secondi)** e **Timeout per il controllo dell’integrità di avvio del container (secondi)**. Questi valori determinano rispettivamente il tempo massimo consentito dall' SageMaker intelligenza artificiale per scaricare il modello nel contenitore e avviare il contenitore.
1. Per **Tag**, inserisci i tag come coppie chiave-valore.
**Nota**
SageMaker L'intelligenza artificiale configura il ruolo IAM, il VPC e le impostazioni di isolamento della rete con valori iniziali compatibili con il modello che stai implementando. Se interrompi la compatibilità modificando queste impostazioni, Studio mostra un avviso e impedisce l’implementazione.
Dopo aver configurato le opzioni, la pagina sarà simile allo screenshot seguente.
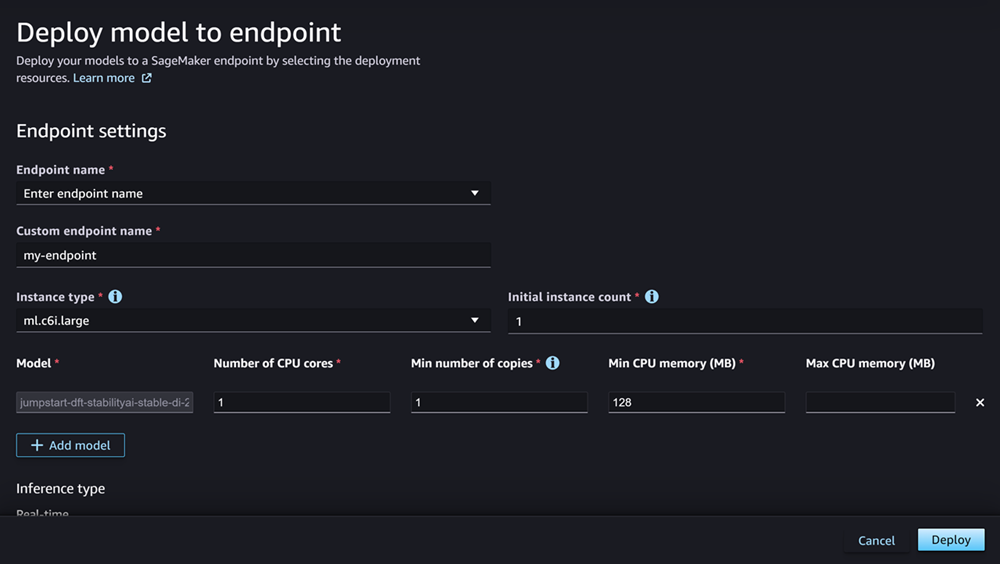
Dopo aver configurato l’implementazione, scegli **Implementa** per creare l’endpoint e implementare il modello.
## Implementa modelli con Python SDKs
Utilizzando SageMaker Python SDK, puoi creare il tuo modello in due modi. Il primo consiste nel creare un oggetto di modello dalla classe `Model` oppure `ModelBuilder`. In caso di utilizzo della classe `Model` per creare un oggetto `Model`, è necessario specificare il pacchetto del modello o il codice di inferenza (a seconda del server del modello), gli script per gestire la serializzazione e la deserializzazione dei dati tra il client e il server ed eventuali dipendenze da caricare su Amazon S3 per il consumo. Il secondo modo per creare il modello consiste nell’utilizzare `ModelBuilder` per cui fornire artefatti del modello o codice di inferenza. `ModelBuilder` acquisisce automaticamente le dipendenze, deduce le funzioni di serializzazione e deserializzazione necessarie e genera un pacchetto delle dipendenze per creare l’oggetto `Model`. Per ulteriori informazioni su `ModelBuilder`, consultare [Crea un modello in Amazon SageMaker AI con ModelBuilder](how-it-works-modelbuilder-creation.md).
La sezione seguente descrive entrambi i metodi per creare il modello e implementare l’oggetto di modello.
### Configurazione
Gli esempi seguenti preparano il processo di implementazione del modello. Importano le librerie necessarie e definiscono l’URL S3 che individua gli artefatti del modello.
------
#### [ SageMaker Python SDK ]
**Example istruzioni di importazione**
L'esempio seguente importa moduli da SageMaker Python SDK, SDK for Python (Boto3) e Python Standard Library. Questi moduli forniscono metodi utili per implementare i modelli e vengono utilizzati negli altri esempi che seguono.
```
import boto3
from datetime import datetime
from sagemaker.compute_resource_requirements.resource_requirements import ResourceRequirements
from sagemaker.predictor import Predictor
from sagemaker.enums import EndpointType
from sagemaker.model import Model
from sagemaker.session import Session
```
------
#### [ boto3 inference components ]
**Example istruzioni di importazione**
L’esempio seguente importa moduli da SDK per Python (Boto3) e Python Standard Library. Questi moduli forniscono metodi utili per implementare i modelli e vengono utilizzati negli altri esempi che seguono.
```
import boto3
import botocore
import sys
import time
```
------
#### [ boto3 models (without inference components) ]
**Example istruzioni di importazione**
L’esempio seguente importa moduli da SDK per Python (Boto3) e Python Standard Library. Questi moduli forniscono metodi utili per implementare i modelli e vengono utilizzati negli altri esempi che seguono.
```
import boto3
import botocore
import datetime
from time import gmtime, strftime
```
------
**Example URL degli artefatti del modello**
Il codice seguente crea un esempio di URL Amazon S3. L’URL individua gli artefatti di un modello preaddestrato in un bucket Amazon S3.
```
# Create a variable w/ the model S3 URL
# The name of your S3 bucket:
s3_bucket = "amzn-s3-demo-bucket"
# The directory within your S3 bucket your model is stored in:
bucket_prefix = "{{sagemaker/model/path}}"
# The file name of your model artifact:
model_filename = "{{my-model-artifact.tar.gz}}"
# Relative S3 path:
model_s3_key = f"{bucket_prefix}/"+model_filename
# Combine bucket name, model file name, and relate S3 path to create S3 model URL:
model_url = f"s3://{s3_bucket}/{model_s3_key}"
```
L’URL Amazon S3 completo è archiviato nella variabile `model_url`, utilizzata negli esempi seguenti.
### Panoramica di
Esistono diversi modi per distribuire modelli con Python SDK o SDK for SageMaker Python (Boto3). Le sezioni seguenti riepilogano le fasi da completare per diversi approcci possibili. Queste fasi sono illustrate negli esempi che seguono.
------
#### [ SageMaker Python SDK ]
Usando SageMaker Python SDK, puoi creare il tuo modello in uno dei seguenti modi:
+ **Creare un oggetto di modello dalla classe `Model`** - È necessario specificare il pacchetto del modello o il codice di inferenza (a seconda del server del modello), gli script per gestire la serializzazione e la deserializzazione dei dati tra il client e il server ed eventuali dipendenze da caricare su Amazon S3 per il consumo.
+ **Creare un oggetto di modello dalla classe `ModelBuilder`** - Fornisci artefatti del modello o codice di inferenza. `ModelBuilder` acquisisce automaticamente le dipendenze, deduce le funzioni di serializzazione e deserializzazione necessarie e genera un pacchetto delle dipendenze per creare l’oggetto `Model`.
Per ulteriori informazioni su `ModelBuilder`, consultare [Crea un modello in Amazon SageMaker AI con ModelBuilder](how-it-works-modelbuilder-creation.md). Per ulteriori informazioni, puoi anche consultare il blog [Package and deploy classic ML model in LLMs modo semplice con SageMaker AI — Part 1](https://aws.amazon.com/blogs/machine-learning/package-and-deploy-classical-ml-and-llms-easily-with-amazon-sagemaker-part-1-pysdk-improvements/).
Gli esempi che seguono descrivono entrambi i metodi per creare il modello e implementare l’oggetto di modello. Per implementare un modello, segui questa procedura:
1. Definisci le risorse di endpoint da allocare al modello con un oggetto `ResourceRequirements`.
1. Crea un oggetto di modello dalla classe `Model` oppure `ModelBuilder`. L’oggetto `ResourceRequirements` è specificato nelle impostazioni del modello.
1. Implementa il modello su un endpoint utilizzando il metodo `deploy` dell’oggetto `Model`.
------
#### [ boto3 inference components ]
Gli esempi che seguono mostrano come assegnare un modello a un componente di inferenza e quindi implementare il componente di inferenza in un endpoint. Per implementare un modello in questo modo, segui questa procedura:
1. (Facoltativo) Crea un oggetto modello SageMaker AI utilizzando il [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_model.html](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_model.html)metodo.
1. Specifica le impostazioni per l’endpoint creando un oggetto di configurazione dell’endpoint. Per crearne uno, utilizza il metodo [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint_config.html#create-endpoint-config](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint_config.html#create-endpoint-config).
1. Crea l’endpoint utilizzando il metodo [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html) e, nella richiesta, fornisci la configurazione dell’endpoint creata.
1. Crea un componente di inferenza utilizzando il metodo `create_inference_component`. Nelle impostazioni è possibile specificare un modello in uno dei seguenti modi:
+ Specificare un oggetto del modello SageMaker AI
+ Specificando l’URI dell’immagine del modello e dell’URL S3
È inoltre possibile allocare risorse dell’endpoint al modello. Creando il componente di inferenza, il modello viene implementato nell’endpoint. È possibile implementare più modelli in un endpoint creando più componenti di inferenza, uno per ogni modello.
------
#### [ boto3 models (without inference components) ]
Gli esempi che seguono mostrano come creare un oggetto di modello e quindi implementare il modello in un endpoint. Per implementare un modello in questo modo, segui questa procedura:
1. Crea un modello di SageMaker intelligenza artificiale utilizzando il [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_model.html](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_model.html)metodo.
1. Specifica le impostazioni per l’endpoint creando un oggetto di configurazione dell’endpoint. Per crearne uno, utilizza il metodo [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint_config.html#create-endpoint-config](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint_config.html#create-endpoint-config). Nella configurazione dell’endpoint assegna l’oggetto di modello a una variante di produzione.
1. Crea l’endpoint utilizzando il metodo [https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html). Nella richiesta fornisci la configurazione dell’endpoint creata.
Quando crei l'endpoint, l' SageMaker IA effettua il provisioning delle risorse dell'endpoint e distribuisce il modello sull'endpoint.
------
### Configura
Gli esempi seguenti configurano le risorse necessarie per implementare un modello in un endpoint.
------
#### [ SageMaker Python SDK ]
L’esempio seguente assegna le risorse dell’endpoint a un modello con un oggetto `ResourceRequirements`. Queste risorse includono core di CPU, acceleratori e memoria. Quindi, l’esempio crea un oggetto di modello dalla classe `Model`. In alternativa, è possibile creare un oggetto modello istanziando la [ModelBuilder](https://docs.aws.amazon.com/sagemaker/latest/dg/how-it-works-modelbuilder-creation.html)classe ed eseguendo`build`: questo metodo è illustrato anche nell'esempio. `ModelBuilder`fornisce un'interfaccia unificata per la creazione di pacchetti di modelli e, in questo caso, prepara un modello per l'implementazione di un modello su larga scala. L’esempio utilizza `ModelBuilder` per costruire un modello Hugging Face (Puoi anche passare un JumpStart modello). Una volta creato il modello, è possibile specificare i requisiti delle risorse nell’oggetto di modello. Nella fase successiva, questo oggetto viene utilizzato per implementare il modello in un endpoint.
```
resources = ResourceRequirements(
requests = {
"num_cpus": {{2}}, # Number of CPU cores required:
"num_accelerators": {{1}}, # Number of accelerators required
"memory": {{8192}}, # Minimum memory required in Mb (required)
"copies": {{1}},
},
limits = {},
)
now = datetime.now()
dt_string = now.strftime("%d-%m-%Y-%H-%M-%S")
model_name = "{{my-sm-model}}"+dt_string
# build your model with Model class
model = Model(
name = "{{model-name}}",
image_uri = "{{image-uri}}",
model_data = model_url,
role = "arn:aws:iam::{{111122223333}}:role/service-role/{{role-name}}",
resources = resources,
predictor_cls = Predictor,
)
# Alternate mechanism using ModelBuilder
# uncomment the following section to use ModelBuilder
/*
model_builder = ModelBuilder(
model="{{}}", # like "meta-llama/Llama-2-7b-hf"
schema_builder=SchemaBuilder({{sample_input}},{{sample_output}}),
env_vars={ "HUGGING_FACE_HUB_TOKEN": "{{}}}" }
)
# build your Model object
model = model_builder.build()
# create a unique name from string 'mb-inference-component'
model.model_name = unique_name_from_base("mb-inference-component")
# assign resources to your model
model.resources = resources
*/
```
------
#### [ boto3 inference components ]
Il seguente esempio configura un endpoint con il metodo `create_endpoint_config`. Questa configurazione viene assegnata a un endpoint in fase di creazione. Nella configurazione è possibile definire una o più varianti di produzione. Per ogni variante, puoi scegliere il tipo di istanza di cui desideri che Amazon SageMaker AI effettui il provisioning e puoi abilitare la scalabilità gestita delle istanze.
```
endpoint_config_name = "{{endpoint-config-name}}"
endpoint_name = "{{endpoint-name}}"
inference_component_name = "{{inference-component-name}}"
variant_name = "{{variant-name}}"
sagemaker_client.create_endpoint_config(
EndpointConfigName = endpoint_config_name,
ExecutionRoleArn = "arn:aws:iam::{{111122223333}}:role/service-role/{{role-name}}",
ProductionVariants = [
{
"VariantName": variant_name,
"InstanceType": "{{ml.p4d.24xlarge}}",
"InitialInstanceCount": {{1}},
"ManagedInstanceScaling": {
"Status": "{{ENABLED}}",
"MinInstanceCount": {{1}},
"MaxInstanceCount": {{2}},
},
}
],
)
```
------
#### [ boto3 models (without inference components) ]
**Example definizione di modello**
L'esempio seguente definisce un modello di SageMaker intelligenza artificiale con il `create_model` metodo contenuto in. AWS SDK per Python (Boto3)
```
model_name = "{{model-name}}"
create_model_response = sagemaker_client.create_model(
ModelName = model_name,
ExecutionRoleArn = "arn:aws:iam::{{111122223333}}:role/service-role/{{role-name}}",
PrimaryContainer = {
"Image": "{{image-uri}}",
"ModelDataUrl": model_url,
}
)
```
L’esempio specifica gli elementi seguenti:
+ `ModelName`: un nome per il modello (in questo esempio viene memorizzato come una variabile di stringa chiamata `model_name`).
+ `ExecutionRoleArn`: Amazon Resource Name (ARN) del ruolo IAM che Amazon SageMaker AI può assumere per accedere agli artefatti del modello e alle immagini Docker per la distribuzione su istanze di calcolo ML o per lavori di trasformazione in batch.
+ `PrimaryContainer`: il percorso dell'immagine docker principale contenente il codice di inferenza, gli artefatti associati e la mappa dell'ambiente personalizzata che il codice di inferenza utilizza quando il modello è distribuito per le previsioni.
**Example Configurazione dell'endpoint**
Il seguente esempio configura un endpoint con il metodo `create_endpoint_config`. Amazon SageMaker AI utilizza questa configurazione per distribuire modelli. Nella configurazione, identifichi uno o più modelli, creati con il `create_model` metodo, per distribuire le risorse di cui desideri che Amazon SageMaker AI fornisca.
```
endpoint_config_response = sagemaker_client.create_endpoint_config(
EndpointConfigName = "{{endpoint-config-name}}",
# List of ProductionVariant objects, one for each model that you want to host at this endpoint:
ProductionVariants = [
{
"VariantName": "{{variant-name}}", # The name of the production variant.
"ModelName": model_name,
"InstanceType": "{{ml.p4d.24xlarge}}",
"InitialInstanceCount": {{1}} # Number of instances to launch initially.
}
]
)
```
Questo esempio specifica le seguenti chiavi per il campo `ProductionVariants`:
+ `VariantName`: il nome della variante di produzione.
+ `ModelName`: il nome del modello per cui eseguire l'hosting. Questo è il nome specificato al momento della creazione del modello.
+ `InstanceType`: il tipo di istanza di calcolo ML. Consulta il `InstanceType` campo relativo [SageMaker ai prezzi di AI](https://aws.amazon.com/sagemaker/pricing/) per un elenco dei tipi di istanze di calcolo supportati e dei prezzi per ogni tipo di istanza. [https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_ProductionVariant.html](https://docs.aws.amazon.com/sagemaker/latest/APIReference/API_ProductionVariant.html)
------
### Implementazione
Gli esempi seguenti implementano un modello in un endpoint.
------
#### [ SageMaker Python SDK ]
L’esempio seguente implementa il modello in un endpoint HTTPS in tempo reale con il metodo `deploy` dell’oggetto di modello. Se specifichi un valore per l’argomento `resources` sia per la creazione che per l’implementazione del modello, le risorse specificate per l’implementazione hanno priorità.
```
predictor = model.deploy(
initial_instance_count = {{1}},
instance_type = "{{ml.p4d.24xlarge}}",
endpoint_type = EndpointType.INFERENCE_COMPONENT_BASED,
resources = resources,
)
```
Per il campo `instance_type`, l’esempio specifica il nome del tipo di istanza Amazon EC2 per il modello. Per il campo `initial_instance_count`, specifica il numero iniziale di istanze su cui eseguire l’endpoint.
Il seguente esempio di codice mostra un altro caso in cui si implementa un modello in un endpoint e quindi si implementa un altro modello nello stesso endpoint. In questo caso è necessario fornire lo stesso nome di endpoint ai metodi `deploy` di entrambi i modelli.
```
# Deploy the model to inference-component-based endpoint
falcon_predictor = falcon_model.deploy(
initial_instance_count = 1,
instance_type = "ml.p4d.24xlarge",
endpoint_type = EndpointType.INFERENCE_COMPONENT_BASED,
endpoint_name = "{{}}"
resources = resources,
)
# Deploy another model to the same inference-component-based endpoint
llama2_predictor = llama2_model.deploy( # resources already set inside llama2_model
endpoint_type = EndpointType.INFERENCE_COMPONENT_BASED,
endpoint_name = "{{}}" # same endpoint name as for falcon model
)
```
------
#### [ boto3 inference components ]
Una volta completata la configurazione dell’endpoint, utilizza il metodo [create\_endpoint](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html) per creare l’endpoint. Il nome dell'endpoint deve essere univoco all'interno e all'interno del tuo Regione AWS AWS account.
L’esempio seguente crea un endpoint utilizzando la configurazione dell’endpoint specificata nella richiesta. Amazon SageMaker AI utilizza l'endpoint per fornire risorse.
```
sagemaker_client.create_endpoint(
EndpointName = endpoint_name,
EndpointConfigName = endpoint_config_name,
)
```
Dopo aver creato un endpoint, è possibile implementare uno o più modelli al suo interno creando componenti di inferenza. L’esempio seguente ne crea uno con il metodo `create_inference_component`.
```
sagemaker_client.create_inference_component(
InferenceComponentName = inference_component_name,
EndpointName = endpoint_name,
VariantName = variant_name,
Specification = {
"Container": {
"Image": "{{image-uri}}",
"ArtifactUrl": model_url,
},
"ComputeResourceRequirements": {
"NumberOfCpuCoresRequired": {{1}},
"MinMemoryRequiredInMb": {{1024}}
}
},
RuntimeConfig = {"CopyCount": {{2}}}
)
```
------
#### [ boto3 models (without inference components) ]
**Example implementazione**
Fornisci la configurazione degli endpoint all'IA. SageMaker Il servizio avvia le istanze di calcolo ML e distribuisce il modello o i modelli come specificato nella configurazione.
Una volta completati il modello e la configurazione dell’endpoint, utilizza il metodo [create\_endpoint](https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/sagemaker/client/create_endpoint.html) per creare l’endpoint. Il nome dell'endpoint deve essere univoco all'interno e all'interno del tuo Regione AWS AWS account.
L’esempio seguente crea un endpoint utilizzando la configurazione dell’endpoint specificata nella richiesta. Amazon SageMaker AI utilizza l'endpoint per fornire risorse e distribuire modelli.
```
create_endpoint_response = sagemaker_client.create_endpoint(
# The endpoint name must be unique within an AWS Region in your AWS account:
EndpointName = "{{endpoint-name}}"
# The name of the endpoint configuration associated with this endpoint:
EndpointConfigName = "{{endpoint-config-name}}")
```
------
## Implementa modelli con AWS CLI
È possibile distribuire un modello su un endpoint utilizzando. AWS CLI
### Panoramica di
Quando si distribuisce un modello con AWS CLI, è possibile distribuirlo con o senza utilizzare un componente di inferenza. Le sezioni seguenti riepilogano i comandi da eseguire per entrambi gli approcci. Questi comandi sono illustrati negli esempi che seguono.
------
#### [ With inference components ]
Per implementare un modello con un componente di inferenza, segui questa procedura:
1. (Facoltativo) Crea un modello con il comando [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-model.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-model.html).
1. Specifica le impostazioni per l’endpoint creando una configurazione dell’endpoint. Per creare una, esegui il comando [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html).
1. Crea un endpoint utilizzando il comando [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html). Nel corpo del comando specifica la configurazione dell’endpoint creata.
1. Crea un componente di inferenza utilizzando il comando `create-inference-component`. Nelle impostazioni è possibile specificare un modello in uno dei seguenti modi:
+ Specificare un oggetto del modello AI SageMaker
+ Specificando l’URI dell’immagine del modello e dell’URL S3
È inoltre possibile allocare risorse dell’endpoint al modello. Creando il componente di inferenza, il modello viene implementato nell’endpoint. È possibile implementare più modelli in un endpoint creando più componenti di inferenza, uno per ogni modello.
------
#### [ Without inference components ]
Per implementare un modello senza utilizzare un componente di inferenza, segui questa procedura:
1. Crea un modello di SageMaker intelligenza artificiale utilizzando il [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-model.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-model.html)comando.
1. Specifica le impostazioni per l’endpoint creando un oggetto di configurazione dell’endpoint. Per creare uno, utilizza il comando [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html). Nella configurazione dell’endpoint assegna l’oggetto di modello a una variante di produzione.
1. Crea un endpoint utilizzando il comando [https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html). Nel corpo del comando specifica la configurazione dell’endpoint creata.
Quando crei l'endpoint, l' SageMaker IA effettua il provisioning delle risorse dell'endpoint e distribuisce il modello sull'endpoint.
------
### Configura
Gli esempi seguenti configurano le risorse necessarie per implementare un modello in un endpoint.
------
#### [ With inference components ]
**Example create-endpoint-config comando**
L'esempio seguente crea una configurazione dell'endpoint con il [create-endpoint-config](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html)comando.
```
aws sagemaker create-endpoint-config \
--endpoint-config-name {{endpoint-config-name}} \
--execution-role-arn arn:aws:iam::{{111122223333}}:role/service-role/{{role-name}}\
--production-variants file://production-variants.json
```
In questo esempio, il file `production-variants.json` definisce una variante di produzione con il seguente codice JSON:
```
[
{
"VariantName": "{{variant-name}}",
"ModelName": "{{model-name}}",
"InstanceType": "{{ml.p4d.24xlarge}}",
"InitialInstanceCount": {{1}}
}
]
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"EndpointConfigArn": "arn:aws:sagemaker:us-west-2:111122223333:endpoint-config/endpoint-config-name"
}
```
------
#### [ Without inference components ]
**Example di comando create-model**
L’esempio seguente crea un modello con il comando [create-model](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-model.html).
```
aws sagemaker create-model \
--model-name {{model-name}} \
--execution-role-arn arn:aws:iam::{{111122223333}}:role/service-role/{{role-name}} \
--primary-container "{ \"Image\": \"{{image-uri}}\", \"ModelDataUrl\": \"{{model-s3-url}}\"}"
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"ModelArn": "arn:aws:sagemaker:us-west-2:111122223333:model/model-name"
}
```
**Example create-endpoint-config comando**
L'esempio seguente crea una configurazione dell'endpoint con il [create-endpoint-config](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint-config.html)comando.
```
aws sagemaker create-endpoint-config \
--endpoint-config-name {{endpoint-config-name}} \
--production-variants file://production-variants.json
```
In questo esempio, il file `production-variants.json` definisce una variante di produzione con il seguente codice JSON:
```
[
{
"VariantName": "{{variant-name}}",
"ModelName": "{{model-name}}",
"InstanceType": "{{ml.p4d.24xlarge}}",
"InitialInstanceCount": {{1}}
}
]
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"EndpointConfigArn": "arn:aws:sagemaker:us-west-2:111122223333:endpoint-config/endpoint-config-name"
}
```
------
### Implementazione
Gli esempi seguenti implementano un modello in un endpoint.
------
#### [ With inference components ]
**Example di comando create-endpoint**
L’esempio seguente crea un endpoint con il comando [create-endpoint](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html).
```
aws sagemaker create-endpoint \
--endpoint-name {{endpoint-name}} \
--endpoint-config-name {{endpoint-config-name}}
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"EndpointArn": "arn:aws:sagemaker:us-west-2:111122223333:endpoint/endpoint-name"
}
```
**Example create-inference-component comando**
L'esempio seguente crea un componente di inferenza con il create-inference-component comando.
```
aws sagemaker create-inference-component \
--inference-component-name {{inference-component-name}} \
--endpoint-name {{endpoint-name}} \
--variant-name {{variant-name}} \
--specification file://specification.json \
--runtime-config "{{{\"CopyCount\": 2}}}"
```
In questo esempio, il file `specification.json` definisce il container e le risorse di calcolo con il seguente codice JSON:
```
{
"Container": {
"Image": "{{image-uri}}",
"ArtifactUrl": "{{model-s3-url}}"
},
"ComputeResourceRequirements": {
"NumberOfCpuCoresRequired": 1,
"MinMemoryRequiredInMb": 1024
}
}
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"InferenceComponentArn": "arn:aws:sagemaker:us-west-2:111122223333:inference-component/inference-component-name"
}
```
------
#### [ Without inference components ]
**Example di comando create-endpoint**
L’esempio seguente crea un endpoint con il comando [create-endpoint](https://docs.aws.amazon.com/cli/latest/reference/sagemaker/create-endpoint.html).
```
aws sagemaker create-endpoint \
--endpoint-name {{endpoint-name}} \
--endpoint-config-name {{endpoint-config-name}}
```
Se il comando ha esito positivo, AWS CLI risponde con l'ARN della risorsa creata.
```
{
"EndpointArn": "arn:aws:sagemaker:us-west-2:111122223333:endpoint/endpoint-name"
}
```
------