Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Dataloader mappato in memoria
Un altro sovraccarico di riavvio deriva dal caricamento dei dati: il cluster di addestramento rimane inattivo mentre il dataloader si inizializza, scarica i dati dai file system remoti e li elabora in batch.
Per risolvere questo problema, introduciamo il Memory Mapped DataLoader (MMAP) Dataloader, che memorizza nella cache i batch preimpostati nella memoria persistente, assicurando che rimangano disponibili anche dopo un riavvio indotto da un errore. Questo approccio elimina i tempi di configurazione del dataloader e consente di riprendere immediatamente l'addestramento utilizzando batch memorizzati nella cache, mentre il dataloader reinizializza e recupera contemporaneamente i dati successivi in background. La cache dei dati si trova su ogni livello che richiede dati di addestramento e mantiene due tipi di batch: i batch consumati di recente e utilizzati per l'addestramento e i batch precaricati pronti per l'uso immediato.
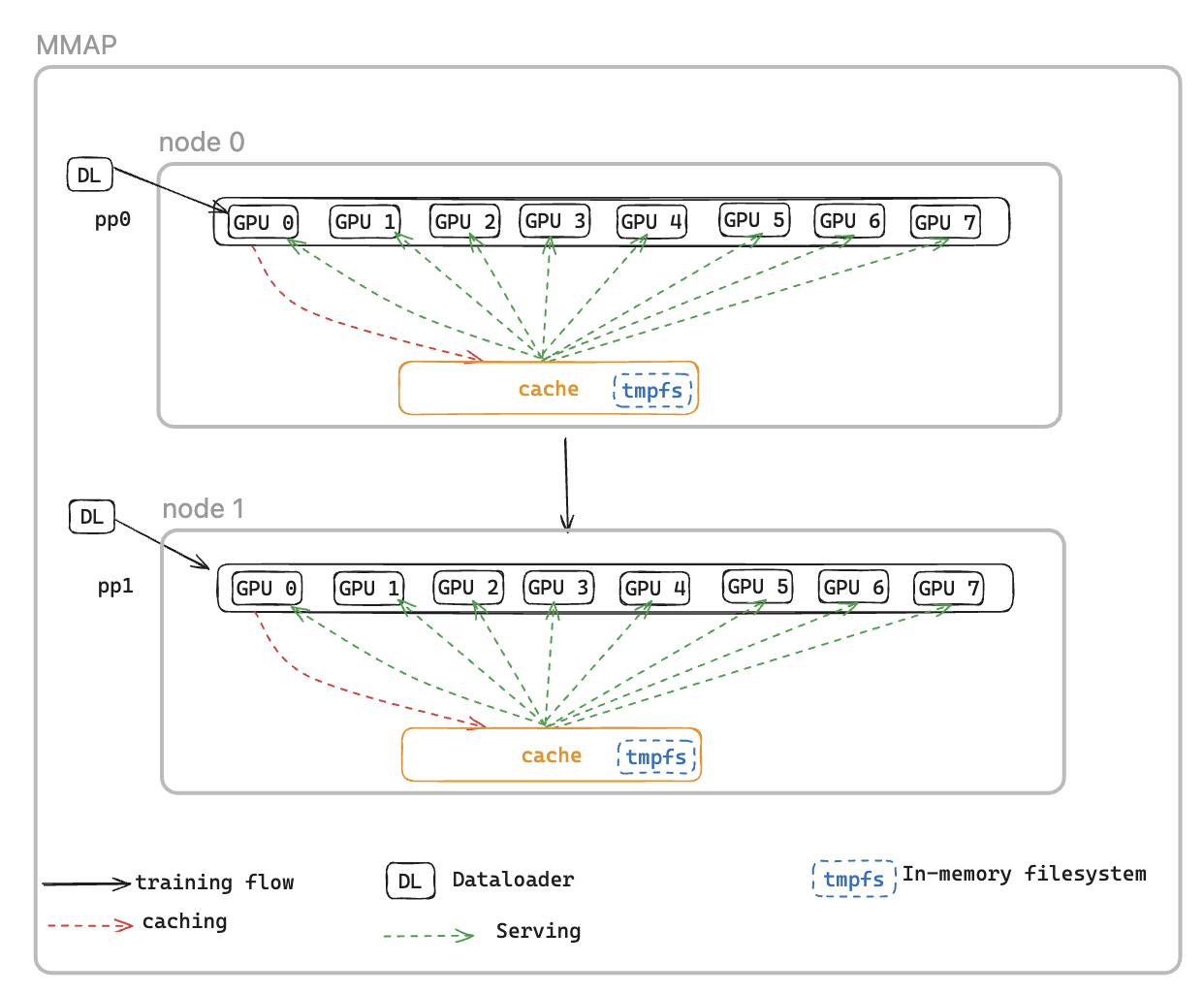
Il dataloader MMAP offre due funzionalità seguenti:
Prefetching dei dati: recupera e memorizza in modo proattivo i dati generati dal dataloader
Memorizzazione nella cache persistente: archivia i batch consumati e quelli precaricati in un file system temporaneo che sopravvive al riavvio del processo
Utilizzando la cache, il processo di formazione trarrà vantaggio da:
Impronta di memoria ridotta: sfrutta la mappatura della memoria I/O per mantenere una singola copia condivisa dei dati nella memoria della CPU host, eliminando le copie ridondanti tra i processi GPU (ad esempio, riduce da 8 copie a 1 su un'istanza p5 con 8 GPU)
Ripristino più rapido: riduce il tempo medio di riavvio (MTTR) grazie alla possibilità di riprendere immediatamente l'addestramento dai batch memorizzati nella cache, eliminando così l'attesa per la reinizializzazione del dataloader e la generazione del primo batch
Configurazioni MMAP
Per utilizzare MMAP, è sufficiente inserire il modulo dati originale in MMAPDataModule
data_module=MMAPDataModule( data_module=MY_DATA_MODULE(...), mmap_config=CacheResumeMMAPConfig( cache_dir=self.cfg.mmap.cache_dir, checkpoint_frequency=self.cfg.mmap.checkpoint_frequency), )
CacheResumeMMAPConfig: I parametri di MMAP Dataloader controllano la posizione della directory della cache, i limiti di dimensione e la delega per il recupero dei dati. Per impostazione predefinita, solo il livello TP 0 per nodo recupera i dati dall'origine, mentre gli altri ranghi dello stesso gruppo di replica li leggono dalla cache condivisa, eliminando i trasferimenti ridondanti.
MMAPDataModule: racchiude il modulo di dati originale e restituisce il dataloader mmap sia per l'addestramento che per la convalida.
Vedi l'esempio per abilitare MMAP.
Guida di riferimento alle API
CacheResumeMMAPConfig
class hyperpod_checkpointless_training.dataloader.config.CacheResumeMMAPConfig( cache_dir='/dev/shm/pdl_cache', prefetch_length=10, val_prefetch_length=10, lookback_length=2, checkpoint_frequency=None, model_parallel_group=None, enable_batch_encryption=False)
Classe di configurazione per la funzionalità del dataloader cache-resume memory-mapped (MMAP) durante la formazione senza checkpoint. HyperPod
Questa configurazione consente un caricamento efficiente dei dati con funzionalità di caching e prefetching, permettendo di riprendere rapidamente l'addestramento dopo i guasti mantenendo i batch di dati memorizzati nella cache in file mappati in memoria.
Parametri
-
cache_dir (str, opzionale) — Percorso della directory per l'archiviazione dei batch di dati memorizzati nella cache. Predefinito: «//pdl_cache» dev/shm
-
prefetch_length (int, opzionale) — Numero di batch da prerecuperare durante l'allenamento. Impostazione predefinita: 10
-
val_prefetch_length (int, opzionale) — Numero di batch da prerecuperare in anticipo durante la convalida. Impostazione predefinita: 10
-
lookback_length (int, opzionale) — Numero di batch utilizzati in precedenza da conservare nella cache per un potenziale riutilizzo. Impostazione predefinita: 2
-
checkpoint_frequency (int, opzionale) — Frequenza delle fasi di checkpoint del modello. Utilizzato per l'ottimizzazione delle prestazioni della cache. Impostazione predefinita: nessuna
-
model_parallel_group (oggetto, opzionale) — Gruppo di processi per il parallelismo dei modelli. Se Nessuno, verrà creato automaticamente. Impostazione predefinita: nessuna
-
enable_batch_encryption (bool, opzionale) — Indica se abilitare la crittografia per i dati batch memorizzati nella cache. Impostazione predefinita: False
Metodi
create(dataloader_init_callable, parallel_state_util, step, is_data_loading_rank, create_model_parallel_group_callable, name='Train', is_val=False, cached_len=0)
Crea e restituisce un'istanza di dataloader MMAP configurata.
Parametri
-
dataloader_init_callable (Callable) — Funzione per inizializzare il dataloader sottostante
-
parallel_state_util (object) — Utilità per la gestione dello stato parallelo tra i processi
-
step (int) — La fase relativa ai dati da cui riprendere durante l'allenamento
-
is_data_loading_rank (Callable) — Funzione che restituisce True se il rank corrente deve caricare i dati
-
create_model_parallel_group_callable (Callable) — Funzione per creare un gruppo di processi parallelo modello
-
name (str, opzionale) — Identificatore del nome per il dataloader. Predefinito: «Train»
-
is_val (bool, opzionale) — Se si tratta di un dataloader di convalida. Impostazione predefinita: False
-
cached_len (int, opzionale) — Lunghezza dei dati memorizzati nella cache se si riprende dalla cache esistente. Impostazione predefinita: 0
Restituisce CacheResumePrefetchedDataLoader o: istanza del dataloader MMAP configurata CacheResumeReadDataLoader
Aumenta ValueError se il parametro step è. None
Esempio
from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig # Create configuration config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100, enable_batch_encryption=False ) # Create dataloader dataloader = config.create( dataloader_init_callable=my_dataloader_init, parallel_state_util=parallel_util, step=current_step, is_data_loading_rank=lambda: rank == 0, create_model_parallel_group_callable=create_mp_group, name="TrainingData" )
Note
-
La directory della cache dovrebbe avere spazio sufficiente e I/O prestazioni veloci (ad esempio,/dev/shm per l'archiviazione in memoria).
-
L'impostazione
checkpoint_frequencymigliora le prestazioni della cache allineando la gestione della cache con il checkpointing del modello -
Per i dataloaders di convalida (
is_val=True), il passaggio viene reimpostato su 0 e l'avvio a freddo viene forzato -
Vengono utilizzate diverse implementazioni del dataloader a seconda che il rango corrente sia responsabile del caricamento dei dati
MMAPDataModule
class hyperpod_checkpointless_training.dataloader.mmap_data_module.MMAPDataModule( data_module, mmap_config, parallel_state_util=MegatronParallelStateUtil(), is_data_loading_rank=None)
Un DataModule wrapper PyTorch Lightning che applica funzionalità di caricamento dei dati mappate in memoria (MMAP) a quelle esistenti per un addestramento senza checkpoint. DataModules
Questa classe integra un PyTorch Lightning esistente e lo migliora con la funzionalità MMAP, che consente una memorizzazione efficiente dei dati nella cache DataModule e un ripristino rapido in caso di errori di formazione. Mantiene la compatibilità con l'interfaccia originale DataModule aggiungendo funzionalità di formazione senza checkpoint.
Parameters
- data_module (pl. LightningDataModule)
Il sottostante DataModule da avvolgere (ad esempio, LLMDataModule)
- mmap_config (MMapConfig)
L'oggetto di configurazione MMAP che definisce il comportamento e i parametri della memorizzazione nella cache
parallel_state_util(MegatronParallelStateUtil, opzionale)Utilità per la gestione dello stato parallelo tra processi distribuiti. Impostazione predefinita: MegatronParallelStateUtil ()
is_data_loading_rank(Richiamabile, opzionale)Funzione che restituisce True se il rango corrente deve caricare dati. Se Nessuno, il valore predefinito è parallel_state_util.is_tp_0. Impostazione predefinita: nessuna
Attributes
global_step(int)Fase di formazione globale attuale, utilizzata per riprendere dai checkpoint
cached_train_dl_len(int)Lunghezza memorizzata nella cache del dataloader di addestramento
cached_val_dl_len(int)Lunghezza memorizzata nella cache del dataloader di convalida
Metodi
setup(stage=None)
Imposta il modulo di dati sottostante per la fase di formazione specificata.
stage(str, opzionale)Fase dell'allenamento («adattamento», «convalida», «test» o «previsione»). Impostazione predefinita: nessuna
train_dataloader()
Crea l'allenamento DataLoader con MMAP wrapping.
Restituisce: DataLoader — MMAP-wrapped formazione DataLoader con funzionalità di caching e prefetching
val_dataloader()
Crea la convalida con il wrapping DataLoader MMAP.
Restituisce: DataLoader — MMAP-wrapped convalida DataLoader con funzionalità di memorizzazione nella cache
test_dataloader()
Crea il test DataLoader se il modulo di dati sottostante lo supporta.
Restituisce: DataLoader o Nessuno: esegue il test DataLoader dal modulo di dati sottostante o Nessuno se non è supportato
predict_dataloader()
Crea la previsione DataLoader se il modulo di dati sottostante la supporta.
Restituisce: DataLoader o Nessuno: prevedi DataLoader dal modulo di dati sottostante o Nessuno se non è supportato
load_checkpoint(checkpoint)
Carica le informazioni sul checkpoint per riprendere l'allenamento da una fase specifica.
- checkpoint (dict)
dizionario Checkpoint contenente la chiave 'global_step'
get_underlying_data_module()
Ottieni il modulo di dati racchiuso sottostante.
Restituisce: pl. LightningDataModule — Il modulo dati originale che è stato confezionato
state_dict()
Ottieni il dizionario di stato del MMAP DataModule per il checkpoint.
Restituisce: dict — Dizionario contenente le lunghezze del dataloader memorizzate nella cache
load_state_dict(state_dict)
Carica il dizionario di stato per ripristinare lo stato MMAP. DataModule
state_dict(dict)Dizionario di stato da caricare
Proprietà
data_sampler
Esporre il campionatore di dati del modulo di dati sottostante al framework. NeMo
Restituisce: object or None: il campionatore di dati del modulo di dati sottostante
Esempio
from hyperpod_checkpointless_training.dataloader.mmap_data_module import MMAPDataModule from hyperpod_checkpointless_training.dataloader.config import CacheResumeMMAPConfig from my_project import MyLLMDataModule # Create MMAP configuration mmap_config = CacheResumeMMAPConfig( cache_dir="/tmp/training_cache", prefetch_length=20, checkpoint_frequency=100 ) # Create original data module original_data_module = MyLLMDataModule( data_path="/path/to/data", batch_size=32 ) # Wrap with MMAP capabilities mmap_data_module = MMAPDataModule( data_module=original_data_module, mmap_config=mmap_config ) # Use in PyTorch Lightning Trainer trainer = pl.Trainer() trainer.fit(model, data=mmap_data_module) # Resume from checkpoint checkpoint = {"global_step": 1000} mmap_data_module.load_checkpoint(checkpoint)
Note
Il wrapper delega la maggior parte dell'accesso degli attributi al modulo di dati sottostante utilizzando __getattr__
Solo i ranghi di caricamento dei dati inizializzano e utilizzano effettivamente il modulo di dati sottostante; gli altri ranghi utilizzano dataloader falsi
Le lunghezze dei dataloader memorizzati nella cache vengono mantenute per ottimizzare le prestazioni durante la ripresa dell'allenamento
