Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
In-process recupero e allenamento senza checkpoint
HyperPod la formazione senza checkpointless utilizza la ridondanza dei modelli per consentire un addestramento tollerante agli errori. Il principio fondamentale è che gli stati del modello e dell'ottimizzatore vengono completamente replicati su più gruppi di nodi, con aggiornamenti di peso e modifiche dello stato dell'ottimizzatore replicati in modo sincrono all'interno di ciascun gruppo. Quando si verifica un errore, le repliche integre completano le fasi di ottimizzazione e trasmettono gli stati aggiornati alle repliche in fase di ripristino. model/optimizer
Questo approccio basato sulla ridondanza del modello consente diversi meccanismi di gestione dei guasti:
-
In-process ripristino: i processi rimangono attivi nonostante i guasti, mantenendo tutti gli stati del modello e dell'ottimizzatore nella memoria della GPU con i valori più recenti
-
Gestione agevole delle interruzioni: aborti controllati e pulizia delle risorse per le operazioni interessate
-
Riesecuzione del blocco di codice: riesecuzione solo dei segmenti di codice interessati all'interno di un Code Block (RCB) Re-executable
-
Recupero senza punti di controllo senza perdita dei progressi di allenamento: poiché i processi persistono e gli stati rimangono in memoria, nessun progresso dell'allenamento viene perso; quando si verifica un guasto l'allenamento riprende dalla fase precedente, anziché riprendere dall'ultimo checkpoint salvato
Configurazioni senza checkpoint
Ecco il frammento principale della formazione senza checkpointless.
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank wait_rank() def main(): @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=PEFTCheckpointManager(enable_offload=True), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), ) def run_main(cfg, caller: Optional[HPCallWrapper] = None): ... trainer = Trainer( strategy=CheckpointlessMegatronStrategy(..., num_distributed_optimizer_instances=2), callbacks=[..., CheckpointlessCallback(...)], ) trainer.fresume = resume trainer._checkpoint_connector = CheckpointlessCompatibleConnector(trainer) trainer.wrapper = caller
wait_rank: Tutti i ranghi aspetteranno le informazioni sulla classifica dall'infrastruttura. HyperpodTrainingOperatorHPWrapper: wrapper di funzioni Python che abilita le funzionalità di riavvio per un Re-executable Code Block (RCB). L'implementazione utilizza un gestore di contesto anziché un decoratore Python perché i decoratori non possono determinare il numero di RCB da monitorare in fase di esecuzione.CudaHealthCheck: Assicura che il contesto CUDA per il processo corrente sia integro mediante la sincronizzazione con la GPU. Utilizza il dispositivo specificato dalla variabile di ambiente LOCAL_RANK o utilizza come impostazione predefinita il dispositivo CUDA del thread principale se LOCAL_RANK non è impostato.HPAgentK8sAPIFactory: Questa API consente la formazione senza checkpoint per interrogare lo stato di addestramento di altri pod nel cluster di formazione Kubernetes. Fornisce inoltre una barriera a livello di infrastruttura che garantisce che tutti i ranghi completino con successo le operazioni di interruzione e riavvio prima di procedere.CheckpointManager: Gestisce i checkpoint in memoria e il ripristino peer-to-peer per una tolleranza agli errori senza checkpoint. Ha le seguenti responsabilità principali:In-Memory Gestione dei checkpoint: salva e gestisce i checkpoint NeMo del modello in memoria per un ripristino rapido senza disco I/O durante gli scenari di ripristino senza checkpoint.
Convalida della fattibilità del ripristino: determina se è possibile il ripristino senza checkpoint convalidando la coerenza globale dei passaggi, lo stato del rango e l'integrità dello stato del modello.
Peer-to-Peer Orchestrazione del ripristino: coordina il trasferimento dei checkpoint tra i ranghi sani e quelli danneggiati utilizzando la comunicazione distribuita per un ripristino rapido.
Gestione dello stato RNG: conserva e ripristina gli stati dei generatori di numeri casuali su Python e Megatron per il NumPy ripristino PyTorch deterministico.
[Opzionale] Checkpoint Offload: trasferisci il checkpoint di memoria sulla CPU se la GPU non ha una capacità di memoria sufficiente.
PEFTCheckpointManager: Si estende mantenendo i pesi del modello baseCheckpointManagerper la regolazione fine del PEFT.CheckpointlessAbortManager: Gestisce le operazioni di interruzione in un thread in background quando si verifica un errore. Per impostazione predefinita, interrompe TransformerEngine, Checkpointing e. TorchDistributed DataLoader Gli utenti possono registrare gestori di aborti personalizzati in base alle esigenze. Una volta completata l'interruzione, tutte le comunicazioni devono cessare e tutti i processi e i thread devono terminare per evitare perdite di risorse.CheckpointlessFinalizeCleanup: gestisce le operazioni di pulizia finale nel thread principale per i componenti che non possono essere interrotti o ripuliti in modo sicuro nel thread in background.CheckpointlessMegatronStrategy: Eredita dalla forma di NemoMegatronStrategy. Nota che l'addestramento senza checkpoint richiede almeno 2 partecipantinum_distributed_optimizer_instancesper consentire la replica dell'ottimizzatore. La strategia si occupa anche della registrazione degli attributi essenziali e dell'inizializzazione dei gruppi di processi, ad esempio rootless.CheckpointlessCallback: Lightning callback che integra l' NeMo allenamento con il sistema di tolleranza ai guasti di checkpointless training. Ha le seguenti responsabilità principali:Gestione del ciclo di vita delle fasi di allenamento: tiene traccia dei progressi dell'allenamento e si coordina ParameterUpdateLock per enable/disable un recupero senza problemi in base allo stato dell'allenamento (prima fase e fasi successive).
Checkpoint State Coordination: gestisce il checkpoint del modello base PEFT in memoria. saving/restoring
CheckpointlessCompatibleConnector: Un PTLCheckpointConnectorche tenta di precaricare il file di checkpoint in memoria, con il percorso di origine determinato in base a questa priorità:prova checkpointless recovery
se checkpointless restituisce None, torna a parent.resume_start ()
Guarda l'esempio per aggiungere funzionalità di formazione senza checkpointless ai codici.
Concetti
Questa sezione introduce concetti di formazione senza checkpoint. La formazione Checkpointless su Amazon SageMaker HyperPod supporta il ripristino in corso. Questa interfaccia API segue un formato simile a quello delle API NVRx.
Concetto: Re-Executable Code Block (RCB)
Quando si verifica un errore, i processi sani rimangono attivi, ma una parte del codice deve essere rieseguita per ripristinare gli stati di addestramento e gli stack Python. Un Re-executable Code Block (RCB) è un segmento di codice specifico che viene eseguito nuovamente durante il ripristino in caso di errore. Nell'esempio seguente, l'RCB comprende l'intero script di addestramento (ovvero, tutto ciò che è contenuto in main ()), il che significa che ogni ripristino in caso di errore riavvia lo script di addestramento preservando il modello in memoria e gli stati dell'ottimizzatore.
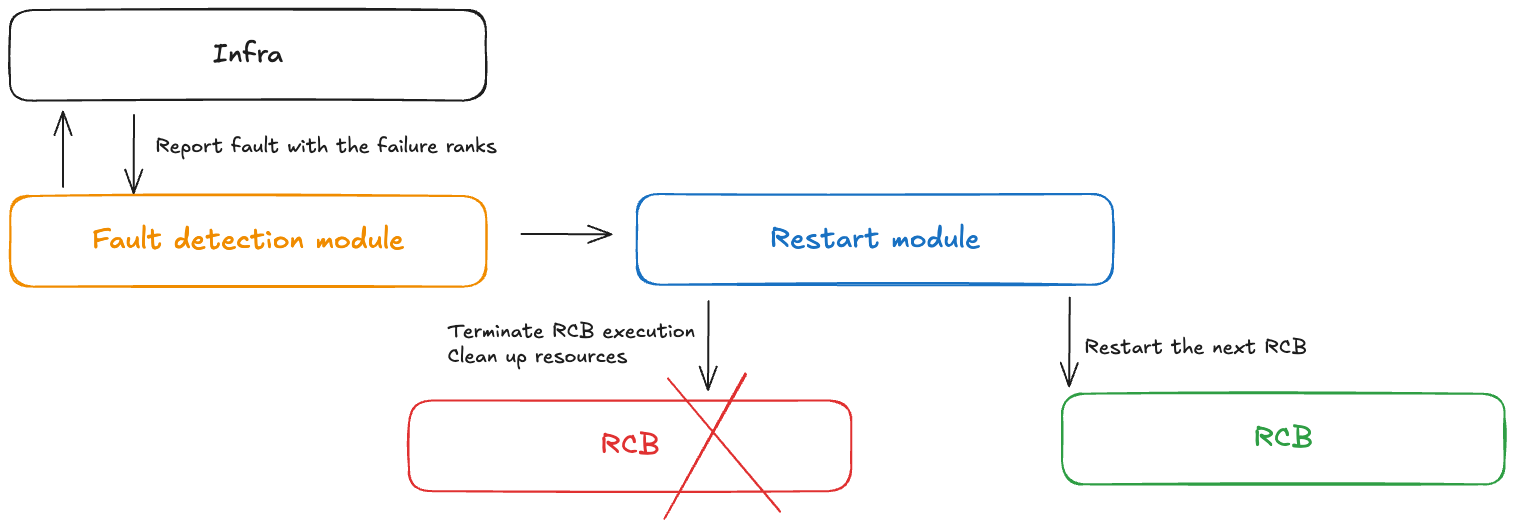
Concetto: controllo dei guasti
Un modulo di controllo dei guasti riceve notifiche quando si verificano guasti durante un addestramento senza checkpoint. Questo controller di guasto include i seguenti componenti:
Modulo di rilevamento dei guasti: riceve notifiche di guasti dell'infrastruttura
API di definizione RCB: consentono agli utenti di definire il blocco di codice rieseguibile (RCB) nel proprio codice
Modulo di riavvio: termina l'RCB, ripulisce le risorse e riavvia l'RCB
Concetto: ridondanza del modello
L'addestramento su modelli di grandi dimensioni richiede in genere una dimensione parallela dei dati sufficientemente grande per addestrare i modelli in modo efficiente. Nel tradizionale parallelismo dei dati come PyTorch DDP e Horovod, il modello è completamente replicato. Le tecniche più avanzate di parallelismo dei dati condivisi come DeepSpeed Zero Optimizer e FSDP supportano anche la modalità di sharding ibrida, che consente di suddividere gli stati all'interno del gruppo di sharding e di replicarli completamente tra i gruppi di replica. model/optimizer NeMo ha anche questa funzione di sharding ibrido tramite un argomento num_distributed_optimizer_instances, che consente la ridondanza.
Tuttavia, l'aggiunta della ridondanza indica che il modello non sarà completamente suddiviso in tutto il cluster, con conseguente maggiore utilizzo della memoria del dispositivo. La quantità di memoria ridondante varierà a seconda delle specifiche tecniche di sharding del modello implementate dall'utente. I pesi, i gradienti e la memoria di attivazione del modello a bassa precisione non ne risentiranno, poiché vengono suddivisi tramite il parallelismo del modello. Il modello master ad alta precisione e gli stati dell'ottimizzatore ne risentiranno. weights/gradients L'aggiunta di una replica ridondante del modello aumenta l'utilizzo della memoria del dispositivo all'incirca dell'equivalente delle dimensioni di un checkpoint DCP.
Lo sharding ibrido suddivide i collettivi di tutti i gruppi DP in collettivi relativamente più piccoli. In precedenza c'era una riduzione della dispersione e un raggruppamento universale tra l'intero gruppo DP. Dopo lo sharding ibrido, il reduce-scatter viene eseguito solo all'interno di ogni replica del modello e verrà applicata una riduzione totale tra i gruppi di repliche dei modelli. L'all-collect funziona anche all'interno di ogni replica del modello. Di conseguenza, l'intero volume di comunicazioni rimane pressoché invariato, ma i collettivi utilizzano gruppi più piccoli, quindi prevediamo una latenza migliore.
Concetto: tipi di errore e riavvio
La tabella seguente riporta i diversi tipi di errore e i meccanismi di ripristino associati. Checkpointless training tenta innanzitutto il ripristino in caso di errore tramite un ripristino in corso, seguito da un riavvio a livello di processo. Si ritorna al riavvio a livello di processo solo in caso di guasto catastrofico (ad esempio, guasto di più nodi contemporaneamente).
| Tipo di errore | Causa | Tipo di ripristino | Meccanismo di ripristino |
|---|---|---|---|
| In-process fallimento | Code-level errori, eccezioni | In-Process Recupero (IPR) | Riesegui RCB all'interno del processo esistente; i processi sani rimangono attivi |
| Errore di riavvio del processo | Contesto CUDA danneggiato, processo interrotto | Riavvio a livello di processo (PLR) | SageMaker HyperPod l'operatore addetto alla formazione riavvia i processi; salta il riavvio del pod K8s |
| Errore di sostituzione del nodo | Guasto node/GPU hardware permanente | Job Level Restart (JLR) | Sostituisci il nodo fallito; riavvia l'intero processo di formazione |
Concetto: protezione Atomic Lock per Optimizer Step
L'esecuzione del modello è suddivisa in tre fasi: propagazione in avanti, propagazione all'indietro e fase di ottimizzazione. Il comportamento di ripristino varia in base alla tempistica dell'errore:
Forward/backward propagazione: torna all'inizio della fase di addestramento corrente e trasmetti gli stati del modello ai nodi sostitutivi
Fase di ottimizzazione: consenti alle repliche sane di completare la fase di protezione protetta, quindi trasmetti gli stati aggiornati del modello ai nodi sostitutivi
Questa strategia garantisce che gli aggiornamenti completati dell'ottimizzatore non vengano mai scartati, contribuendo a ridurre i tempi di ripristino dei guasti.
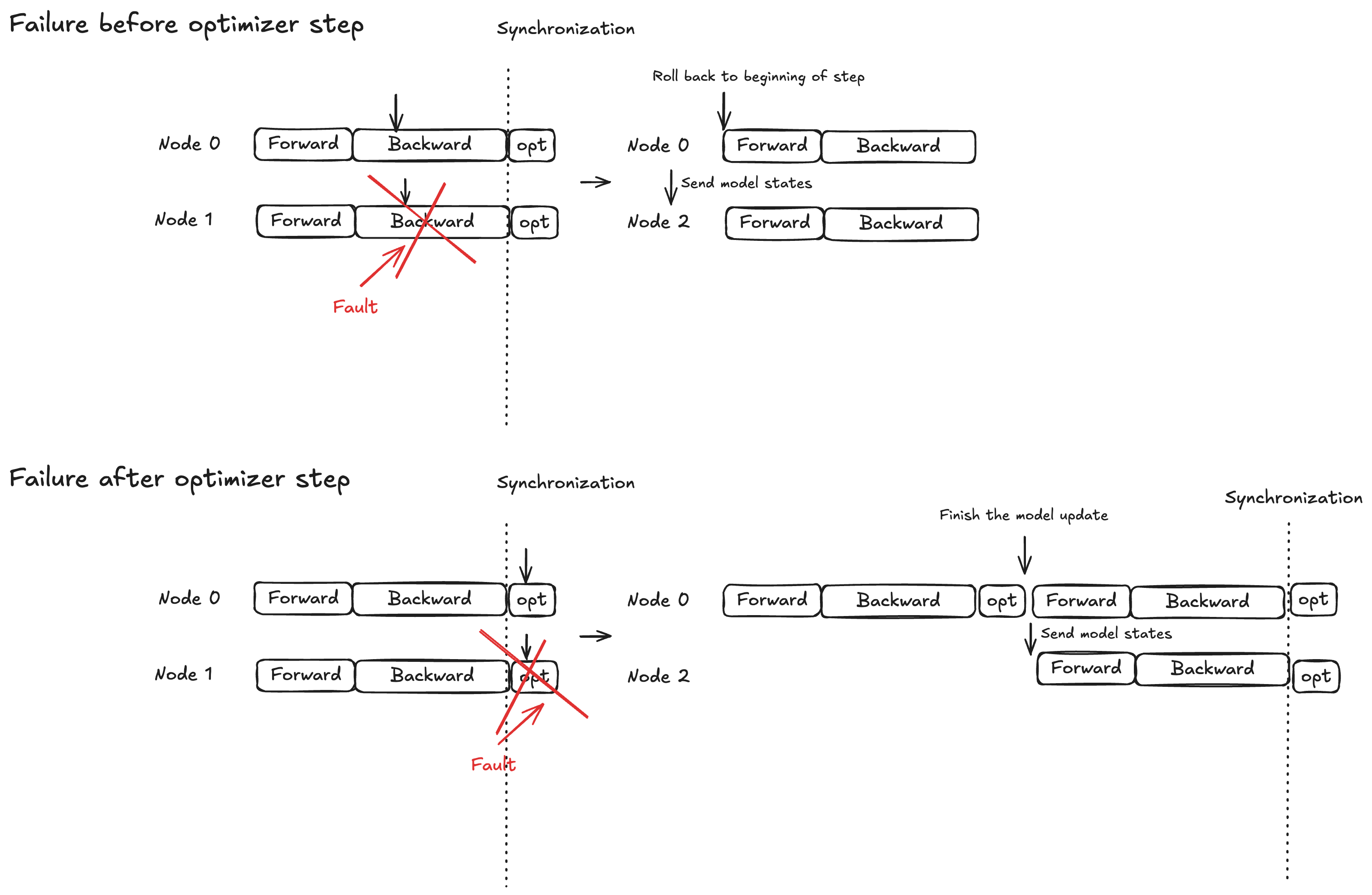
Diagramma del flusso di allenamento Checkpointless
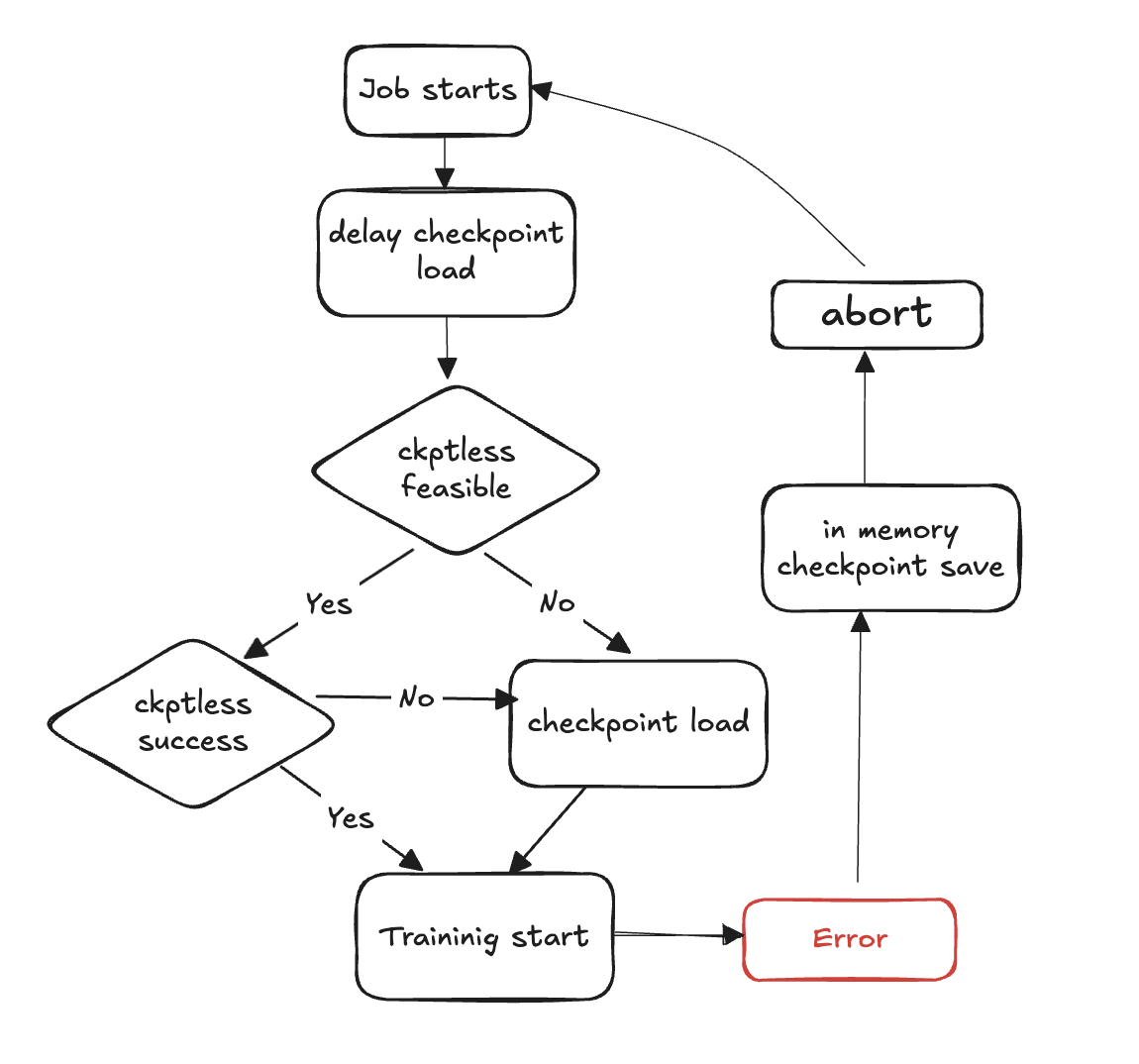
I passaggi seguenti descrivono il processo di rilevamento degli errori e di ripristino senza checkpoint:
Inizia il ciclo di formazione
Si verifica un errore
Valuta la fattibilità di un curriculum senza checkpoint
Verifica se è possibile eseguire un curriculum senza checkpoint
Se possibile, prova a riprendere senza checkpointless
Se la ripresa fallisce, torna al caricamento del checkpoint dallo storage
Se la ripresa ha esito positivo, l'allenamento continua dallo stato di ripristino
Se non è possibile, ricorri al checkpoint di caricamento dal magazzino
Pulisci le risorse: interrompi tutti i gruppi di processi e i backend e libera le risorse in preparazione al riavvio.
Riprendi il ciclo di allenamento: inizia un nuovo ciclo di allenamento e il processo torna alla fase 1.
Guida di riferimento alle API
wait_rank
hyperpod_checkpointless_training.inprocess.train_utils.wait_rank()
Attende e recupera le informazioni sulla classificazione da HyperPod, quindi aggiorna l'ambiente di processo corrente con variabili di addestramento distribuite.
Questa funzione ottiene l'assegnazione del grado e le variabili di ambiente corrette per l'addestramento distribuito. Garantisce che ogni processo ottenga la configurazione appropriata per il suo ruolo nel processo di formazione distribuito.
Parametri
Nessuno
Valori restituiti
Nessuno
Comportamento
Controllo del processo: salta l'esecuzione se viene chiamato da un sottoprocesso (viene eseguito solo in) MainProcess
Recupero dell'ambiente: recupera le variabili correnti
RANKe da quelle di ambienteWORLD_SIZEHyperPod Comunicazione: chiamate
hyperpod_wait_rank_info()da cui recuperare informazioni sulla classifica HyperPodAggiornamento dell'ambiente: aggiorna l'ambiente di processo corrente con le variabili di ambiente specifiche del lavoratore ricevute da HyperPod
Variabili di ambiente
La funzione legge le seguenti variabili di ambiente:
RANK (int) — Classificazione attuale del processo (impostazione predefinita: -1 se non è impostata)
WORLD_SIZE (int) — Numero totale di processi nel processo distribuito (predefinito: 0 se non è impostato)
Aumenta
AssertionError— Se la risposta di non HyperPod è nel formato previsto o se mancano i campi obbligatori
Esempio
from hyperpod_checkpointless_training.inprocess.train_utils import wait_rank # Call before initializing distributed training wait_rank() # Now environment variables are properly set for this rank import torch.distributed as dist dist.init_process_group(backend='nccl')
Note
Viene eseguito solo nel processo principale; le chiamate ai sottoprocessi vengono saltate automaticamente
La funzione si blocca finché non HyperPod fornisce le informazioni sulla classificazione
HPWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPWrapper( *, abort=Compose(HPAbortTorchDistributed()), finalize=None, health_check=None, hp_api_factory=None, abort_timeout=None, enabled=True, trace_file_path=None, async_raise_before_abort=True, early_abort_communicator=False, checkpoint_manager=None, check_memory_status=True)
Wrapper di funzioni Python che abilita le funzionalità di riavvio per un Re-executable Code Block (RCB) in un addestramento senza checkpoint. HyperPod
Questo wrapper offre funzionalità di tolleranza agli errori e ripristino automatico monitorando l'esecuzione della formazione e coordinando i riavvii tra i processi distribuiti in caso di errori. Utilizza un approccio di gestione del contesto anziché un decoratore per mantenere le risorse globali durante tutto il ciclo di vita della formazione.
Parametri
abort (Abort, opzionale): interrompe l'esecuzione in modo asincrono quando vengono rilevati errori. Impostazione predefinita:
Compose(HPAbortTorchDistributed())finalize (Finalize, opzionale): finalizza il gestore eseguito durante il riavvio. Rank-local Impostazione predefinita:
Nonehealth_check (HealthCheck, opzionale) — Rank-local controllo dello stato di salute eseguito durante il riavvio. Impostazione predefinita:
Nonehp_api_factory (Callable, opzionale) — Funzione di fabbrica per la creazione di un'API con cui interagire. HyperPod HyperPod Impostazione predefinita:
Noneabort_timeout (float, opzionale) — Timeout per l'interruzione della chiamata nel thread di controllo degli errori. Impostazione predefinita:
Noneenabled (bool, opzionale) — Abilita la funzionalità wrapper. Quando
False, il wrapper diventa un pass-through. Impostazione predefinita:Truetrace_file_path (str, opzionale) — Percorso del file di traccia per la profilazione. VizTracer Impostazione predefinita:
Noneasync_raise_before_abort (bool, opzionale) — Abilita il raise before abort nel thread di controllo degli errori. Impostazione predefinita:
Trueearly_abort_communicator (bool, opzionale) — Interrompe communicator () prima di interrompere il dataloader. NCCL/Gloo Impostazione predefinita:
Falsecheckpoint_manager (Any, opzionale) — Gestore per la gestione dei checkpoint durante il ripristino. Impostazione predefinita:
Nonecheck_memory_status (bool, opzionale) — Abilita il controllo e la registrazione dello stato della memoria. Impostazione predefinita:
True
Metodi
def __call__(self, fn)
Racchiude una funzione per abilitare le funzionalità di riavvio.
Parametri:
fn (Callable) — La funzione da completare con le funzionalità di riavvio
Restituisce:
Richiamabile: funzione racchiusa con funzionalità di riavvio o funzione originale se disabilitata
Esempio
from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager from hyperpod_checkpointless_training.nemo_plugins.patches import patch_megatron_optimizer from hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector import CheckpointlessCompatibleConnector from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager @HPWrapper( health_check=CudaHealthCheck(), hp_api_factory=HPAgentK8sAPIFactory(), abort_timeout=60.0, checkpoint_manager=CheckpointManager(enable_offload=False), abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), finalize=CheckpointlessFinalizeCleanup(), )def training_function(): # Your training code here pass
Note
Il wrapper deve essere disponibile
torch.distributedQuando
enabled=False, il wrapper diventa un pass-through e restituisce la funzione originale invariataIl wrapper mantiene risorse globali come il monitoraggio dei thread durante tutto il ciclo di vita della formazione
Supporta la profilazione quando viene fornita VizTracer
trace_file_pathSi integra con HyperPod per una gestione coordinata dei guasti nell'ambito della formazione distribuita
HPCallWrapper
class hyperpod_checkpointless_training.inprocess.wrap.HPCallWrapper(wrapper)
Monitora e gestisce lo stato di un Restart Code Block (RCB) durante l'esecuzione.
Questa classe gestisce il ciclo di vita dell'esecuzione di RCB, incluso il rilevamento degli errori, il coordinamento con altri ranghi per i riavvii e le operazioni di pulizia. Gestisce la sincronizzazione distribuita e garantisce un ripristino coerente in tutti i processi di formazione.
Parametri
wrapper (HPWrapper) — Il wrapper principale contenente le impostazioni globali di ripristino durante il processo
Attributes
step_upon_restart (int) — Contatore che tiene traccia dei passaggi dall'ultimo riavvio, utilizzato per determinare la strategia di riavvio
Metodi
def initialize_barrier()
Attendi la sincronizzazione della HyperPod barriera dopo aver riscontrato un'eccezione da RCB.
def start_hp_fault_handling_thread()
Avvia il thread di gestione degli errori per monitorare e coordinare gli errori.
def handle_fn_exception(call_ex)
Elabora le eccezioni dalla funzione di esecuzione o da RCB.
Parametri:
call_ex (Exception) — Eccezione dalla funzione di monitoraggio
def restart(term_ex)
Esegue il gestore di riavvio che include la finalizzazione, la raccolta dei rifiuti e i controlli di integrità.
Parametri:
term_ex (RankShouldRestart) — Eccezione di terminazione che attiva il riavvio
def launch(fn, *a, **kw)
Esegui l'RCB con una corretta gestione delle eccezioni.
Parametri:
fn (Callable) — Funzione da eseguire
a — Argomenti della funzione
kw — Argomenti delle parole chiave della funzione
def run(fn, a, kw)
Ciclo di esecuzione principale che gestisce i riavvii e la sincronizzazione delle barriere.
Parametri:
fn (Callable) — Funzione da eseguire
a — Argomenti della funzione
kw — Argomenti delle parole chiave della funzione
def shutdown()
Gestione degli errori di spegnimento e thread di monitoraggio.
Note
Gestisce automaticamente le
RankShouldRestarteccezioni per un ripristino coordinatoGestisce il tracciamento e gli aborti della memoria, la raccolta dei rifiuti durante i riavvii
Supporta sia le strategie di ripristino in corso che quelle PLR (Process-Level Restart) basate sulla tempistica degli errori
CudaHealthCheck
class hyperpod_checkpointless_training.inprocess.health_check.CudaHealthCheck(timeout=datetime.timedelta(seconds=30))
Assicura che il contesto CUDA per il processo corrente sia in buono stato durante il recupero dall'allenamento senza checkpoint.
Questo controllo di integrità si sincronizza con la GPU per verificare che il contesto CUDA non sia danneggiato dopo un errore di allenamento. Esegue operazioni di sincronizzazione della GPU per rilevare eventuali problemi che potrebbero impedire la corretta ripresa dell'allenamento. Il controllo dello stato viene eseguito dopo la distruzione dei gruppi distribuiti e il completamento della finalizzazione.
Parametri
timeout (datetime.timedelta, opzionale) — Durata del timeout per le operazioni di sincronizzazione della GPU. Impostazione predefinita:
datetime.timedelta(seconds=30)
Metodi
__call__(state, train_ex=None)
Esegui il controllo dello stato di salute CUDA per verificare l'integrità del contesto della GPU.
Parametri:
state (HPState): stato attuale HyperPod contenente informazioni sul rango e sulla distribuzione
train_ex (Eccezione, opzionale) — L'eccezione di allenamento originale che ha attivato il riavvio. Impostazione predefinita:
None
Restituisce:
tuple — Una tupla che contiene
(state, train_ex)invariate le modifiche se il controllo sanitario ha esito positivo
Aumenta:
TimeoutError— Se la sincronizzazione della GPU scade, indica un contesto CUDA potenzialmente danneggiato
Conservazione dello stato: restituisce lo stato e l'eccezione originali invariati se tutti i controlli vengono superati
Esempio
import datetime from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # Create CUDA health check with custom timeout cuda_health_check = CudaHealthCheck( timeout=datetime.timedelta(seconds=60) ) # Use with HPWrapper for fault-tolerant training @HPWrapper( health_check=cuda_health_check, enabled=True ) def training_function(): # Your training code here pass
Note
Utilizza il threading per implementare la protezione da timeout per la sincronizzazione della GPU
Progettato per rilevare contesti CUDA danneggiati che potrebbero impedire la corretta ripresa dell'allenamento
Dovrebbe essere utilizzato come parte della pipeline di tolleranza agli errori negli scenari di formazione distribuiti
HPAgentK8sAPIFactory
class hyperpod_checkpointless_training.inprocess.train_utils.HPAgentK8sAPIFactory()
Classe Factory per la creazione di istanze HPAGentk8sapi che comunicano con l'infrastruttura per il coordinamento distribuito della formazione. HyperPod
Questa factory fornisce un modo standardizzato per creare e configurare oggetti HPagentk8sapi che gestiscono la comunicazione tra i processi di addestramento e il piano di controllo. HyperPod Incapsula la creazione del client socket sottostante e dell'istanza API, garantendo una configurazione coerente tra le diverse parti del sistema di formazione.
Metodi
__call__()
Crea e restituisci un'istanza HPAgentk8SApi configurata per la comunicazione. HyperPod
Restituisce:
HPAGentk8sapi: istanza API configurata per la comunicazione con l'infrastruttura HyperPod
Esempio
from hyperpod_checkpointless_training.inprocess.train_utils import HPAgentK8sAPIFactory from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.inprocess.health_check import CudaHealthCheck # Create the factory hp_api_factory = HPAgentK8sAPIFactory() # Use with HPWrapper for fault-tolerant training hp_wrapper = HPWrapper( hp_api_factory=hp_api_factory, health_check=CudaHealthCheck(), abort_timeout=60.0, enabled=True ) @hp_wrapper def training_function(): # Your distributed training code here pass
Note
Progettato per funzionare senza problemi con l'infrastruttura dell'azienda. HyperPod Kubernetes-based È essenziale per la gestione e il ripristino coordinati dei guasti in scenari di formazione distribuiti
CheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.CheckpointManager( enable_checksum=False, enable_offload=False)
Gestisce i checkpoint in memoria e il ripristino peer-to-peer per una tolleranza agli errori senza checkpoint nella formazione distribuita.
Questa classe fornisce le funzionalità di base per una formazione HyperPod senza checkpoint gestendo i checkpoint dei NeMo modelli in memoria, convalidando la fattibilità del recupero e orchestrando il trasferimento dei checkpoint peer-to-peer tra i ranghi sani e quelli falliti. Elimina la necessità del disco durante il ripristino, riducendo in modo significativo il tempo medio di ripristino (MTTR). I/O
Parametri
enable_checksum (bool, opzionale) — Abilita la convalida del checksum dello stato del modello per i controlli di integrità durante il ripristino. Impostazione predefinita:
Falseenable_offload (bool, opzionale) — Abilita l'offload dei checkpoint dalla GPU alla memoria della CPU per ridurre l'utilizzo della memoria della GPU. Impostazione predefinita:
False
Attributes
global_step (int o None) — Fase di allenamento corrente associata al checkpoint salvato
rng_states (list o None) — Stati del generatore di numeri casuali memorizzati per il recupero deterministico
checksum_manager (MemoryChecksumManager) — Gestore per la convalida del checksum dello stato del modello
parameter_update_lock () — Blocco per coordinare gli aggiornamenti dei parametri durante il ripristino ParameterUpdateLock
Metodi
save_checkpoint(trainer)
Salva il checkpoint del NeMo modello in memoria per un potenziale ripristino senza checkpoint.
Parametri:
trainer (Pytorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Note:
Chiamato CheckpointlessCallback alla fine del batch o durante la gestione delle eccezioni
Crea punti di ripristino senza I/O sovraccarico del disco
Memorizza gli stati completi del modello, dell'ottimizzatore e dello scheduler
delete_checkpoint()
Elimina il checkpoint in memoria ed esegui le operazioni di pulizia.
Note:
Cancella i dati del checkpoint, gli stati RNG e i tensori memorizzati nella cache
Esegue la raccolta dei rifiuti e la pulizia della cache CUDA
Chiamato dopo il ripristino riuscito o quando il checkpoint non è più necessario
try_checkpointless_load(trainer)
Tenta il ripristino senza checkpoint caricando lo stato dai ranghi dei peer ranks.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Restituisce:
dict o None: checkpoint ripristinato in caso di successo, Nessuno se è necessario eseguire il fallback su disco
Note:
Punto di accesso principale per il ripristino senza checkpoint
Convalida la fattibilità del ripristino prima di tentare il trasferimento P2P
Pulisce sempre i checkpoint in memoria dopo il tentativo di ripristino
checkpointless_recovery_feasible(trainer, include_checksum_verification=True)
Determina se è possibile un ripristino senza checkpoint per lo scenario di errore corrente.
Parametri:
trainer (Pytorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
include_checksum_verification (bool, opzionale) — Se includere la convalida del checksum. Impostazione predefinita:
True
Restituisce:
bool — Vero se il ripristino senza checkpoint è fattibile, False altrimenti
Criteri di convalida:
Coerenza globale dei passaggi tra i ranghi più sani
Sono disponibili un numero sufficiente di repliche sane per il ripristino
Integrità del checksum dello stato del modello (se abilitata)
store_rng_states()
Memorizza tutti gli stati del generatore di numeri casuali per il ripristino deterministico.
Note:
Cattura gli stati RNG di Python NumPy PyTorch CPU/GPU, e Megatron
Essenziale per mantenere il determinismo dell'allenamento dopo il recupero
load_rng_states()
Ripristina tutti gli stati RNG per una continuazione deterministica del recupero.
Note:
Ripristina tutti gli stati RNG precedentemente memorizzati
Assicura che l'allenamento continui con sequenze casuali identiche
maybe_offload_checkpoint()
Sposta il checkpoint dalla GPU alla memoria della CPU se l'offload è abilitato.
Note:
Riduce l'utilizzo della memoria della GPU per i modelli di grandi dimensioni
Viene eseguito solo se
enable_offload=TrueMantiene l'accessibilità ai checkpoint per il ripristino
Esempio
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=CheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
Convalida: verifica l'integrità del checkpoint utilizzando i checksum (se abilitati)
Note
Utilizza primitive di comunicazione distribuite per un trasferimento P2P efficiente
Gestisce automaticamente le conversioni di tipo d del tensore e il posizionamento dei dispositivi
MemoryChecksumManager— Gestisce la convalida dell'integrità dello stato del modello
PEFTCheckpointManager
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager.PEFTCheckpointManager( *args, **kwargs)
Gestisce i checkpoint per PEFT (Parameter-Efficient Fine-Tuning) con una gestione separata della base e dell'adattatore per un ripristino ottimizzato senza checkpoint.
Questo gestore di checkpoint specializzato consente di ottimizzare i flussi CheckpointManager di lavoro PEFT separando i pesi del modello base dai parametri dell'adattatore.
Parametri
Eredita tutti i parametri da: CheckpointManager
enable_checksum (bool, opzionale) — Abilita la convalida del checksum dello stato del modello. Impostazione predefinita:
Falseenable_offload (bool, opzionale) — Abilita l'offloading del checkpoint nella memoria della CPU. Impostazione predefinita:
False
Attributi aggiuntivi
params_to_save (set) — Set di nomi di parametri che devono essere salvati come parametri dell'adattatore
base_model_weights (dict o None) — Pesi del modello base memorizzati nella cache, salvati una volta e riutilizzati
base_model_keys_to_extract (list o None) — Chiavi per estrarre i tensori del modello base durante il trasferimento P2P
Metodi
maybe_save_base_model(trainer)
Salva i pesi del modello base una volta, filtrando i parametri dell'adattatore.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Note:
Salva i pesi del modello base solo alla prima chiamata; le chiamate successive non sono operative
Filtra i parametri dell'adattatore per memorizzare solo i pesi del modello base congelati
I pesi del modello base vengono mantenuti per più sessioni di allenamento
save_checkpoint(trainer)
Salva il checkpoint del modello di adattatore NeMo PEFT in memoria per un potenziale ripristino senza checkpoint.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza di Lightning trainer PyTorch
Note:
maybe_save_base_model()Chiama automaticamente se il modello base non è ancora stato salvatoFiltra il checkpoint per includere solo i parametri dell'adattatore e lo stato di allenamento
Riduce in modo significativo le dimensioni dei checkpoint rispetto ai checkpoint del modello completo
try_base_model_checkpointless_load(trainer)
Il modello base di Attempt PEFT soppesa il ripristino senza checkpoint caricando lo stato dai ranghi dei peer rank.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Restituisce:
dict o None: checkpoint del modello base ripristinato in caso di successo, None se è necessario il fallback
Note:
Utilizzato durante l'inizializzazione del modello per recuperare i pesi del modello base
Non elimina i pesi del modello base dopo il ripristino (li conserva per il riutilizzo)
Ottimizzato per scenari di ripristino basati solo sui pesi dei modelli
try_checkpointless_load(trainer)
Tentate che l'adattatore PEFT ponderi il ripristino senza problemi caricando lo stato dai ranghi dei colleghi.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza di Lightning trainer PyTorch
Restituisce:
dict o None — Il checkpoint dell'adattatore è stato ripristinato in caso di successo, Nessuno se è necessario il fallback
Note:
Recupera solo i parametri dell'adattatore, gli stati dell'ottimizzatore e gli scheduler
Carica automaticamente gli stati dell'ottimizzatore e dello scheduler dopo il ripristino riuscito
Pulisce i checkpoint dell'adattatore dopo il tentativo di ripristino
is_adapter_key(key)
Controlla se la chiave state dict appartiene ai parametri dell'adattatore.
Parametri:
key (str o tuple) — Chiave dict di stato da controllare
Restituisce:
bool — Vero se la chiave è il parametro dell'adattatore, False se è il parametro del modello base
Logica di rilevamento:
Controlla se la chiave è
params_to_saveimpostataIdentifica le chiavi contenenti «.adapter». substring
Identifica le chiavi che terminano con «.adapters»
Per le chiavi tuple, controlla se il parametro richiede gradienti
maybe_offload_checkpoint()
Scarica i pesi del modello base dalla GPU alla memoria della CPU.
Note:
Estende il metodo principale per gestire lo scaricamento del peso del modello base
I pesi degli adattatori sono in genere piccoli e non richiedono lo scarico
Imposta un flag interno per tenere traccia dello stato di offload
Note
Progettato specificamente per Parameter-Efficient Fine-Tuning scenari (LoRa, adattatori, ecc.)
Gestisce automaticamente la separazione dei parametri del modello base e dell'adattatore
Esempio
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import PEFTCheckpointManager # Use with HPWrapper for complete fault tolerance @HPWrapper( checkpoint_manager=PEFTCheckpointManager(), enabled=True ) def training_function(): # Training code with automatic checkpointless recovery pass
CheckpointlessAbortManager
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessAbortManager()
Classe Factory per la creazione e la gestione delle composizioni dei componenti di interruzione per una tolleranza ai guasti senza checkpoint.
Questa classe di utilità fornisce metodi statici per creare, personalizzare e gestire le composizioni dei componenti di aborto utilizzate durante la gestione dei guasti durante la formazione senza checkpoint. HyperPod Semplifica la configurazione delle sequenze di interruzione che gestiscono la pulizia dei componenti di formazione distribuiti, dei caricatori di dati e delle risorse specifiche del framework durante il ripristino in caso di errore.
Parametri
Nessuno (tutti i metodi sono statici)
Metodi statici
get_default_checkpointless_abort()
Ottieni l'istanza abort compose predefinita contenente tutti i componenti di abort standard.
Restituisce:
Componi: istanza di interruzione composta predefinita con tutti i componenti di interruzione
Componenti predefiniti:
AbortTransformerEngine() — Pulisce le risorse TransformerEngine
HPCheckpointingAbort() — Gestisce la pulizia del sistema di checkpoint
HPAbortTorchDistributed() — Interrompe le operazioni distribuite PyTorch
HPDataLoaderAbort() — Arresta e pulisce i caricatori di dati
create_custom_abort(abort_instances)
Crea una composizione di interruzione personalizzata con solo le istanze di interruzione specificate.
Parametri:
abort_instances (Abort) — Numero variabile di istanze di aborto da includere nella composizione
Restituisce:
Componi — Nuova istanza di interruzione composta contenente solo i componenti specificati
Aumenta:
ValueError— Se non vengono fornite istanze di interruzione
override_abort(abort_compose, abort_type, new_abort)
Sostituisci un componente di interruzione specifico in un'istanza Compose con un nuovo componente.
Parametri:
abort_compose (Compose) — L'istanza Compose originale da modificare
abort_type (type) — Il tipo di componente di interruzione da sostituire (ad esempio,)
HPCheckpointingAbortnew_abort (Abort) — La nuova istanza di abort da utilizzare come sostituto
Restituisce:
Compose — Nuova istanza Compose con il componente specificato sostituito
Aumenta:
ValueError— Se abort_compose non ha l'attributo 'instances'
Esempio
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.abort import CheckpointlessFinalizeCleanup, CheckpointlessAbortManager # The strategy automatically integrates with HPWrapper @HPWrapper( abort=CheckpointlessAbortManager.get_default_checkpointless_abort(), health_check=CudaHealthCheck(), finalize=CheckpointlessFinalizeCleanup(), enabled=True ) def training_function(): trainer.fit(...)
Note
Le configurazioni personalizzate consentono un controllo preciso sul comportamento di pulizia
Le operazioni di interruzione sono fondamentali per una corretta pulizia delle risorse durante il ripristino dei guasti
CheckpointlessFinalizeCleanup
class hyperpod_checkpointless_training.inprocess.abort.CheckpointlessFinalizeCleanup()
Esegue una pulizia completa dopo il rilevamento dei guasti per prepararsi al ripristino in corso durante l'addestramento senza checkpoint.
Questo gestore di finalizzazione esegue operazioni di pulizia specifiche del framework, tra cui Megatron/TransformerEngine interruzione, pulizia DDP, ricaricamento dei moduli e pulizia della memoria, eliminando i riferimenti ai componenti di addestramento. Garantisce che l'ambiente di formazione venga ripristinato correttamente per il corretto ripristino durante il processo senza richiedere l'interruzione completa del processo.
Parametri
Nessuno
Attributes
trainer (Pytorch_Lightning.trainer o None) — Riferimento all'istanza del trainer Lightning PyTorch
Metodi
__call__(*a, **kw)
Esegui operazioni di pulizia complete per la preparazione del ripristino durante il processo.
Parametri:
a — Argomenti posizionali variabili (ereditati dall'interfaccia Finalize)
kw — Argomenti variabili relativi alle parole chiave (ereditati dall'interfaccia Finalize)
Operazioni di pulizia:
Megatron Framework Cleanup: chiamate
abort_megatron()per ripulire le risorse Megatron-specificTransformerEngine Cleanup: chiamate
abort_te()per ripulire le risorse TransformerEngineRoPE Cleanup: chiamate
cleanup_rope()per ripulire le risorse di incorporamento della posizione rotanteDDP Cleanup: chiamate per ripulire le risorse
cleanup_ddp()DistributedDataParallelModule Reloading: chiamate
reload_megatron_and_te()per ricaricare i moduli del frameworkPulizia del modulo Lightning: cancella facoltativamente il modulo Lightning per ridurre la memoria della GPU
Memory Cleanup: elimina i riferimenti ai componenti di addestramento per liberare memoria
register_attributes(trainer)
Registra l'istanza del trainer per utilizzarla durante le operazioni di pulizia.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza di Lightning trainer da registrare PyTorch
Integrazione con CheckpointlessCallback
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( ... finalize=CheckpointlessFinalizeCleanup(), ) def training_function(): trainer.fit(...)
Note
Le operazioni di pulizia vengono eseguite in un ordine specifico per evitare problemi di dipendenza
La pulizia della memoria utilizza l'introspezione della raccolta dei rifiuti per trovare gli oggetti di destinazione
Tutte le operazioni di pulizia sono progettate per essere idempotenti e sicure da riprovare
CheckpointlessMegatronStrategy
class hyperpod_checkpointless_training.nemo_plugins.megatron_strategy.CheckpointlessMegatronStrategy(*args, **kwargs)
NeMo Strategia Megatron con funzionalità integrate di ripristino senza checkpoint per una formazione distribuita con tolleranza ai guasti.
Tieni presente che l'addestramento senza checkpoint deve essere almeno 2 in num_distributed_optimizer_instances modo da garantire la replica dell'ottimizzatore. La strategia si occupa anche della registrazione degli attributi essenziali e dell'inizializzazione dei gruppi di processi.
Parametri
Eredita tutti i parametri da: MegatronStrategy
NeMo MegatronStrategy Parametri di inizializzazione standard
Opzioni di configurazione della formazione distribuita
Impostazioni del parallelismo del modello
Attributes
base_store (torch.distributed.TCPStore o None) — Archivio distribuito per il coordinamento dei gruppi di processi
Metodi
setup(trainer)
Inizializza la strategia e registra i componenti di tolleranza agli errori con il trainer.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Operazioni di configurazione:
Parent Setup: richiama la MegatronStrategy configurazione principale
Fault Injection Registration: registra HPFaultInjectionCallback gli hook, se presenti
Finalizza la registrazione: registra il trainer con i gestori di finalize cleanup
Annulla registrazione: registra il trainer con i gestori di aborti che lo supportano
setup_distributed()
Inizializza il gruppo di processi utilizzando TcpStore con prefisso o connessione rootless.
load_model_state_dict(checkpoint, strict=True)
Carica il modello state dict con compatibilità di ripristino senza checkpointless.
Parametri:
checkpoint (Mapping [str, Any]) — Dizionario Checkpoint contenente lo stato del modello
strict (bool, optional) — Se applicare rigorosamente la corrispondenza delle chiavi state dict. Impostazione predefinita:
True
get_wrapper()
Ottieni l' HPCallWrapper istanza per il coordinamento della tolleranza agli errori.
Restituisce:
HPCallWrapper— L'istanza wrapper collegata al trainer per la tolleranza agli errori
is_peft()
Controlla se PEFT (Parameter-Efficient Fine-Tuning) è abilitato nella configurazione di addestramento controllando i callback PEFT
Restituisce:
bool — Vero se è presente il callback PEFT, False in caso contrario
teardown()
Sostituisci lo smontaggio nativo di PyTorch Lightning per delegare la pulizia ai gestori di aborti.
Esempio
from hyperpod_checkpointless_training.inprocess.wrap import HPWrapper # The strategy automatically integrates with HPWrapper @HPWrapper( checkpoint_manager=checkpoint_manager, enabled=True ) def training_function(): trainer = pl.Trainer(strategy=CheckpointlessMegatronStrategy()) trainer.fit(model, datamodule)
CheckpointlessCallback
class hyperpod_checkpointless_training.nemo_plugins.callbacks.CheckpointlessCallback( enable_inprocess=False, enable_checkpointless=False, enable_checksum=False, clean_tensor_hook=False, clean_lightning_module=False)
Lightning callback che integra la formazione con il sistema di tolleranza ai guasti di checkpointless training. NeMo
Questo callback gestisce il tracciamento dei passaggi, il salvataggio dei checkpoint e il coordinamento dell'aggiornamento dei parametri per le funzionalità di ripristino durante il processo. Funge da punto di integrazione principale tra i cicli di formazione PyTorch Lightning e i meccanismi di addestramento HyperPod senza checkpoint, coordinando le operazioni di tolleranza agli errori durante l'intero ciclo di vita della formazione.
Parametri
enable_inprocess (bool, opzionale) — Abilita le funzionalità di ripristino durante il processo. Impostazione predefinita:
Falseenable_checkpointless (bool, opzionale) — Abilita il ripristino senza checkpointless (richiesto).
enable_inprocess=TrueImpostazione predefinita:Falseenable_checksum (bool, opzionale) — Abilita la convalida del checksum dello stato del modello (richiesto).
enable_checkpointless=TrueImpostazione predefinita:Falseclean_tensor_hook (bool, opzionale) — Elimina gli hook tensoriali da tutti i tensori della GPU durante la pulizia (operazione costosa). Impostazione predefinita:
Falseclean_lightning_module (bool, opzionale) — Abilita la pulizia del modulo Lightning per liberare memoria della GPU dopo ogni riavvio. Impostazione predefinita:
False
Attributes
tried_adapter_checkpointless (bool) — Contrassegna per verificare se è stato tentato il ripristino senza checkpointless dell'adattatore
Metodi
get_wrapper_from_trainer(trainer)
Ottieni l'istanza dal HPCallWrapper trainer per il coordinamento della tolleranza ai guasti.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Restituisce:
HPCallWrapper— L'istanza wrapper per le operazioni di tolleranza ai guasti
on_train_batch_start(trainer, pl_module, batch, batch_idx, *args, **kwargs)
Richiamato all'inizio di ogni batch di allenamento per gestire il monitoraggio e il recupero delle fasi.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza di Lightning trainer PyTorch
pl_module (pytorch_lightning). LightningModule) — Modulo Lightning in fase di addestramento
batch: dati correnti relativi al batch di addestramento
batch_idx (int) — Indice del batch corrente
args — Argomenti posizionali aggiuntivi
kwargs — Argomenti aggiuntivi relativi alle parole chiave
on_train_batch_end(trainer, pl_module, outputs, batch, batch_idx)
Rilascia il blocco di aggiornamento dei parametri alla fine di ogni batch di addestramento.
Parametri:
trainer (Pytorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
pl_module (pytorch_lightning). LightningModule) — Modulo Lightning in fase di addestramento
outputs (STEP_OUTPUT) — Uscite della fase di addestramento
batch (Any) — Dati correnti del batch di addestramento
batch_idx (int) — Indice del batch corrente
Note:
La tempistica di rilascio del blocco garantisce che il ripristino senza checkpoint possa procedere dopo il completamento degli aggiornamenti dei parametri
Viene eseguito solo quando entrambi i valori sono impostati su True
enable_inprocessenable_checkpointless
get_peft_callback(trainer)
Recupera il callback PEFT dall'elenco dei callback del trainer.
Parametri:
trainer (Pytorch_Lightning.trainer) — Istanza del trainer Lightning PyTorch
Restituisce:
PEFT o None: istanza di callback PEFT se trovata, nessuna in caso contrario
_try_adapter_checkpointless_restore(trainer, params_to_save)
Tenta il ripristino senza checkpoint dei parametri dell'adattatore PEFT.
Parametri:
trainer (PyTorch_Lightning.trainer) — Istanza di Lightning trainer PyTorch
params_to_save (set) — Set di nomi di parametri da salvare come parametri dell'adattatore
Note:
Viene eseguito solo una volta per sessione di allenamento (controllata da flag)
tried_adapter_checkpointlessConfigura il gestore dei punti di controllo con le informazioni sui parametri dell'adattatore
Esempio
from hyperpod_checkpointless_training.nemo_plugins.callbacks import CheckpointlessCallback from hyperpod_checkpointless_training.nemo_plugins.checkpoint_manager import CheckpointManager import pytorch_lightning as pl # Create checkpoint manager checkpoint_manager = CheckpointManager( enable_checksum=True, enable_offload=True ) # Create checkpointless callback with full fault tolerance checkpointless_callback = CheckpointlessCallback( enable_inprocess=True, enable_checkpointless=True, enable_checksum=True, clean_tensor_hook=True, clean_lightning_module=True ) # Use with PyTorch Lightning trainer trainer = pl.Trainer( callbacks=[checkpointless_callback], strategy=CheckpointlessMegatronStrategy() ) # Training with fault tolerance trainer.fit(model, datamodule=data_module)
Gestione della memoria
clean_tensor_hook: rimuove i ganci tensoriali durante la pulizia (costoso ma completo)
clean_lightning_module: libera memoria GPU del modulo Lightning durante i riavvii
Entrambe le opzioni aiutano a ridurre l'ingombro di memoria durante il ripristino dei guasti
Coordinate con ParameterUpdateLock per il tracciamento degli aggiornamenti dei parametri thread-safe
CheckpointlessCompatibleConnector
class hyperpod_checkpointless_training.nemo_plugins.checkpoint_connector.CheckpointlessCompatibleConnector()
PyTorch Connettore Lightning Checkpoint che integra il ripristino senza checkpoint con il tradizionale caricamento dei checkpoint basato su disco.
Questo connettore estende quello di PyTorch Lightning per fornire una perfetta integrazione tra il ripristino senza checkpoint e _CheckpointConnector il ripristino dei checkpoint standard. Tenta innanzitutto il ripristino senza checkpoint, quindi torna al caricamento del checkpoint basato su disco se il ripristino senza checkpoint non è fattibile o fallisce.
Parametri
Eredita tutti i parametri da _ CheckpointConnector
Metodi
resume_start(checkpoint_path=None)
Tentativo di precaricare il checkpoint con priorità di ripristino senza checkpointless.
Parametri:
checkpoint_path (str o None, opzionale) — Percorso verso il checkpoint del disco per il fallback. Impostazione predefinita:
None
resume_end()
Completa il processo di caricamento del checkpoint ed esegui le operazioni successive al caricamento.
Note
Estende la
_CheckpointConnectorclasse interna di PyTorch Lightning con il supporto per il ripristino senza checkpointMantiene la piena compatibilità con i flussi di lavoro Lightning checkpoint standard PyTorch
CheckpointlessAutoResume
class hyperpod_checkpointless_training.nemo_plugins.resume.CheckpointlessAutoResume()
Estende NeMo la funzionalità AutoResume con configurazione ritardata per consentire la convalida del ripristino senza checkpoint prima della risoluzione del percorso di checkpoint.
Questa classe implementa una strategia di inizializzazione in due fasi che consente la convalida del ripristino senza checkpoint prima di tornare al tradizionale caricamento dei checkpoint basato su disco. Ritarda in modo condizionale la AutoResume configurazione per impedire la risoluzione prematura del percorso dei checkpoint, permettendo di verificare innanzitutto se il ripristino peer-to-peer senza checkpoint è fattibile. CheckpointManager
Parametri
Eredita tutti i parametri da AutoResume
Metodi
setup(trainer, model=None, force_setup=False)
Ritarda la AutoResume configurazione in modo condizionale per consentire la convalida del ripristino senza checkpoint.
Parametri:
trainer (Pytorch_Lightning.trainer o lightning.Fabric.fabric) — Lightning trainer o istanza Fabric PyTorch
model (opzionale) — Istanza del modello per la configurazione. Impostazione predefinita:
Noneforce_setup (bool, opzionale) — Se True, ignora il ritardo ed esegui immediatamente la configurazione. AutoResume Impostazione predefinita:
False
Esempio
from hyperpod_checkpointless_training.nemo_plugins.resume import CheckpointlessAutoResume from hyperpod_checkpointless_training.nemo_plugins.megatron_strategy import CheckpointlessMegatronStrategy import pytorch_lightning as pl # Create trainer with checkpointless auto-resume trainer = pl.Trainer( strategy=CheckpointlessMegatronStrategy(), resume=CheckpointlessAutoResume() )
Note
La AutoResume classe NeMo di Extends con meccanismo di ritardo per consentire il ripristino senza checkpoint
Funziona in combinazione con
CheckpointlessCompatibleConnectorper un flusso di lavoro di ripristino completo
