Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Utilizzo dell'allenamento elastico in Amazon SageMaker HyperPod
Elastic Training è una nuova SageMaker HyperPod funzionalità di Amazon che ridimensiona automaticamente i lavori di formazione in base alla disponibilità delle risorse di calcolo e alla priorità del carico di lavoro. I lavori di formazione elastica possono iniziare con le risorse di calcolo minime necessarie per l'addestramento dei modelli e scalare dinamicamente verso l'alto o verso il basso attraverso il checkpoint e la ripresa automatici su diverse configurazioni di nodi (a dimensione mondiale). La scalabilità si ottiene regolando automaticamente il numero di repliche parallele dei dati. Durante i periodi di utilizzo elevato del cluster, è possibile configurare processi di formazione elastici in modo da ridurli automaticamente in risposta alle richieste di risorse provenienti da lavori con priorità più elevata, liberando l'elaborazione per carichi di lavoro critici. Quando le risorse si liberano durante i periodi non di punta, i job di formazione elastica vengono ridimensionati automaticamente verso l'alto per accelerare la formazione, per poi ridurli quando i carichi di lavoro con priorità più alta richiedono nuovamente risorse.
Elastic Training si basa sull'operatore addetto alla HyperPod formazione e integra i seguenti componenti:
-
Amazon SageMaker HyperPod Task Governance per l'accodamento, la prioritizzazione e la pianificazione dei lavori
-
PyTorch Distributed Checkpoint (DCP)
per una gestione scalabile dello stato e dei checkpoint, come DCP
Framework supportati
-
PyTorch con Distributed Data Parallel (DDP) e Fully Sharded Data Parallel (FSDP)
-
PyTorch Checkpoint distribuito (DCP)
Prerequisiti
SageMaker HyperPod Cluster EKS
È necessario disporre di un SageMaker HyperPod cluster in esecuzione con orchestrazione Amazon EKS. Per informazioni sulla creazione di un cluster HyperPod EKS, consulta:
SageMaker HyperPod Operatore di formazione
Elastic Training è supportato nella versione 1.2 e successive di training operator.
Per installare l'operatore di formazione come componente aggiuntivo EKS, vedi: https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-eks-operator-install.html
(Consigliato) Installa e configura Task Governance e Kueue
Consigliamo di installare e configurare Kueue tramite HyperPod Task Governance per specificare le priorità dei carichi di lavoro con un training elastico. Kueue offre una gestione più efficace del carico di lavoro con code, prioritizzazione, pianificazione dei gruppi, monitoraggio delle risorse e prelazione, essenziali per operare in ambienti di formazione multi-tenant.
-
La pianificazione in gruppo garantisce che tutti i moduli necessari per un lavoro di formazione inizino insieme. In questo modo si evitano situazioni in cui alcuni pod vengono avviati mentre altri rimangono in sospeso, il che potrebbe causare uno spreco di risorse.
-
La priorità delicata consente ai lavori elastici con priorità più bassa di destinare risorse a carichi di lavoro con priorità più elevata. I lavori elastici possono essere ridimensionati in modo graduale senza essere sfrattati con la forza, migliorando la stabilità complessiva del cluster.
Consigliamo di configurare i seguenti componenti Kueue:
-
PriorityClasses per definire l'importanza relativa del lavoro
-
ClusterQueues per gestire la condivisione globale delle risorse e le quote tra team o carichi di lavoro
-
LocalQueues per indirizzare i lavori dai singoli namespace a quelli appropriati ClusterQueue
Per configurazioni più avanzate, puoi anche incorporare:
-
Fair-share politiche per bilanciare l'utilizzo delle risorse tra più team
-
Regole di priorità personalizzate per far rispettare gli SLA organizzativi o il controllo dei costi
Fai riferimento a:
(Consigliato) Imposta i namespace utente e le quote di risorse
Quando si implementa questa funzionalità su Amazon EKS, consigliamo di applicare una serie di configurazioni di base a livello di cluster per garantire l'isolamento, l'equità delle risorse e la coerenza operativa tra i team.
Configurazione dello spazio dei nomi e degli accessi
Organizza i tuoi carichi di lavoro utilizzando namespace separati per ogni team o progetto. Ciò consente di applicare un isolamento e una governance granulari. Consigliamo inoltre di configurare la mappatura RBAC da AWS IAM a Kubernetes per associare singoli utenti o ruoli IAM ai namespace corrispondenti.
Le pratiche chiave includono:
-
Mappa i ruoli IAM sugli account di servizio Kubernetes utilizzando IAM Roles for Service Accounts (IRSA) quando i carichi di lavoro richiedono autorizzazioni. AWS https://docs.aws.amazon.com/eks/latest/userguide/access-entries.html
-
Applica le politiche RBAC per limitare gli utenti solo ai namespace designati (ad esempio,
Role/RoleBindinganziché alle autorizzazioni a livello di cluster).
Vincoli relativi alle risorse e al calcolo
Per prevenire la contesa delle risorse e garantire una pianificazione equa tra i team, applica quote e limiti a livello di namespace:
-
ResourceQuotas per limitare il numero aggregato di CPU, memoria, storage e oggetti (pod, PVC, servizi, ecc.).
-
LimitRanges per applicare i limiti predefiniti e massimi di CPU e memoria per pod o per contenitore.
-
PodDisruptionBudgets (PDB) se necessario per definire le aspettative di resilienza.
-
Facoltativo: vincoli di Namespace-level coda (ad esempio, tramite Task Governance o Kueue) per impedire agli utenti di inviare lavori in modo eccessivo.
Questi vincoli aiutano a mantenere la stabilità del cluster e supportano una pianificazione prevedibile per carichi di lavoro di formazione distribuiti.
Auto-scaling
SageMaker HyperPod su EKS supporta la scalabilità automatica dei cluster tramite Karpenter. Quando Karpenter o un fornitore di risorse simile vengono utilizzati insieme alla formazione elastica, il cluster e il lavoro di formazione elastica possono aumentare automaticamente dopo l'invio di un lavoro di formazione elastica. Questo perché elastic training operator adotta un approccio avido, richiede sempre più risorse di calcolo rispetto alle risorse di calcolo disponibili fino a raggiungere il limite massimo stabilito dal lavoro. Ciò si verifica perché l'operatore di elastic training richiede continuamente risorse aggiuntive come parte dell'esecuzione elastica del lavoro, il che può attivare il provisioning dei nodi. I fornitori continui di risorse come Karpenter soddisferanno le richieste scalando il cluster di calcolo.
Per mantenere queste scalabilità prevedibili e sotto controllo, consigliamo di configurare a livello di ResourceQuotas namespace negli spazi dei nomi in cui vengono creati i job di training elastici. ResourceQuotas aiutano a limitare il numero massimo di risorse che i job possono richiedere, prevenendo la crescita illimitata dei cluster e permettendo comunque un comportamento elastico entro limiti definiti.
Ad esempio, una istanza da ResourceQuota 8 ml.p5.48xlarge avrà il seguente formato:
apiVersion: v1 kind: ResourceQuota metadata: name: <quota-name> namespace: <namespace-name> spec: hard: nvidia.com/gpu: "64" vpc.amazonaws.com/efa: "256" requests.cpu: "1536" requests.memory: "5120Gi" limits.cpu: "1536" limits.memory: "5120Gi"
Costruisci un contenitore di formazione
HyperPod l'operatore di formazione lavora con un programma di PyTorch avvio personalizzato fornito tramite il pacchetto python di HyperPod Elastic Agent () https://www.piwheels.org/project/hyperpod-elastic-agent/torchrun comando con hyperpodrun to launch training. Per maggiori dettagli, consulta:
Un esempio di contenitore di formazione:
FROM ... ... RUN pip install hyperpod-elastic-agent ENTRYPOINT ["entrypoint.sh"] # entrypoint.sh ... hyperpodrun --nnodes=node_count --nproc-per-node=proc_count \ --rdzv-backend hyperpod \ # Optional ... # Other torchrun args # pre-traing arg_group --pre-train-script pre.sh --pre-train-args "pre_1 pre_2 pre_3" \ # post-train arg_group --post-train-script post.sh --post-train-args "post_1 post_2 post_3" \ training.py --script-args
Modifica del codice di addestramento
SageMaker HyperPod fornisce un set di ricette già configurate per l'esecuzione con Elastic Policy.
Per abilitare l'allenamento elastico per script di PyTorch allenamento personalizzati, dovrai apportare piccole modifiche al ciclo di allenamento. Questa guida illustra le modifiche necessarie per garantire che il processo di formazione risponda agli eventi di scalabilità elastica che si verificano quando la disponibilità delle risorse di calcolo cambia. Durante tutti gli eventi elastici (ad esempio, i nodi sono disponibili o i nodi vengono bloccati), il job di formazione riceve un segnale di evento elastico che viene utilizzato per coordinare uno spegnimento regolare salvando un checkpoint e riprendere l'allenamento riavviando da quel checkpoint salvato con una nuova configurazione mondiale. Per abilitare l'allenamento elastico con script di allenamento personalizzati, devi:
Rilevare eventi Elastic Scaling
Nel ciclo di allenamento, verifica la presenza di eventi elastici durante ogni iterazione:
from hyperpod_elastic_agent.elastic_event_handler import elastic_event_detected def train_epoch(model, dataloader, optimizer, args): for batch_idx, batch_data in enumerate(dataloader): # Forward and backward pass loss = model(batch_data).loss loss.backward() optimizer.step() optimizer.zero_grad() # Handle checkpointing and elastic scaling should_checkpoint = (batch_idx + 1) % args.checkpoint_freq == 0 elastic_event = elastic_event_detected() # Save checkpoint if scaling-up or scaling down job if should_checkpoint or elastic_event: save_checkpoint(model, optimizer, scheduler, checkpoint_dir=args.checkpoint_dir, step=global_step) if elastic_event: print("Elastic scaling event detected. Checkpoint saved.") return
Implementa Checkpoint Saving e Checkpoint Loading
Nota: consigliamo di utilizzare PyTorch Distributed Checkpoint (DCP) per salvare gli stati del modello e dell'ottimizzatore, poiché DCP supporta la ripresa da un checkpoint con dimensioni mondiali diverse. Altri formati di checkpoint potrebbero non supportare il caricamento dei checkpoint su mondi di dimensioni diverse, nel qual caso dovrai implementare una logica personalizzata per gestire le modifiche dinamiche delle dimensioni mondiali.
import torch.distributed.checkpoint as dcp from torch.distributed.checkpoint.state_dict import get_state_dict, set_state_dict def save_checkpoint(model, optimizer, lr_scheduler, user_content, checkpoint_path): """Save checkpoint using DCP for elastic training.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler, **user_content } dcp.save( state_dict=state_dict, storage_writer=dcp.FileSystemWriter(checkpoint_path) ) def load_checkpoint(model, optimizer, lr_scheduler, checkpoint_path): """Load checkpoint using DCP with automatic resharding.""" state_dict = { "model": model, "optimizer": optimizer, "lr_scheduler": lr_scheduler } dcp.load( state_dict=state_dict, storage_reader=dcp.FileSystemReader(checkpoint_path) ) return model, optimizer, lr_scheduler
(Facoltativo) Usa dataloader stateful
Se ti stai allenando solo per una singola epoca (ad esempio, un singolo passaggio attraverso l'intero set di dati), il modello deve vedere ogni campione di dati esattamente una volta. Se il processo di addestramento si interrompe a metà epoca e riprende con una dimensione mondiale diversa, i campioni di dati precedentemente elaborati verranno ripetuti se lo stato del dataloader non è persistente. Un dataloader con stato impedisce che ciò accada salvando e ripristinando la posizione del dataloader, assicurando che le esecuzioni riprese continuino dopo l'evento di scalabilità elastica senza rielaborare alcun campione. Consigliamo di utilizzare StatefulDataLoadertorch.utils.data.DataLoader dati. state_dict() load_state_dict()
Invio di lavori di formazione elastici
HyperPod l'operatore di formazione definisce un nuovo tipo di risorsa -hyperpodpytorchjob. Elastic Training estende questo tipo di risorsa e aggiunge i campi evidenziati di seguito:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 1 maxReplicas: 4 # Increment amount of pods in fixed-size groups # Amount of pods will be equal to minReplicas + N * replicaIncrementStep replicaIncrementStep: 1 # ... or Provide an exact amount of pods that required for training replicaDiscreteValues: [2,4,8] # How long traing operator wait job to save checkpoint and exit during # scaling events. Job will be force-stopped after this period of time gracefulShutdownTimeoutInSeconds: 600 # When scaling event is detected: # how long job controller waits before initiate scale-up. # Some delay can prevent from frequent scale-ups and scale-downs scalingTimeoutInSeconds: 60 # In case of faults, specify how long elastic training should wait for # recovery, before triggering a scale-down faultyScaleDownTimeoutInSeconds: 30 ... replicaSpecs: - name: pods replicas: 4 # Initial replica count maxReplicas: 8 # Max for this replica spec (should match elasticPolicy.maxReplicas) ...
Usare kubectl
Successivamente puoi avviare l'allenamento elastico con il seguente comando.
kubectl apply -f elastic-training-job.yaml
Usare SageMaker le ricette
I lavori di Elastic Training possono essere avviati tramite SageMaker HyperPod ricette
Nota
Abbiamo incluso 46 ricette elastiche per i lavori SFO e DPO su Hyperpod Recipe. Gli utenti possono avviare questi lavori con una sola modifica di riga sullo script di avvio statico esistente:
++recipes.elastic_policy.is_elastic=true
Oltre alle ricette statiche, le ricette elastiche aggiungono i seguenti campi per definire i comportamenti elastici:
Politica elastica
Il elastic_policy campo definisce la configurazione a livello di lavoro per il job di elastic training, ha le seguenti configurazioni:
-
is_elastic:bool- se questo lavoro è un lavoro elastico -
min_nodes:int- il numero minimo di nodi utilizzati per l'allenamento elastico -
max_nodes:int- il numero massimo di nodi utilizzati per l'allenamento elastico -
replica_increment_step:int- incrementa la quantità di pod in gruppi a dimensione fissa, questo campo si esclude a vicenda per quello che definiremo più avanti.scale_config -
use_graceful_shutdown:bool- se si utilizza Graceful Shutdown durante gli eventi di ridimensionamento, l'impostazione predefinita è.true -
scaling_timeout:int- il tempo di attesa in secondi durante l'evento di ridimensionamento prima del timeout -
graceful_shutdown_timeout:int- il tempo di attesa per lo spegnimento graduale
Di seguito è riportato un esempio di definizione di questo campo, che puoi trovare anche nel repository Hyperpod Recipe in recipe: recipes_collection/recipes/fine-tuning/llama/llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.yaml
<static recipe> ... elastic_policy: is_elastic: true min_nodes: 1 max_nodes: 16 use_graceful_shutdown: true scaling_timeout: 600 graceful_shutdown_timeout: 600
Config della scala
Il scale_config campo definisce le configurazioni prioritarie su ogni scala specifica. È un dizionario chiave-valore, dove key è un numero intero che rappresenta la scala di destinazione e value è un sottoinsieme della ricetta base. Su <key> larga scala, utilizziamo il <value> per aggiornare le configurazioni specifiche nella ricetta. base/static Di seguito viene mostrato un esempio di questo campo:
scale_config: ... 2: trainer: num_nodes: 2 training_config: training_args: train_batch_size: 128 micro_train_batch_size: 8 learning_rate: 0.0004 3: trainer: num_nodes: 3 training_config: training_args: train_batch_size: 128 learning_rate: 0.0004 uneven_batch: use_uneven_batch: true num_dp_groups_with_small_batch_size: 16 small_local_batch_size: 5 large_local_batch_size: 6 ...
La configurazione precedente definisce la configurazione di addestramento su scala 2 e 3. In entrambi i casi, utilizziamo il tasso di apprendimento4e-4, la dimensione del batch di128. Ma sulla scala 2, utilizziamo un numero micro_train_batch_size di 8, mentre sulla scala 3, utilizziamo una dimensione del batch non uniforme poiché la dimensione del batch del treno non può essere divisa equamente su 3 nodi.
Dimensione irregolare del Batch
Questo è un campo per definire il comportamento di distribuzione dei batch quando la dimensione globale del batch non può essere divisa equamente per il numero di ranghi. Non è specifico per l'allenamento elastico, ma è un fattore abilitante per una maggiore granularità di scalabilità.
-
use_uneven_batch:bool- se si utilizza una distribuzione non uniforme dei lotti -
num_dp_groups_with_small_batch_size:int- nella distribuzione non uniforme dei lotti, alcuni ranghi utilizzano lotti locali di dimensioni inferiori, mentre altri utilizzano lotti di dimensioni maggiori. La dimensione globale del batch deve essere uguale asmall_local_batch_size * num_dp_groups_with_small_batch_size + (world_size-num_dp_groups_with_small_batch_size) * large_local_batch_size -
small_local_batch_size:int- questo valore è la dimensione del batch locale più piccola -
large_local_batch_size:int- questo valore è la dimensione del batch locale più grande
Monitora la formazione su MLFlow
I lavori di creazione di ricette Hyperpod supportano l'osservabilità tramite MLFlow. Gli utenti possono specificare le configurazioni MLFlow nella ricetta:
training_config: mlflow: tracking_uri: "<local_file_path or MLflow server URL>" run_id: "<MLflow run ID>" experiment_name: "<MLflow experiment name, e.g. llama_exps>" run_name: "<run name, e.g. llama3.1_8b>"
Queste configurazioni sono mappate sulla configurazione MLFlow corrispondente.
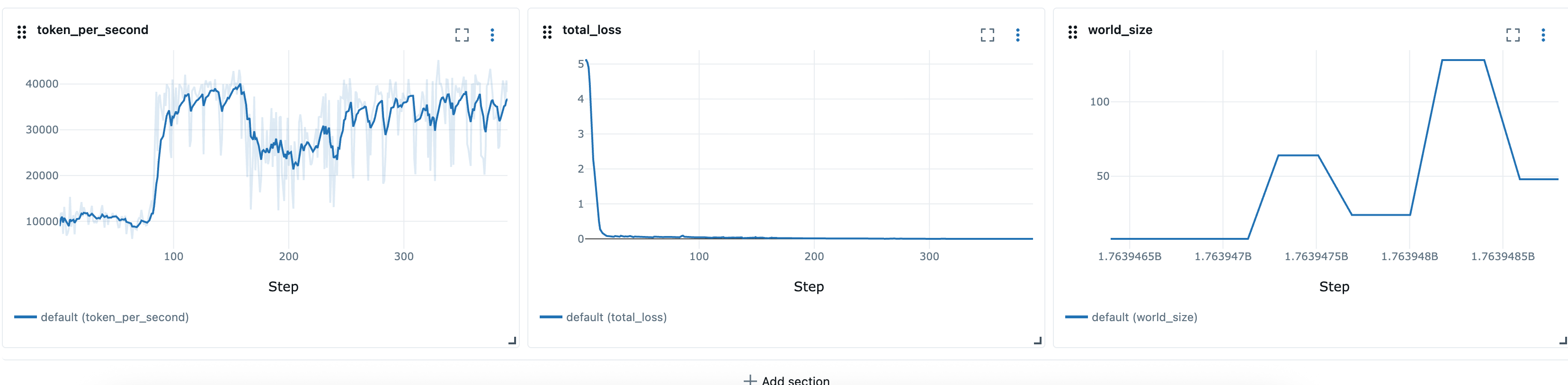
Dopo aver definito le ricette elastiche, possiamo utilizzare gli script di avvio, ad esempio launcher_scripts/llama/run_llmft_llama3_1_8b_instruct_seq4k_gpu_sft_lora.sh per avviare un processo di allenamento elastico. È simile all'avvio di un lavoro statico utilizzando la ricetta Hyperpod.
Nota
Il processo di formazione elastico di Recipe Support riprende automaticamente dai checkpoint più recenti, tuttavia, per impostazione predefinita, ogni riavvio crea una nuova directory di formazione. Per consentire la corretta ripresa dall'ultimo checkpoint, dobbiamo assicurarci che venga riutilizzata la stessa directory di formazione. Questo può essere fatto impostando
recipes.training_config.training_args.override_training_dir=true
Use-case esempi e limitazioni
Scale-up quando sono disponibili più risorse
Quando più risorse diventano disponibili nel cluster (ad esempio, vengono completati altri carichi di lavoro). Durante questo evento, il training controller aumenterà automaticamente il processo di formazione. Questo comportamento è spiegato di seguito.
Per simulare una situazione in cui diventano disponibili più risorse, possiamo inviare un lavoro ad alta priorità e quindi rilasciare nuovamente le risorse eliminando il lavoro ad alta priorità.
# Submit a high-priority job on your cluster. As a result of this command # resources will not be available for elastic training kubectl apply -f high_prioriy_job.yaml # Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Wait for training to start.... # Delete high priority job. This command will make additional resources available for # elastic training kubectl delete -f high_prioriy_job.yaml # Observe the scale-up of elastic job
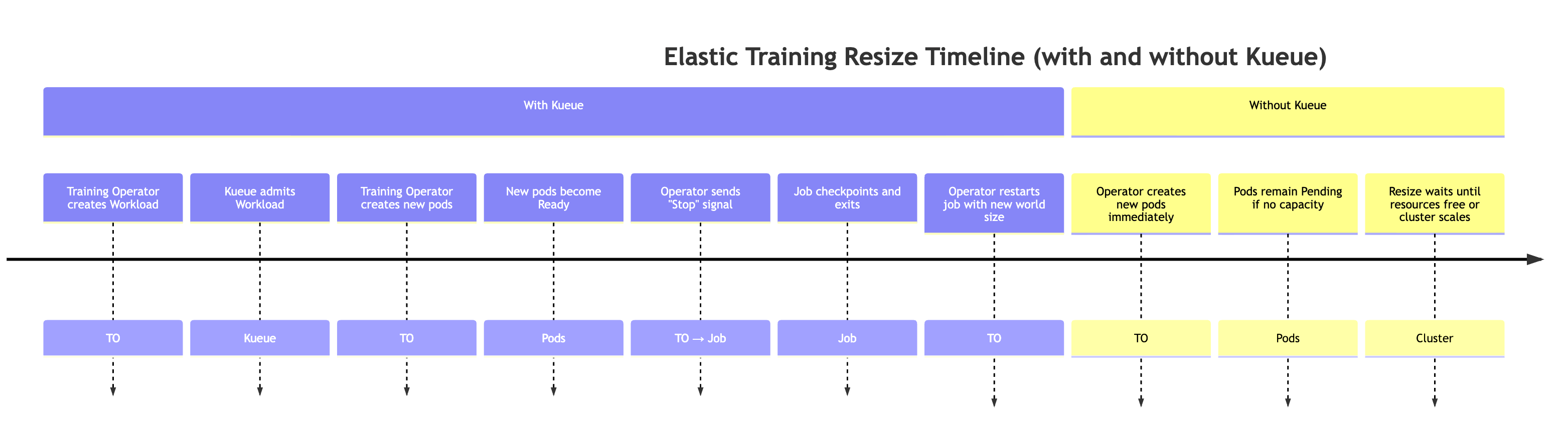
Comportamento previsto:
-
L'operatore di formazione crea un carico di lavoro Kueue Quando un lavoro di formazione elastico richiede una modifica delle dimensioni mondiali, l'operatore di formazione genera un oggetto Kueue Workload aggiuntivo che rappresenta i nuovi requisiti di risorse.
-
Kueue ammette il carico di lavoro Kueue valuta la richiesta in base alle risorse disponibili, alle priorità e alle politiche di coda. Una volta approvato, il carico di lavoro viene ammesso.
-
L'operatore addetto all'addestramento crea i pod aggiuntivi Al momento dell'ammissione, l'operatore lancia i pod aggiuntivi necessari per raggiungere la nuova dimensione mondiale.
-
Quando i nuovi pod sono pronti, l'operatore addetto all'addestramento invia uno speciale segnale elastico di evento al training script.
-
Il processo di addestramento esegue il checkpoint, per prepararsi a un arresto regolare Il processo di addestramento verifica periodicamente la presenza del segnale elastico dell'evento chiamando la funzione elastic_event_detected (). Una volta rilevato, avvia un checkpoint. Una volta completato con successo il checkpoint, il processo di addestramento termina senza problemi.
-
L'operatore addetto alla formazione riavvia il lavoro con la nuova dimensione mondiale L'operatore attende la chiusura di tutti i processi, quindi riavvia il processo di formazione utilizzando la dimensione mondiale aggiornata e il checkpoint più recente.
Nota: quando Kueue non viene utilizzato, l'operatore addetto alla formazione salta i primi due passaggi. Tenta immediatamente di creare i pod aggiuntivi necessari per le nuove dimensioni del mondo. Se nel cluster non sono disponibili risorse sufficienti, questi pod rimarranno in sospeso fino a quando la capacità non sarà disponibile.
Prelazione per mansioni ad alta priorità
I lavori elastici possono essere ridimensionati automaticamente quando un lavoro ad alta priorità richiede risorse. Per simulare questo comportamento, puoi inviare un lavoro di formazione elastico, che utilizzi il numero massimo di risorse disponibili dall'inizio della formazione, inviare un lavoro ad alta priorità e osservare il comportamento di prelazione.
# Submit an elastic job with normal priority kubectl apply -f hyperpod_job_with_elasticity.yaml # Submit a high-priority job on your cluster. As a result of this command # some amount of resources will be kubectl apply -f high_prioriy_job.yaml # Observe scale-down behaviour
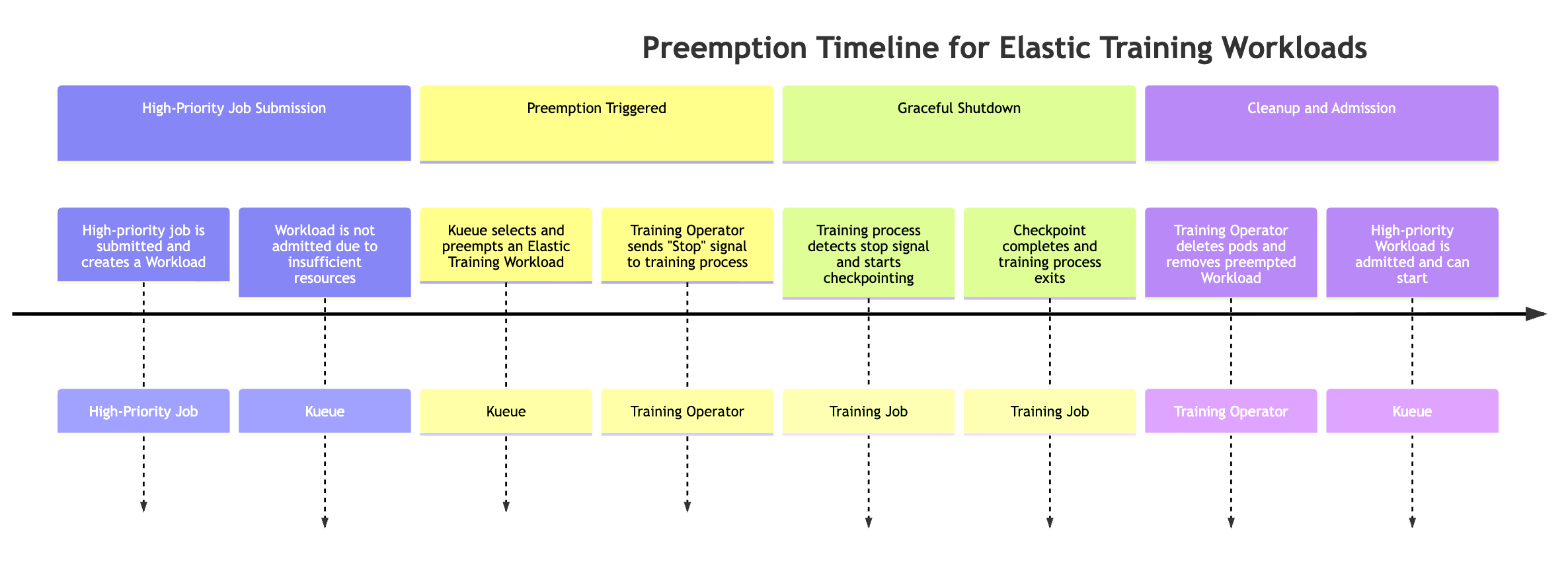
Quando un lavoro ad alta priorità richiede risorse, Kueue può anticipare i carichi di lavoro Elastic Training con priorità più bassa (potrebbe esserci più di un oggetto Workload associato al job Elastic Training). Il processo di prelazione segue questa sequenza:
-
Viene inviato un lavoro ad alta priorità Il lavoro crea un nuovo carico di lavoro Kueue, ma il carico di lavoro non può essere ammesso a causa di risorse del cluster insufficienti.
-
Kueue anticipa uno dei carichi di lavoro di Elastic Training I job Elastic possono avere più carichi di lavoro attivi (uno per configurazione di dimensioni mondiali). Kueue ne seleziona uno da anticipare in base alle politiche di priorità e coda.
-
L'operatore addetto alla formazione invia un segnale di evento elastico. Una volta attivata la prelazione, l'operatore addetto all'addestramento notifica che il processo di addestramento in corso si interrompa correttamente.
-
Il processo di formazione esegue il checkpoint. Il training job verifica periodicamente la presenza di segnali di eventi elastici. Quando viene rilevato, avvia un checkpoint coordinato per preservare i progressi prima dello spegnimento.
-
l'operatore addetto alla formazione pulisce i pod e i carichi di lavoro. L'operatore attende il completamento del checkpoint, quindi elimina i pod di addestramento che facevano parte del carico di lavoro previsto. Rimuove anche l'oggetto Workload corrispondente da Kueue.
-
Il carico di lavoro ad alta priorità è ammesso. Una volta liberate le risorse, Kueue ammette il lavoro ad alta priorità, consentendogli di avviare l'esecuzione.
La prelazione può causare la sospensione dell'intero processo di formazione, il che potrebbe non essere auspicabile per tutti i flussi di lavoro. Per evitare la sospensione completa del lavoro e consentire comunque la scalabilità elastica, i clienti possono configurare due diversi livelli di priorità all'interno dello stesso processo di formazione definendo due sezioni: replicaSpec
-
Una ReplicaSpec primaria (fissa) con priorità normale o alta
-
Contiene il numero minimo richiesto di repliche necessarie per mantenere attivo il processo di formazione.
-
Ne utilizza uno superiore PriorityClass, garantendo che queste repliche non vengano mai annullate.
-
Mantiene i progressi di base anche quando le risorse del cluster sono sotto pressione.
-
-
Una ReplicaSpec elastica (scalabile) con priorità inferiore
-
Contiene le repliche opzionali aggiuntive che forniscono elaborazione aggiuntiva durante la scalabilità elastica.
-
Utilizza una versione inferiore PriorityClass, che consente a Kueue di anticipare queste repliche quando i lavori con priorità più alta richiedono risorse.
-
Assicura che venga recuperata solo la parte elastica, mentre l'allenamento di base continua senza interruzioni.
-
Questa configurazione consente la prelazione parziale, in cui viene recuperata solo la capacità elastica, mantenendo la continuità della formazione pur supportando un'equa condivisione delle risorse in ambienti multi-tenant. Esempio:
apiVersion: sagemaker.amazonaws.com/v1 kind: HyperPodPyTorchJob metadata: name: elastic-training-job spec: elasticPolicy: minReplicas: 2 maxReplicas: 8 replicaIncrementStep: 2 ... replicaSpecs: - name: base replicas: 2 template: spec: priorityClassName: high-priority # set high-priority to avoid evictions ... - name: elastic replicas: 0 maxReplicas: 6 template: spec: priorityClassName: low-priority. # Set low-priority for elastic part ...
Gestione dello sfratto dei pod, dei crash dei pod e del degrado dell'hardware:
L'operatore addetto alla HyperPod formazione include meccanismi integrati per ripristinare il processo di formazione quando viene interrotto inaspettatamente. Le interruzioni possono verificarsi per vari motivi, ad esempio errori del codice di addestramento, rimozione dei pod, guasti dei nodi, deterioramento dell'hardware e altri problemi di runtime.
Quando ciò accade, l'operatore tenta automaticamente di ricreare i pod interessati e di riprendere l'addestramento dal checkpoint più recente. Se il recupero non è immediatamente possibile, ad esempio a causa dell'insufficiente capacità di riserva, l'operatore può continuare a progredire riducendo temporaneamente le dimensioni mondiali e riducendo il lavoro di formazione elastica.
Quando un processo di training elastico si blocca o perde delle repliche, il sistema si comporta come segue:
-
Fase di ripristino (utilizzando nodi di riserva) Il Training Controller attende che le risorse siano
faultyScaleDownTimeoutInSecondsdisponibili e tenta di recuperare le repliche fallite ridistribuendo i pod sulla capacità di riserva. -
Elastic scale-down Se il ripristino non è possibile entro la finestra di timeout, l'operatore addetto alla formazione ridimensiona il lavoro fino a renderlo più piccolo (se la politica elastica del lavoro lo consente). L'allenamento riprende quindi con un minor numero di repliche.
-
Scale-up elastico Quando le risorse aggiuntive diventano nuovamente disponibili, l'operatore ridimensiona automaticamente il lavoro di formazione fino alla dimensione mondiale preferita.
Questo meccanismo garantisce che la formazione possa continuare con tempi di inattività minimi, anche in caso di pressione delle risorse o di guasti parziali dell'infrastruttura, sfruttando al contempo la scalabilità elastica.
Usa l'allenamento elastico con altre funzionalità HyperPod
Attualmente Elastic Training non supporta funzionalità di formazione senza checkpoint, checkpoint HyperPod gestito su più livelli o istanze Spot.
Nota
Raccogliamo determinate metriche operative di routine aggregate e anonime per fornire la disponibilità essenziale del servizio. La creazione di queste metriche è completamente automatizzata e non prevede la revisione umana del carico di lavoro di formazione del modello sottostante. Queste metriche riguardano un lavoro e la scalabilità delle operazioni, la gestione delle risorse e le funzionalità essenziali del servizio.
