Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
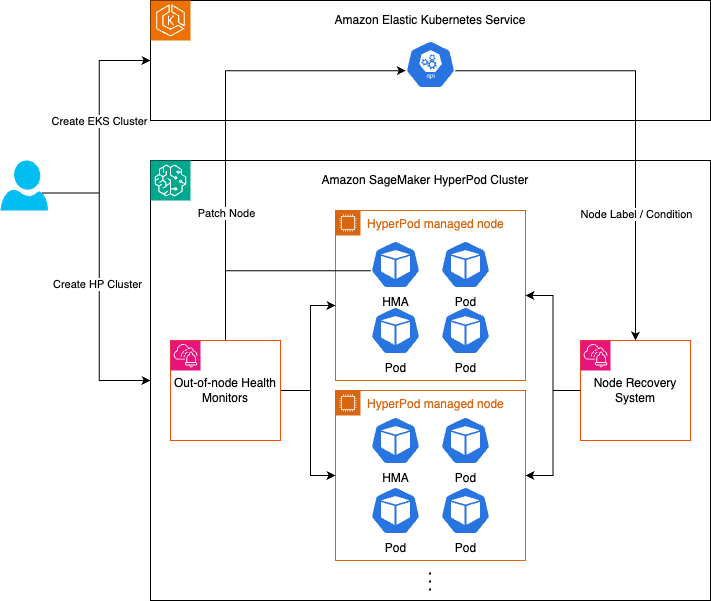
Sistema di monitoraggio della salute
SageMaker HyperPod il sistema di monitoraggio dello stato di salute include due componenti
-
Agenti di monitoraggio installati nei nodi, tra cui l'Health Monitoring Agent (HMA) che funge da monitoraggio dello stato dell'host e una serie di monitor dello stato fuori dal nodo.
-
Node Recovery System gestito da. SageMaker HyperPod Il sistema di monitoraggio dell'integrità monitorerà continuamente lo stato di salute del nodo tramite agenti di monitoraggio e quindi agirà automaticamente quando viene rilevato un guasto utilizzando il Node Recovery System.
Controlli sanitari effettuati dall'agente di SageMaker HyperPod monitoraggio sanitario
L'agente di SageMaker HyperPod monitoraggio sanitario verifica quanto segue.
GPU NVIDIA
-
Errori nell’output
nvidia-smi -
Vari errori nei log generati dalla piattaforma Amazon Elastic Compute Cloud (EC2)
-
Convalida del numero di GPU: se c'è una discrepanza tra il numero previsto di GPU in un particolare tipo di istanza (ad esempio: 8 GPU nel tipo di istanza ml.p5.48xlarge) e il conteggio restituito da, HMA riavvia il nodo
nvidia-smi
AWS Trainium
-
Errori nell’output dal monitoraggio AWS Neuron
-
Output generati dal rilevatore di problemi del nodo Neuron (per ulteriori informazioni sul rilevatore di problemi del nodo AWS Neuron, consulta Rilevamento e ripristino dei problemi AWS dei nodi Neuron all'interno dei
cluster Amazon EKS). -
Vari errori nei log generati dalla piattaforma Amazon EC2
-
Convalida del conteggio dei dispositivi Neuron: se c'è una discrepanza tra il numero effettivo di dispositivi neuronali in un particolare tipo di istanza e il conteggio restituito da, HMA riavvia il nodo
neuron-ls
I controlli di cui sopra sono passivi, i controlli dello stato in background vengono eseguiti HyperPod continuamente sui nodi. Oltre a questi controlli, esegue HyperPod anche controlli di integrità approfonditi (o attivi) durante la creazione e l'aggiornamento dei HyperPod cluster. Scopri di più sui controlli sanitari approfonditi.
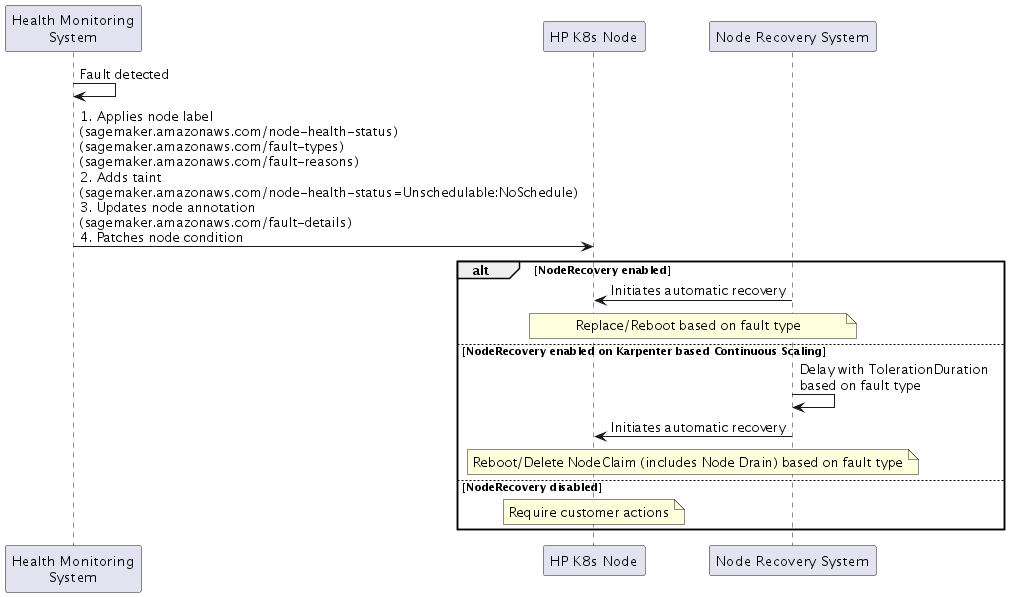
Rilevamento degli errori
Quando SageMaker HyperPod rileva un guasto, implementa una risposta in quattro parti:
-
Etichette dei nodi
-
Stato di salute:
sagemaker.amazonaws.com/node-health-status -
Tipo di errore:
sagemaker.amazonaws.com/fault-typesetichetta per la categorizzazione di alto livello -
Motivo dell'errore:
sagemaker.amazonaws.com/fault-reasonsetichetta con informazioni dettagliate sull'errore
-
-
Intossicazione del nodo
-
sagemaker.amazonaws.com/node-health-status=Unschedulable:NoSchedule
-
-
Annotazione del nodo
-
Dettagli del guasto:
sagemaker.amazonaws.com/fault-details -
Registra fino a 20 errori con timestamp che si sono verificati sul nodo
-
-
Condizioni del nodo (condizione del nodo Kubernetes
) -
Riflette lo stato di salute attuale nelle condizioni del nodo:
-
Tipo: uguale al tipo di errore
-
Stato:
True -
Motivo: uguale al motivo del guasto
-
LastTransitionTime: ora di insorgenza del guasto
-
-
Registri generati dall'agente di monitoraggio sanitario SageMaker HyperPod
L'agente di SageMaker HyperPod monitoraggio dello stato è una funzionalità di controllo dello stato pronta all'uso e funziona continuamente su tutti i cluster. HyperPod L'agente di monitoraggio dello stato pubblica gli eventi sanitari rilevati su istanze GPU o Trn nel gruppo di log Cluster. CloudWatch /aws/sagemaker/Clusters/
I registri di rilevamento dell'agente di HyperPod monitoraggio dello stato vengono creati come flussi di registro separati denominati per ciascun nodo. SagemakerHealthMonitoringAgent È possibile interrogare i registri di rilevamento utilizzando CloudWatch log insights come segue.
fields @timestamp, @message | filter @message like /HealthMonitoringAgentDetectionEvent/
Questo restituisce un output simile al seguente.
2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"} 2024-08-21T11:35:35.532-07:00 {"level":"info","ts":"2024-08-21T18:35:35Z","msg":"NPD caught event: %v","details: ":{"severity":"warn","timestamp":"2024-08-22T20:59:29Z","reason":"XidHardwareFailure","message":"Node condition NvidiaErrorReboot is now: True, reason: XidHardwareFailure, message: \"NVRM: Xid (PCI:0000:b9:00): 71, pid=<unknown>, name=<unknown>, NVLink: fatal error detected on link 6(0x10000, 0x0, 0x0, 0x0, 0x0, 0x0, 0x0)\""},"HealthMonitoringAgentDetectionEvent":"HealthEvent"}
