Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Creazione di un modello di attività del worker personalizzato
Per creare un processo di etichettatura personalizzato, è necessario aggiornare il modello di attività del worker, mappare i dati di input dal file manifesto alle variabili utilizzate nel modello e mappare i dati di output ad Amazon S3. Per ulteriori informazioni sulle funzionalità avanzate che utilizzano l’automazione Liquid, consulta Aggiunta di automazione con Liquid.
Le sezioni seguenti descrivono ciascuna delle fasi richieste.
Modello di attività del worker
Un modello di attività del worker è un file utilizzato da Ground Truth per personalizzare l’interfaccia utente (UI) del worker. È possibile creare un modello di attività di lavoro utilizzando HTML, CSS JavaScript, il linguaggio di modelli Liquid
Utilizza gli argomenti seguenti per informazioni su come creare un modello di attività del worker. È possibile visualizzare un archivio di esempi di modelli di attività dei lavoratori di Ground Truth su GitHub
Utilizzo del modello di attività di base worker nella console SageMaker AI
Puoi utilizzare un editor di modelli nella console Ground Truth per iniziare a creare un modello. Questo editor include una serie di modelli di base preprogettati. Supporta la compilazione automatica per il codice HTML e Crowd HTML Element.
Per accedere all'editor di modelli personalizzati di Ground Truth:
-
Segui le istruzioni in Creare un processo di etichettatura (console).
-
Quindi seleziona Personalizzato per il valore di Tipo di attività del processo di etichettatura.
-
Scegli Avanti per accedere all’editor di modelli e ai modelli di base nella sezione Configurazione dell’attività di etichettatura personalizzata.
-
(Facoltativo) Seleziona un modello di base dal menu a discesa in Modelli. Se preferisci creare un modello partendo da zero, scegli Personalizza dal menu a discesa per una struttura ridotta al minimo del modello.
Utilizza la sezione seguente per capire come visualizzare in locale un modello sviluppato nella console.
Visualizzazione locale dei modelli di attività del worker
È necessario utilizzare la console per testare il modo in cui il modello elabora i dati in entrata. Per testare l’aspetto dell’HTML e degli elementi personalizzati del modello, è possibile utilizzare il browser.
Nota
Le variabili non vengono analizzate. Potrebbe essere necessario sostituirle con contenuti di esempio durante la visualizzazione locale dei contenuti.
Il seguente frammento di codice di esempio carica il codice necessario per il rendering degli elementi HTML personalizzati. Utilizza questo codice se desideri sviluppare l'aspetto del modello nell'editor preferito anziché nella console.
Esempio
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script>
Creazione di un esempio di attività HTML semplice
Ora che hai il modello di attività di base worker, puoi utilizzare questo argomento per creare un modello di HTML-based attività semplice.
Di seguito è riportato un esempio di un file manifesto di input.
{ "source": "This train is really late.", "labels": [ "angry" , "sad", "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }
Nel modello di attività HTML è necessario mappare le variabili dal file manifesto di input al modello. È possibile mappare la variabile del manifesto di input di esempio utilizzando la seguente sintassi task.input.source, task.input.labels e task.input.header.
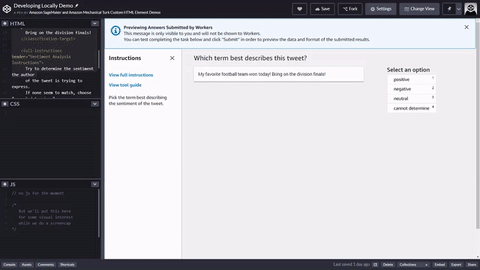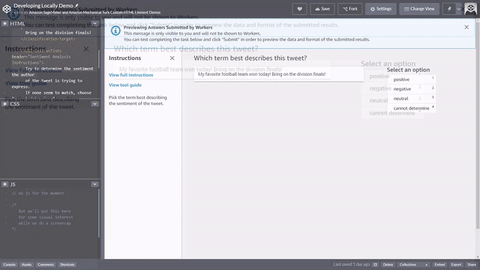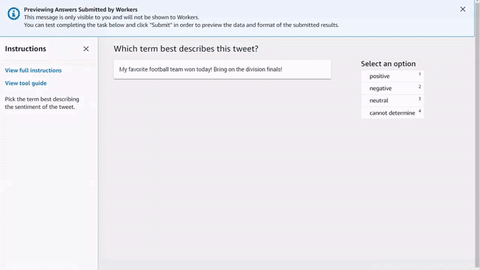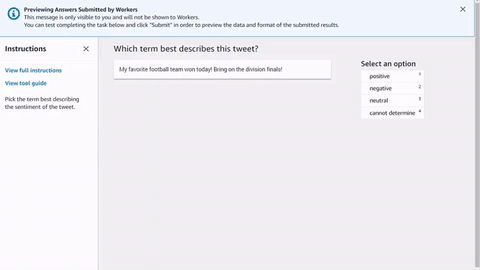
Quello che segue è un semplice esempio di modello di attività del worker HTML per l’analisi dei tweet. Tutte le attività iniziano e terminano con gli elementi <crowd-form> </crowd-form>. Analogamente agli elementi HTML <form> standard, tutto il codice del modulo deve essere racchiuso tra di essi. Ground Truth genera le attività dei worker direttamente dal contesto specificato nel modello, a meno che non si implementi una funzione Lambda di pre-annotazione. L’oggetto taskInput restituito da Ground Truth o Pre-annotation Lambda è l’oggetto task.input nei tuoi modelli.
Per una semplice attività di analisi dei tweet, utilizza l'elemento <crowd-classifier> che richiede i seguenti attributi:
name - Il nome della variabile di output. Le annotazioni dei worker vengono salvate con questo nome di variabile nel manifesto di output.
categories - Un array in formato JSON delle possibili risposte.
header - Un titolo per lo strumento di annotazione.
L’elemento <crowd-classifier> richiede almeno i tre elementi secondari seguenti.
<classification-target> - Il testo che verrà classificato dal worker in base alle opzioni specificate nell’attributo
categoriesprecedente.<full-instructions> - Le istruzioni disponibili dal link “Visualizza istruzioni complete” nello strumento. Questo può essere lasciato vuoto, ma ti consigliamo di fornire buone istruzioni per ottenere risultati migliori.
<short-instructions> - Una descrizione più breve dell’attività che verrà visualizzata nella barra laterale dello strumento. Questo può essere lasciato vuoto, ma ti consigliamo di fornire buone istruzioni per ottenere risultati migliori.
Di seguito è riportata una semplice versione di questo strumento. La variabile {{ task.input.source }} è ciò che specifica i dati di origine del file di manifesto input. {{ task.input.labels | to_json }} è un esempio di filtro di variabile per trasformare l’array in una rappresentazione JSON. L’attributo categories deve essere di tipo JSON.
Esempio di usare crowd-classifier con l'esempio di input manifest json
<script src="https://assets.crowd.aws/crowd-html-elements.js"></script> <crowd-form> <crowd-classifier name="tweetFeeling"categories="='{{ task.input.labels | to_json }}'" header="{{ task.input.header }}'" > <classification-target>{{ task.input.source }}</classification-target> <full-instructions header="Sentiment Analysis Instructions"> Try to determine the sentiment the author of the tweet is trying to express. If none seem to match, choose "cannot determine." </full-instructions> <short-instructions> Pick the term that best describes the sentiment of the tweet. </short-instructions> </crowd-classifier> </crowd-form>
Puoi copiare e incollare il codice nell'editor del flusso di lavoro di creazione di lavori di etichettatura di Ground Truth per visualizzare un'anteprima dello strumento o provare una demo di questo codice su CodePen
Dati di input, asset esterni e il tuo modello di attività
Le sezioni seguenti descrivono l’uso di asset esterni e i requisiti del formato dei dati di input, oltre a spiegare quando prendere in considerazione l’utilizzo delle funzioni Lambda di pre-annotazione.
Requisiti per il formato dei dati di input
Quando crei un file manifesto di input da utilizzare nel tuo processo di etichettatura Ground Truth personalizzato, devi archiviare i dati in Amazon S3. I file manifest di input devono inoltre essere salvati nello stesso Regione AWS in cui deve essere eseguito il processo di etichettatura Ground Truth personalizzato. Il file manifesto può essere archiviato in qualsiasi bucket S3 Amazon accessibile al ruolo di servizio IAM utilizzato per eseguire il processo di etichettatura personalizzato in Ground Truth.
I file manifesto di input devono utilizzare il formato JSON o JSON delimitato da newline. Ogni riga è delimitata da un’interruzione di riga standard, \n oppure \r\n. Ogni riga deve essere anche un oggetto JSON valido.
Inoltre, ogni oggetto JSON nel file manifesto deve contenere una delle seguenti chiavi: source-ref oppure source. I valori delle chiavi sono interpretati come segue:
-
source-ref: l'origine dell'oggetto è l'oggetto Amazon S3 specificato nel valore. Utilizza questo valore quando l'oggetto è un oggetto binario, ad esempio un'immagine. -
source: l'origine dell'oggetto è il valore. Utilizza questo valore quando l'oggetto è un valore di testo.
Per ulteriori informazioni sulla formattazione dei file manifesto di input, consulta File di manifesto di input.
Pre-annotation Funzione Lambda
Facoltativamente, è possibile specificare una funzione Lambda di pre-annotazione per gestire il modo in cui i dati del file manifesto di input vengono gestiti prima dell’etichettatura. Se è stata specificata la coppia chiave-valore isHumanAnnotationRequired, è necessario utilizzare una funzione Lambda di pre-annotazione. Quando Ground Truth invia alla funzione Lambda di pre-annotazione una richiesta in formato JSON, utilizza gli schemi seguenti.
Esempio oggetto di dati identificato con la coppia chiave-valore source-ref
{ "version": "2018-10-16", "labelingJobArn":arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source-ref":s3://input-data-bucket/data-object-file-name} }
Esempio oggetto di dati identificato con la coppia chiave-valore di origine
{ "version": "2018-10-16", "labelingJobArn" :arn:aws:lambda:us-west-2:555555555555:function:my-function"dataObject" : { "source":Sue purchased 10 shares of the stock on April 10th, 2020} }
Di seguito è riportata la risposta prevista dalla funzione Lambda in caso di utilizzo di isHumanAnnotationRequired.
{ "taskInput":{ "source": "This train is really late.", "labels": [ "angry" , "sad" , "happy" , "inconclusive" ], "header": "What emotion is the speaker feeling?" }, "isHumanAnnotationRequired":False}
Utilizzo di External Assets
I modelli personalizzati di Amazon SageMaker Ground Truth consentono di incorporare script e fogli di stile esterni. Ad esempio, il seguente blocco di codice mostra come aggiungere al proprio modello un foglio di stile che si trova in https://www.example.com/my-enhancement-styles.css.
Esempio
<script src="https://www.example.com/my-enhancment-script.js"></script> <link rel="stylesheet" type="text/css" href="https://www.example.com/my-enhancement-styles.css">
Se si verificano errori, verifica che il server di origine stia inviando il tipo MIME corretto e le intestazioni di codifica con gli asset.
Ad esempio, i tipi MIME e di codifica per gli script remoti sono: application/javascript;CHARSET=UTF-8.
Il tipo MIME e di codifica per i fogli di stile remoti sono: text/css;CHARSET=UTF-8.
Dati di output e il tuo modello di attività
Le sezioni seguenti descrivono i dati di output di un processo di etichettatura personalizzato, oltre a spiegare quando prendere in considerazione l’utilizzo di una funzione Lambda post-annotazione.
Dati di output
Al termine del processo di etichettatura personalizzato, i dati vengono salvati nel bucket Amazon S3 specificato al momento della creazione del job. I dati vengono salvati in un file output.manifest.
Nota
labelAttributeNameè una variabile segnaposto. Nell’output è il nome del processo di etichettatura o il nome dell’attributo dell’etichetta specificato al momento della creazione del processo di etichettatura.
-
sourceoppuresource-ref- È stato chiesto di etichettare la stringa o un worker URI S3. -
labelAttributeName- Un dizionario con il contenuto consolidato delle etichette della funzione Lambda post-annotazione. Se non viene specificata una funzione Lambda post-annotazione, questo dizionario è vuoto. -
labelAttributeName-metadata- Metadati del processo di etichettatura personalizzato aggiunto da Ground Truth. -
worker-response-ref- L’URI S3 del bucket in cui vengono salvati i dati. Se viene specificata una funzione Lambda post-annotazione, questa coppia chiave-valore non viene visualizzata.
In questo esempio l'oggetto JSON è formattato per la leggibilità, nel file di output effettivo dell'oggetto JSON si trova su un'unica riga.
{ "source" : "This train is really late.", "labelAttributeName" : {}, "labelAttributeName-metadata": { # These key values pairs are added by Ground Truth "job_name": "test-labeling-job", "type": "groundTruth/custom", "human-annotated": "yes", "creation_date": "2021-03-08T23:06:49.111000", "worker-response-ref": "s3://amzn-s3-demo-bucket/test-labeling-job/annotations/worker-response/iteration-1/0/2021-03-08_23:06:49.json" } }
Utilizzo di una funzione Lambda post-annotazione per consolidare i risultati dei worker
Per impostazione predefinita, Ground Truth salva le risposte dei worker non elaborate in Amazon S3. Per un controllo più granulare sulla modalità di gestione delle risposte, è possibile specificare una funzione Lambda post-annotazione. Ad esempio, una funzione Lambda post-annotazione potrebbe essere utilizzata per consolidare l’annotazione se più worker hanno etichettato lo stesso oggetto di dati. Per ulteriori informazioni sulla creazione di funzioni Lambda post-annotazione, consulta Post-annotation Lambda.
Per utilizzare una funzione Lambda post-annotazione, è necessario specificarla come parte di AnnotationConsolidationConfig in una richiesta CreateLabelingJob.
Per ulteriori informazioni sul funzionamento del consolidamento delle annotazioni, consulta Consolidamento delle annotazioni.
