Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Come funziona SageMaker lo smart sifting
L'obiettivo dello SageMaker smart sifting è quello di esaminare i dati di allenamento durante il processo di addestramento e fornire al modello solo campioni più informativi. Durante l'addestramento tipico con PyTorch, i dati vengono inviati iterativamente in batch al ciclo di addestramento e ai dispositivi di accelerazione (come GPU o chip Trainium) dal. PyTorchDataLoader
Il diagramma seguente mostra una panoramica di come è stato progettato l'algoritmo SageMaker smart sifting.
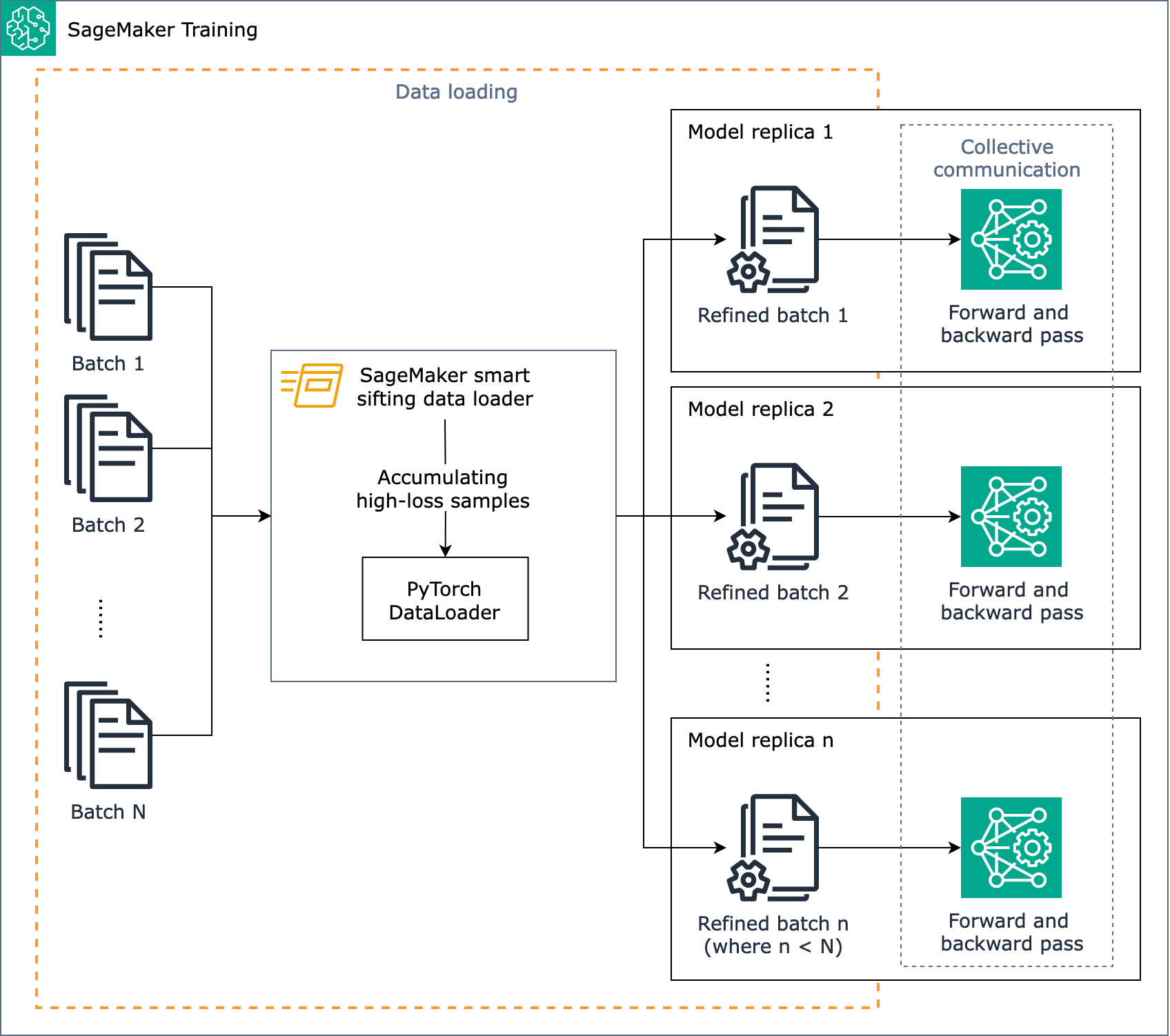
In breve, lo SageMaker smart sifting funziona durante l'allenamento man mano che i dati vengono caricati. L'algoritmo SageMaker smart sifting esegue il calcolo delle perdite su più batch ed elimina i dati non migliorativi prima del passaggio avanti e indietro di ogni iterazione. Il batch di dati perfezionato viene quindi utilizzato per il passaggio avanti e indietro.
Nota
Il setacciamento intelligente dei dati sull' SageMaker intelligenza artificiale utilizza passaggi avanzati aggiuntivi per analizzare e filtrare i dati di allenamento. A loro volta, si verificano meno passaggi indietro, poiché i dati con un impatto minore vengono esclusi dal job di addestramento. Per questo motivo, i modelli con passaggi indietro lunghi o costosi ottengono i maggiori vantaggi in termini di efficienza quando utilizzano la funzionalità di smart sifting. Al contrario, se il passaggio avanti del modello richiede più tempo rispetto al passaggio indietro, l’overhead potrebbe aumentare il tempo totale di addestramento. Per misurare il tempo impiegato per ogni passaggio, è possibile eseguire un job di addestramento pilota e raccogliere log del tempo impiegato nei processi. Considerate anche l'utilizzo di SageMaker Profiler, che fornisce strumenti di profilazione e un'applicazione per l'interfaccia utente. Per ulteriori informazioni, consulta Amazon SageMaker Profiler.
SageMaker smart sifting è ideale per i lavori di PyTorch-based formazione con il classico parallelismo distribuito dei dati, che riproduce i modelli su ogni operatore della GPU ed esegue le stesse prestazioni. AllReduce Funziona con PyTorch DDP e la libreria parallela di dati distribuiti SageMaker AI.
