Die vorliegende Übersetzung wurde maschinell erstellt. Im Falle eines Konflikts oder eines Widerspruchs zwischen dieser übersetzten Fassung und der englischen Fassung (einschließlich infolge von Verzögerungen bei der Übersetzung) ist die englische Fassung maßgeblich.
Retrieval Augmented Generation
Grundlagenmodelle werden normalerweise offline trainiert, wodurch das Modell unabhängig von allen Daten ist, die nach dem Training des Modells erstellt wurden. Darüber hinaus werden Grundlagenmodelle mit sehr allgemeinen Domaindatensätzen trainiert, wodurch sie für domainspezifische Aufgaben weniger effektiv sind. Mit Retrieval Augmented Generation (RAG) können Sie Daten von außerhalb eines Grundlagenmodells abrufen und Ihre Eingabeaufforderungen erweitern, indem Sie die relevanten abgerufenen Daten im Kontext hinzufügen. Weitere Informationen zu RAG-Modellarchitekturen finden Sie unter Retrieval-Augmented Generierung für Knowledge-Intensive
Bei RAG können die externen Daten, die zur Erweiterung Ihrer Eingabeaufforderungen verwendet werden, aus mehreren Datenquellen stammen, z. B. aus Dokument-Repositorys, Datenbanken oder APIs. Der erste Schritt besteht darin, Ihre Dokumente und alle Benutzerabfragen in ein kompatibles Format zu konvertieren, um eine Relevanzsuche durchzuführen. Um die Formate kompatibel zu machen, werden eine Dokumentensammlung oder Wissensbibliothek und von Benutzern eingereichte Abfragen mithilfe von eingebetteten Sprachmodellen in numerische Darstellungen konvertiert. Beim Einbetten wird Text in einem Vektorraum numerisch dargestellt. RAG-Modellarchitekturen vergleichen die Einbettungen von Benutzerabfragen innerhalb des Vektors der Wissensbibliothek. Die ursprüngliche Eingabeaufforderung wird dann mit relevantem Kontext aus ähnlichen Dokumenten in der Wissensbibliothek angehängt. Diese erweiterte Eingabeaufforderung wird dann an das Grundlagenmodell gesendet. Sie können Wissensbibliotheken und ihre relevanten Einbettungen asynchron aktualisieren.
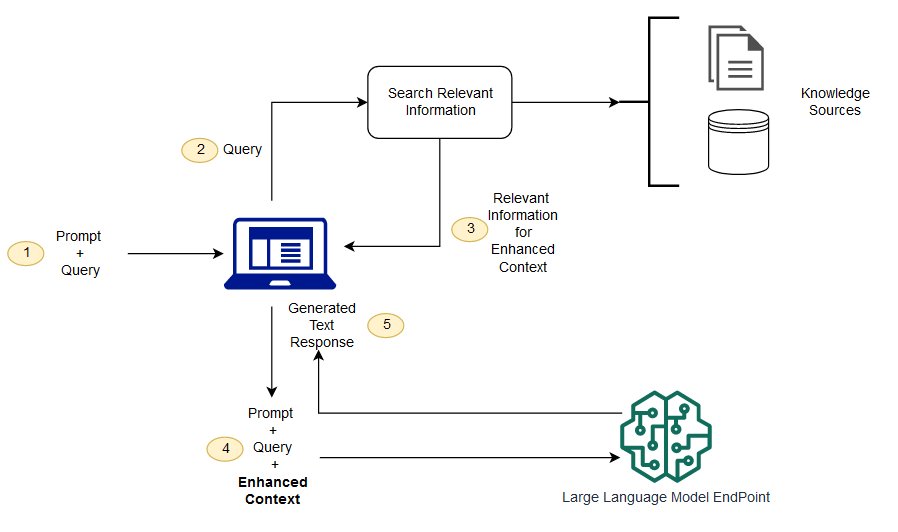
Das abgerufene Dokument sollte groß genug sein, um nützlichen Kontext zur Erweiterung des Prompts zu enthalten, aber klein genug, um in die maximale Sequenzlänge des Prompts zu passen. Sie können aufgabenspezifische JumpStart Modelle verwenden, z. B. das Modell General Text Embeddings (GTE) von, um die Einbettungen für Ihre Hugging Face Eingabeaufforderungen und Wissensbibliotheksdokumente bereitzustellen. Nachdem Sie den Prompt und die Dokumenteinbettungen verglichen haben, um die relevantesten Dokumente zu finden, erstellen Sie einen neuen Prompt mit dem ergänzenden Kontext. Übergeben Sie dann den erweiterten Prompt an ein Textgenerierungsmodell Ihrer Wahl.
Beispiel-Notebooks
Weitere Informationen zu Lösungen mit RAG-Basismodellen finden Sie in den folgenden Beispiel-Notebooks:
Sie können das Amazon SageMaker AI-Beispiel-Repository
