Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Gestione degli accessi IAM
Le seguenti sezioni descrivono i requisiti AWS Identity and Access Management (IAM) per Amazon SageMaker Pipelines. Per un esempio di implementazione delle autorizzazioni, consulta Prerequisiti.
Autorizzazioni relative ai ruoli della pipeline
La tua pipeline richiede un ruolo di esecuzione della pipeline IAM che viene passato a Pipelines quando crei una pipeline. Il ruolo per l'istanza di SageMaker intelligenza artificiale che stai utilizzando per creare la pipeline deve avere una policy con l'iam:PassRoleautorizzazione che specifichi il ruolo di esecuzione della pipeline. Questo perché l'istanza necessita dell'autorizzazione per passare il ruolo di esecuzione della pipeline al servizio Pipelines da utilizzare nella creazione e nell'esecuzione di pipeline. Per ulteriori informazioni sui ruoli IAM, consulta Ruoli IAM.
Il ruolo di esecuzione della pipeline richiede le seguenti autorizzazioni:
-
Puoi utilizzare un ruolo unico o personalizzato per qualsiasi fase del processo di SageMaker intelligenza artificiale nella tua pipeline (anziché il ruolo di esecuzione della pipeline, che viene utilizzato per impostazione predefinita). Assicurati che al tuo ruolo di esecuzione della pipeline sia stata aggiunta una policy con l'
iam:PassRoleautorizzazione che specifichi ciascuno di questi ruoli. -
Autorizzazioni
CreateeDescribeper ogni tipo di processo nella pipeline. -
Autorizzazioni Amazon S3 per utilizzare la funzione
JsonGet. È possibile controllare l’accesso alle risorse Amazon S3 utilizzando policy basate sulle identità e sulle risorse. Al bucket Amazon S3 viene applicata una policy basata sulle risorse, che consente a Pipelines di accedere al bucket. Una policy basata sull'identità offre alla tua pipeline la possibilità di effettuare chiamate Amazon S3 dal tuo account. Per ulteriori informazioni sulle politiche basate sulle risorse e sulle politiche basate sull'identità, consulta politiche e politiche basate sulle risorse. Identity-based{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
Autorizzazioni relative alle fasi della pipeline
Le pipeline includono SageMaker passaggi che eseguono lavori di intelligenza artificiale. Affinché le fasi della pipeline eseguano questi processi, è richiesto un ruolo IAM nell'account che fornisca l'accesso alla risorsa necessaria. Questo ruolo viene trasferito al responsabile del servizio di SageMaker intelligenza artificiale dalla tua pipeline. Per ulteriori informazioni sui ruoli IAM, consulta Ruoli IAM.
Per impostazione predefinita, ogni fase assume il ruolo di esecuzione della pipeline. Facoltativamente, puoi assegnare un ruolo diverso a qualsiasi fase della pipeline. Ciò garantisce che il codice di ogni fase non abbia la possibilità di influire sulle risorse utilizzate in altre fasi, a meno che non esista una relazione diretta tra le due fasi specificate nella definizione della pipeline. Questi ruoli vengono trasmessi quando si definisce lo strumento di elaborazione o valutazione per la propria fase. Per esempi su come includere questi ruoli in queste definizioni, consulta la documentazione di SageMaker AI Python SDK
Configurazione CORS con bucket Amazon S3
Per garantire che le immagini vengano importate nelle pipeline da un bucket Amazon S3 in modo prevedibile, è necessario aggiungere una configurazione CORS ai bucket Amazon S3 da cui vengono importate le immagini. Questa sezione fornisce istruzioni su come impostare la configurazione CORS richiesta per il bucket Amazon S3. La CORSConfiguration XML richiesta per Pipelines è diversa da quella in Requisito CORS per i dati delle immagini di input. In alternativa, consulta queste informazioni per saperne di più sul requisito CORS per i bucket Amazon S3.
Utilizza il codice di configurazione CORS seguente per i bucket Amazon S3 che ospitano le tue immagini. Per istruzioni sulla configurazione CORS, consulta Configuring cross-origin resource sharing (CORS) in Amazon Simple Storage Service User Guide. Se utilizzi la console Amazon S3 per aggiungere la policy al tuo bucket, devi utilizzare il formato JSON.
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
La seguente GIF illustra le istruzioni contenute nella documentazione di Amazon S3 per aggiungere una policy di intestazione CORS utilizzando la console Amazon S3.
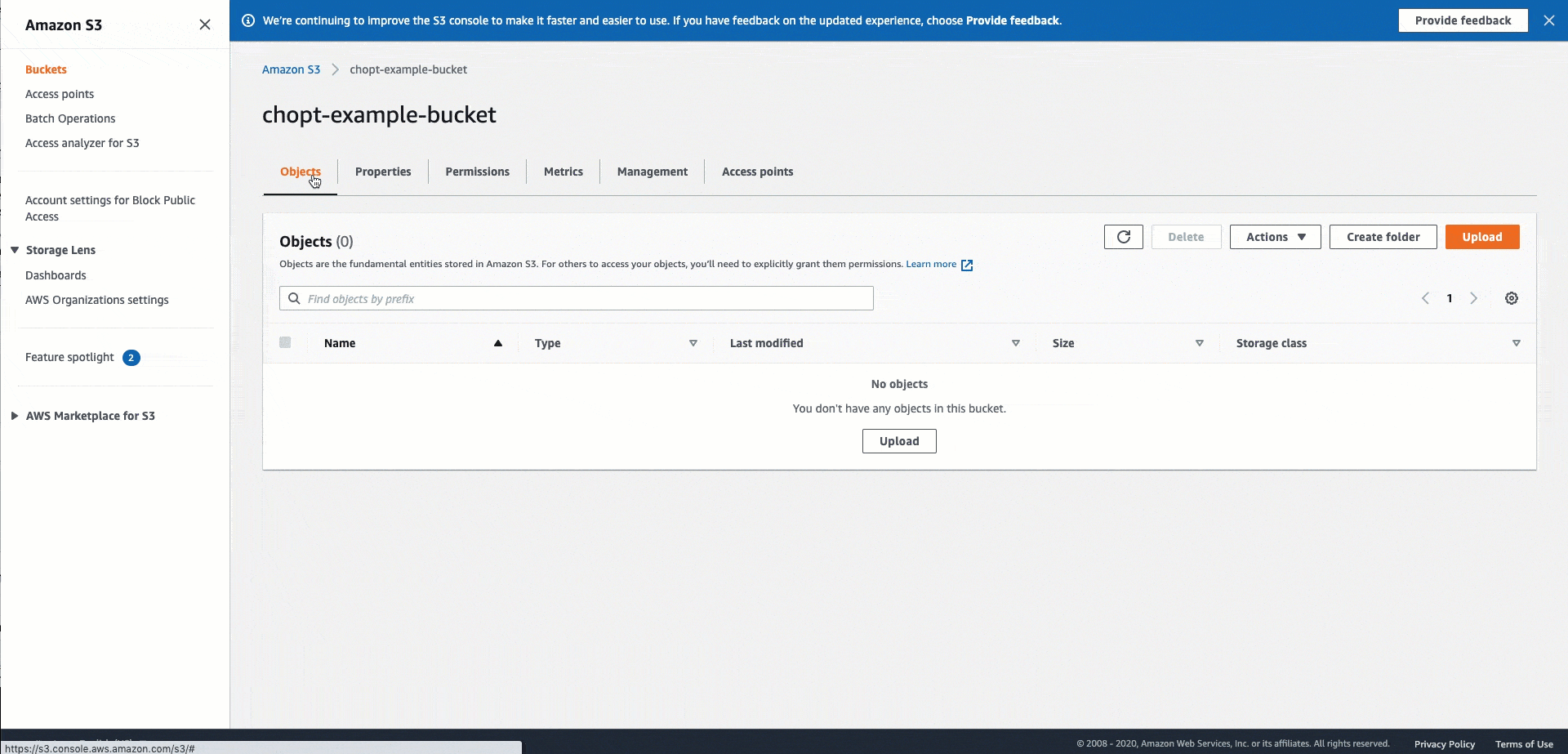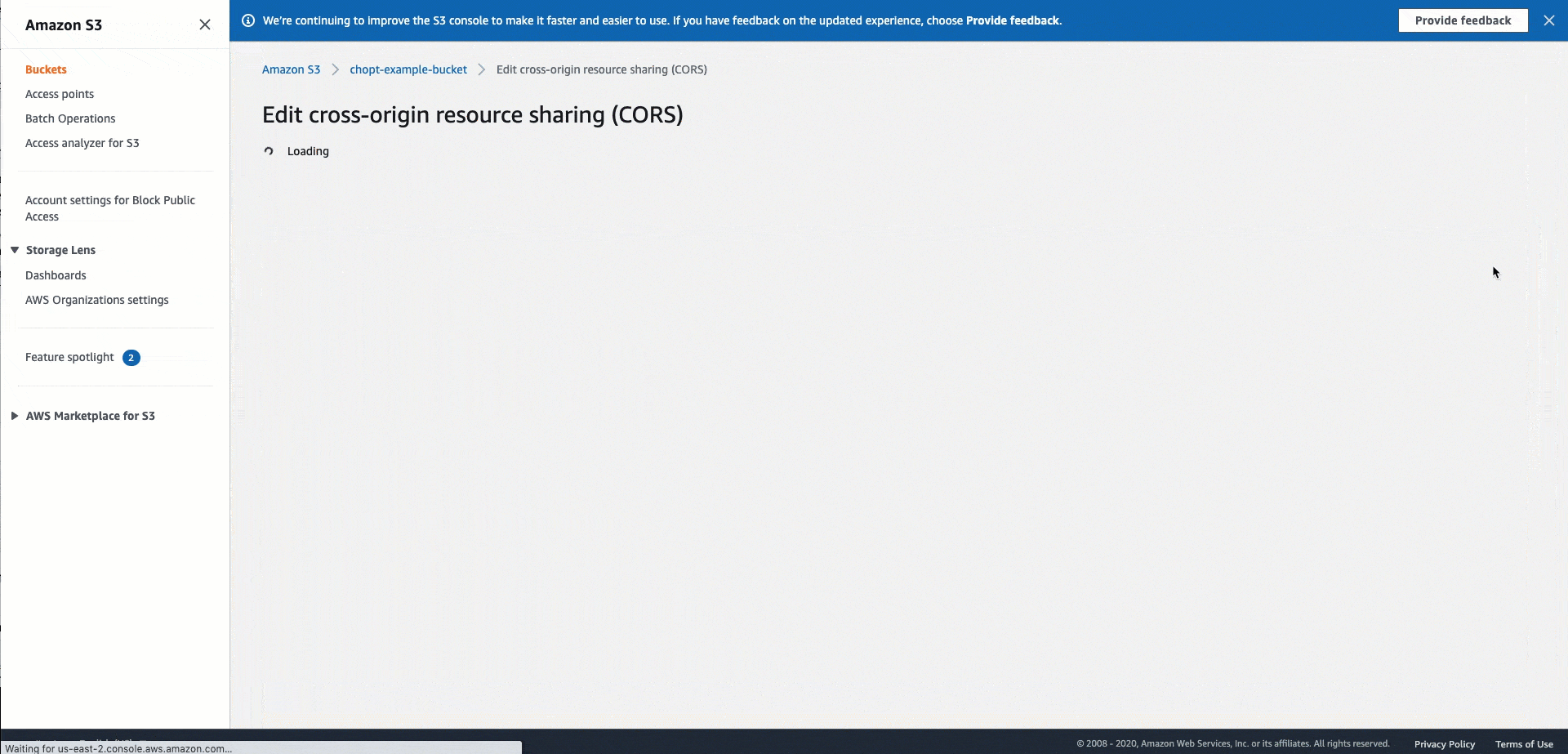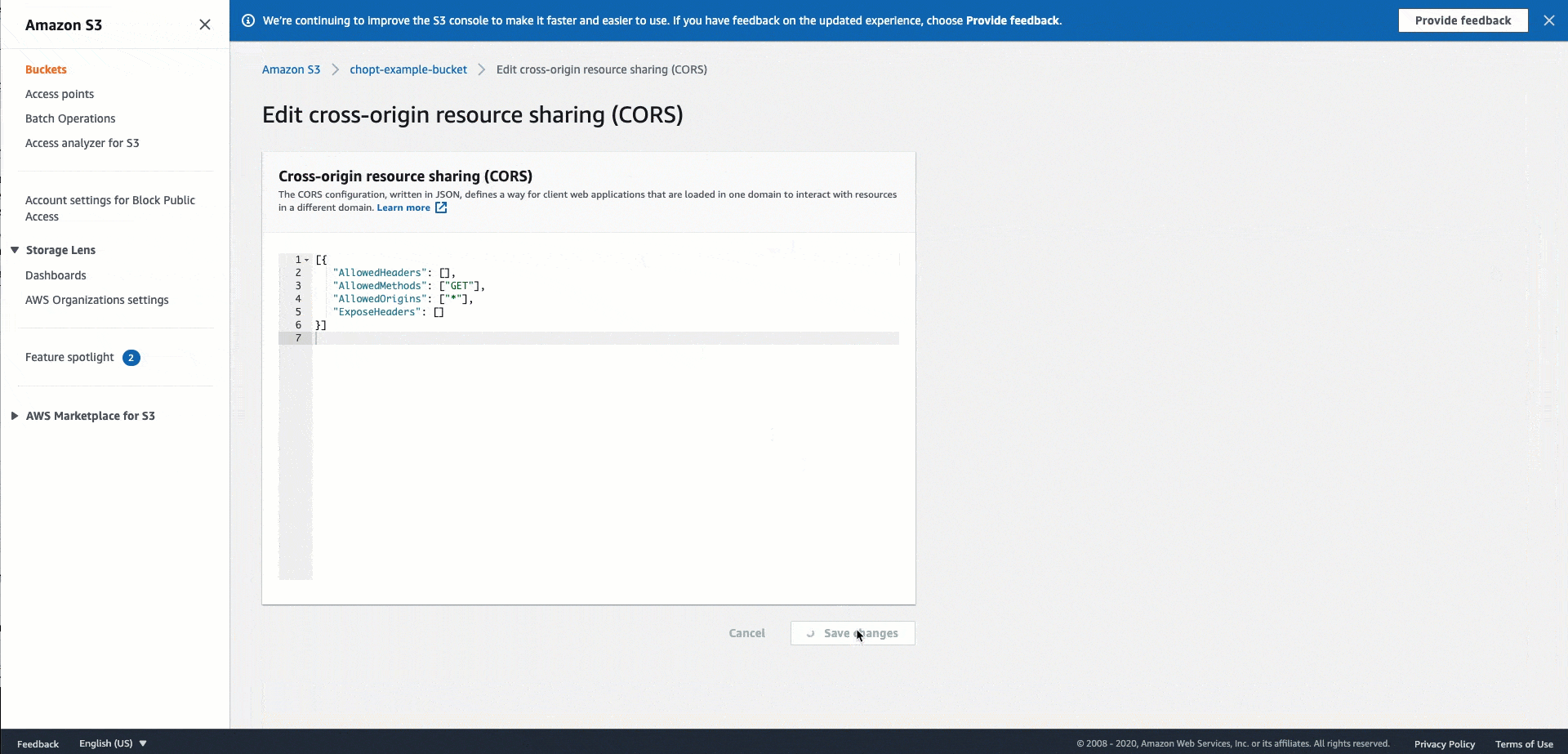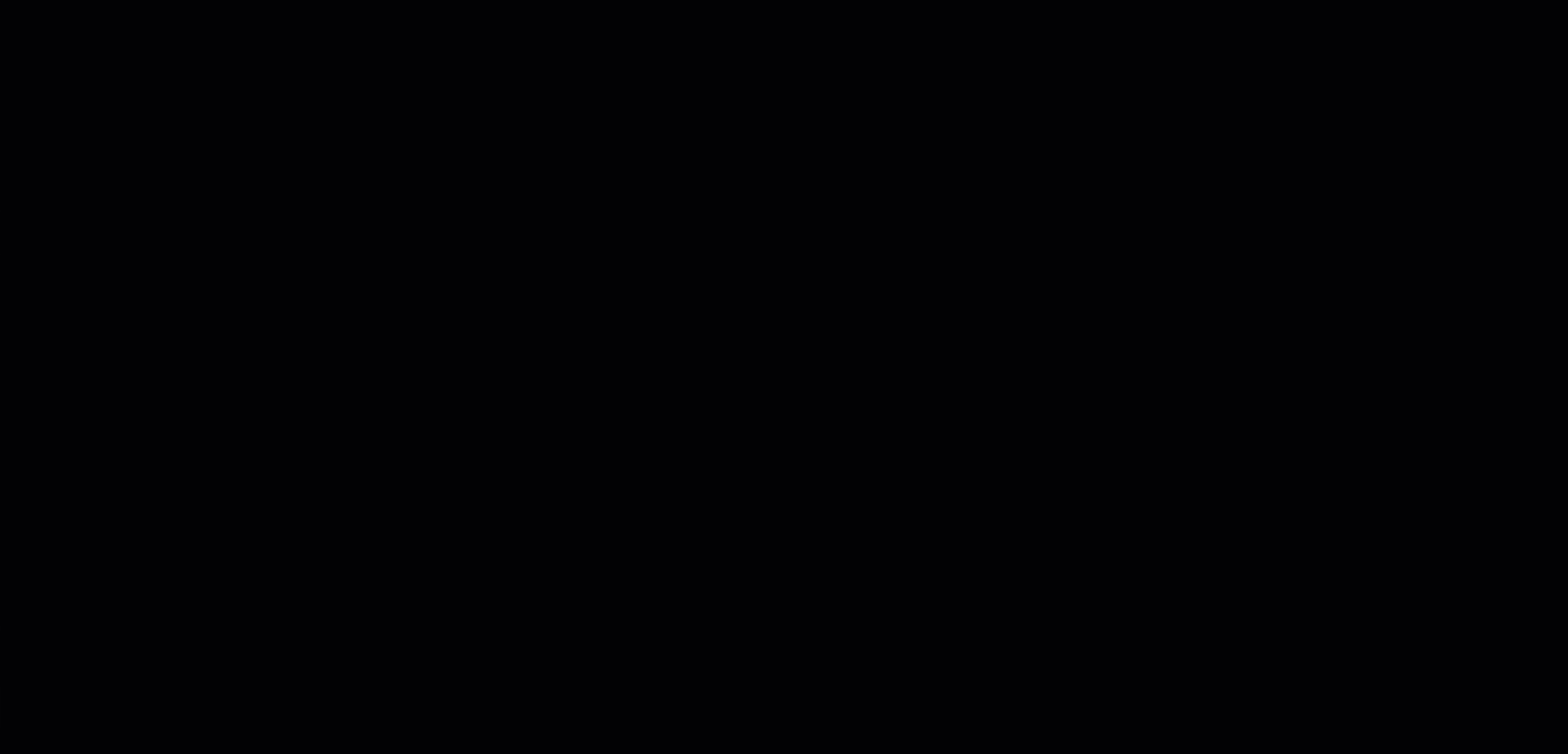
Personalizzazione della gestione degli accessi per i processi Pipelines
Puoi personalizzare ulteriormente le tue policy IAM in modo che membri selezionati della tua organizzazione possano eseguire alcune o tutte le fasi della pipeline. Ad esempio, puoi concedere a determinati utenti l'autorizzazione a creare processi di addestramento, a un altro gruppo di utenti l'autorizzazione a creare processi di elaborazione e a tutti gli utenti l'autorizzazione a eseguire le fasi rimanenti. Per utilizzare questa funzionalità, seleziona una stringa personalizzata con il prefisso del nome del processo. L'amministratore aggiunge il prefisso agli ARN consentiti, mentre il data scientist lo include nelle istanze della pipeline. Poiché la policy IAM per gli utenti autorizzati contiene un ARN di processo con il prefisso specificato, i processi successivi della fase della pipeline dispongono delle autorizzazioni necessarie per procedere. Il prefisso del processo è disattivato per impostazione predefinita: devi attivare questa opzione nella tua classe Pipeline per utilizzarla.
Per i processi con il prefisso disattivato, il nome del processo è formattato come mostrato e rappresentato da una concatenazione di campi, come descritto nella tabella seguente:
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| Campo | Definizione |
|---|---|
|
pipelines |
Una stringa statica sempre anteposta. Questa stringa identifica il servizio di orchestrazione della pipeline come origine del processo. |
|
executionId |
Un buffer randomizzato per l'istanza in esecuzione della pipeline. |
|
passo NamePrefix |
Il nome della fase specificato dall'utente (fornito nell'argomento |
|
entityToken |
Un token randomizzato per garantire l'idempotenza dell'entità della fase. |
|
failureCount |
Il numero attuale di tentativi effettuati per completare il lavoro. |
In questo caso, al nome del processo non viene aggiunto alcun prefisso personalizzato; la policy IAM corrispondente deve corrispondere a questa stringa.
Per gli utenti che attivano il prefisso del processo, il nome del processo sottostante assume la forma seguente, con il prefisso personalizzato specificato come MyBaseJobName:
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
Il prefisso personalizzato sostituisce la pipelines stringa statica per aiutarti a restringere la selezione di utenti che possono eseguire il lavoro SageMaker AI come parte di una pipeline.
Restrizioni sulla lunghezza del prefisso
I nomi dei processi hanno vincoli di lunghezza interni specifici per le singole fasi della pipeline. I vincoli limitano anche la lunghezza consentita del prefisso. I requisiti di lunghezza del prefisso sono i seguenti:
| Fase della pipeline | Lunghezza del prefisso |
|---|---|
|
|
38 |
|
6 |
Applicazione di prefissi dei processi a una policy IAM
L’amministratore crea policy IAM che consentono agli utenti con prefissi specifici di creare lavori. La seguente policy di esempio consente ai data scientist di creare processi di addestramento se utilizzano il prefisso MyBaseJobName.
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
Applicazione di prefissi dei processi alle istanze della pipeline
Specifica il prefisso con l'argomento *base_job_name della classe dell’istanza di processo.
Nota
Trasmetti il prefisso del processo con l'argomento *base_job_name all'istanza del processo prima di creare una fase della pipeline. Questa istanza di processo contiene le informazioni necessarie affinché il processo venga eseguito come fase di una pipeline. Questo argomento varia a seconda dell'istanza di processo utilizzata. L'elenco seguente mostra quale argomento utilizzare per ogni tipo di fase della pipeline:
-
base_job_nameper le classiEstimator(TrainingStep),Processor(ProcessingStep) eAutoML(AutoMLStep) -
tuning_base_job_nameper la classeTuner(TuningStep) -
transform_base_job_nameper la classeTransformer(TransformStep) -
base_job_namesuCheckJobConfigper le classiQualityCheckStep(Quality Check) eClarifyCheckstep(Clarify Check) -
Per la classe
Model, l'argomento utilizzato dipende dal fatto che si eseguacreateoregisterdal modello prima di trasmettere il risultato aModelStep-
Se si chiama
create, il prefisso personalizzato deriva dall'argomentonamequando si costruisce il modello (ad esempio,Model(name=)) -
Se si chiama
register, il prefisso personalizzato deriva dall'argomentomodel_package_namedella chiamata aregister(ad esempio,my_model.register(model_package_name=)
-
L'esempio seguente mostra come specificare un prefisso per una nuova istanza del processo di addestramento.
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
Per impostazione predefinita, l'aggiunta del prefisso al processo è disattivata. Per attivare questa funzionalità, utilizza l'opzione use_custom_job_prefix di PipelineDefinitionConfig come mostrato nel seguente frammento:
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
Crea ed esegui la tua pipeline. L'esempio seguente crea ed esegue una pipeline e illustra anche come disattivare l'aggiunta del prefisso ai progetti e rieseguire la pipeline.
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
Allo stesso modo, è possibile attivare la funzionalità per le pipeline esistenti e iniziare una nuova esecuzione che utilizza i prefissi dei processi.
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
Infine, puoi visualizzare il tuo processo con prefisso personalizzato chiamando list_steps sull'esecuzione della pipeline.
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
Personalizzazione dell’accesso alle versioni della pipeline
Puoi concedere un accesso personalizzato a versioni specifiche di Amazon SageMaker Pipelines utilizzando la chiave di sagemaker:PipelineVersionId condizione. Ad esempio, la policy riportata di seguito consente l’accesso per avviare esecuzioni o aggiornare la versione della pipeline solo per la versione con ID 6 e superiore.
Per ulteriori informazioni sulle chiavi di condizione supportate, consulta Condition keys for Amazon SageMaker AI.
Policy di controllo dei servizi con Pipelines
Le policy di controllo dei servizi (SCP) sono un tipo di policy dell'organizzazione che puoi utilizzare per gestire le autorizzazioni nell'organizzazione. Le SCP offrono un controllo centralizzato sulle autorizzazioni massime disponibili per tutti gli account dell'organizzazione. Utilizzando Pipelines all'interno della tua organizzazione, puoi assicurarti che i data scientist gestiscano le esecuzioni della pipeline senza dover interagire con la console. AWS
Se utilizzi un VPC con SCP che limita l'accesso ad Amazon S3, devi eseguire le fasi necessarie per consentire alla pipeline di accedere ad altre risorse Amazon S3.
Per consentire a Pipelines di accedere ad Amazon S3 al di fuori del VPC con la funzione JsonGet, aggiorna la SCP dell’organizzazione per garantire che il ruolo che utilizza Pipelines possa accedere ad Amazon S3. Per farlo, crea un’eccezione per i ruoli utilizzati dall’esecutore di Pipelines tramite il ruolo di esecuzione della pipeline includendo un tag principale e una chiave di condizione.
Per consentire a Pipelines di accedere ad Amazon S3 al di fuori del tuo VPC
-
Crea un tag unico per il tuo ruolo di esecuzione della pipeline seguendo la procedura descritta in Tagging di utenti e ruoli IAM.
-
Concedi un'eccezione nel tuo SCP utilizzando la chiave di condizione
Aws:PrincipalTag IAMper il tag che hai creato. Per ulteriori informazioni, consulta Creazione, aggiornamento ed eliminazione delle policy di controllo del servizio.
