Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Definizione di una pipeline
Per orchestrare i flussi di lavoro con Amazon SageMaker Pipelines, devi generare un grafo aciclico diretto (DAG) sotto forma di definizione di pipeline JSON. Il DAG specifica le diverse fasi coinvolte nel processo di ML, come la pre-elaborazione dei dati, l’addestramento dei modelli, la valutazione del modello e l’implementazione dei modelli, nonché le dipendenze e il flusso di dati tra queste fasi. L’argomento seguente mostra come generare una definizione della pipeline.
Puoi generare la definizione della tua pipeline JSON utilizzando l'SDK SageMaker Python o la funzionalità visiva drag-and-drop Pipeline Designer in Amazon Studio. SageMaker L’immagine seguente è una rappresentazione del DAG della pipeline creato in questo tutorial:
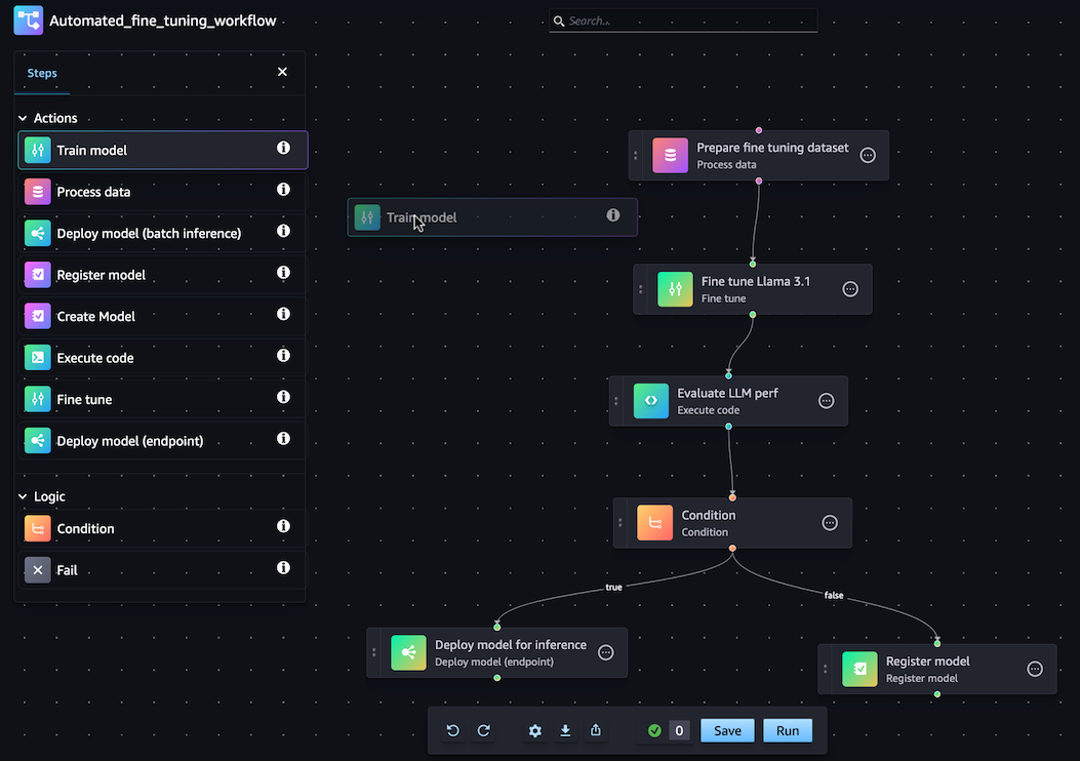
La pipeline definita nelle sezioni seguenti risolve un problema di regressione per determinare l’età di un abalone in base alle sue misurazioni fisiche. Per un notebook Jupyter eseguibile che include il contenuto di questo tutorial, consulta Orchestrating Jobs
Argomenti
La procedura dettagliata seguente illustra le fasi per creare una pipeline barebone utilizzando la funzionalità con trascinamento Pipeline Designer. Se devi mettere in pausa o terminare la sessione di modifica della pipeline nel designer visivo, fai clic sull’opzione Esporta. Questa operazione consente di scaricare la definizione corrente della pipeline nell’ambiente locale. Per riprendere il processo di modifica della pipeline in un secondo momento, puoi importare lo stesso file di definizione JSON nel designer visivo.
Creazione di una fase di elaborazione
Per creare una fase del processo di elaborazione dati, procedi come descritto di seguito:
-
Apri la console Studio seguendo le istruzioni riportate in Avvia Amazon SageMaker Studio.
-
Nel riquadro di navigazione a sinistra, seleziona Pipeline.
-
Scegli Create (Crea).
-
Scegli Vuoto.
-
Nella barra laterale sinistra, scegli Elaborazione di dati e trascinalo sul canvas.
-
Nel canvas, scegli la fase Elaborazione di dati che hai aggiunto.
-
Per aggiungere un set di dati di input, scegli Aggiungi in Dati (input) nella barra laterale destra e seleziona un set di dati.
-
Per aggiungere una posizione in cui salvare i set di dati di output, scegli Aggiungi in Dati (output) nella barra laterale destra e vai alla destinazione.
-
Completa i campi rimanenti nella barra laterale destra. Per informazioni sui campi di queste schede, consulta sagemaker.workflow.steps. ProcessingStep
.
Creazione di una fase di addestramento
Per configurare una fase di addestramento dei modelli, procedi come descritto di seguito:
-
Nella barra laterale sinistra, scegli Addestramento di un modello e trascinalo sul canvas.
-
Nel canvas, scegli la fase Addestramento di un modello che hai aggiunto.
-
Per aggiungere un set di dati di input, scegli Aggiungi in Dati (input) nella barra laterale destra e seleziona un set di dati.
-
Per scegliere una posizione in cui salvare gli artefatti del modello, inserisci un URI Amazon S3 nel campo Posizione (URI S3) oppure scegli Sfoglia S3 per passare alla posizione di destinazione.
-
Completa i campi rimanenti nella barra laterale destra. Per informazioni sui campi di queste schede, consulta sagemaker.workflow.steps. TrainingStep
. -
Fai clic e trascina il cursore dalla fase Elaborazione di dati che hai aggiunto nella sezione precedente alla fase Addestramento di un modello per creare un arco che colleghi le due fasi.
Creazione di un pacchetto di modelli con una fase Registrazione di un modello
Per creare un pacchetto di modelli con una fase di registrazione del modello, procedi come descritto di seguito:
-
Nella barra laterale sinistra, scegli Registrazione di un modello e trascinalo sul canvas.
-
Nel canvas, scegli la fase Registrazione di un modello che hai aggiunto.
-
Per selezionare un modello da registrare, scegli Aggiungi in Modello (input).
-
Scegli Crea un gruppo di modelli per aggiungere il modello a un nuovo gruppo di modelli.
-
Completa i campi rimanenti nella barra laterale destra. Per informazioni sui campi di queste schede, consulta sagemaker.workflow.step_collections. RegisterModel
. -
Fai clic e trascina il cursore dalla fase Addestramento di un modello che hai aggiunto nella sezione precedente alla fase Registrazione di un modello per creare un arco che colleghi le due fasi.
Implementazione del modello su un endpoint con una fase Implementazione di un modello (endpoint)
Per implementare il modello utilizzando una fase di implementazione del modello, procedi come descritto di seguito:
-
Nella barra laterale sinistra, scegli Implementazione di un modello (endpoint) e trascinalo sul canvas.
-
Nel canvas, scegli la fase Implementazione di un modello (endpoint) che hai aggiunto.
-
Per scegliere un modello da implementare, scegli Aggiungi in Modello (input).
-
Scegli il pulsante di opzione Crea endpoint per creare un nuovo endpoint.
-
Immetti un nome e una descrizione per l’endpoint.
-
Fai clic e trascina il cursore dalla fase Registrazione di un modello che hai aggiunto nella sezione precedente alla fase Implementazione di un modello (endpoint) per creare un arco che colleghi le due fasi.
-
Completa i campi rimanenti nella barra laterale destra.
Definizione dei parametri della pipeline
Puoi configurare un set di parametri della pipeline i cui valori possono essere aggiornati per ogni esecuzione. Per definire i parametri della pipeline e impostare i valori predefiniti, fai clic sull’icona a forma di ingranaggio nella parte inferiore del designer visivo.
Salvataggio della pipeline
Dopo aver inserito tutte le informazioni richieste per creare la pipeline, fai clic su Salva nella parte inferiore del designer visivo. In questo modo la pipeline viene convalidata per eventuali errori al runtime e ti viene inviata una notifica. L’operazione Salva non riesce finché non correggi tutti gli errori segnalati dai controlli di convalida automatici. Per riprendere la modifica in un secondo momento, puoi salvare la pipeline in corso come definizione JSON nell’ambiente locale. Puoi esportare la tua pipeline come file di definizione JSON facendo clic sul pulsante Esporta nella parte inferiore del designer visivo. Successivamente, per riprendere l’aggiornamento della pipeline, carica il file di definizione JSON facendo clic sul pulsante Importa.
Prerequisiti
Per eseguire il tutorial seguente, procedi come descritto di seguito:
-
Configura l'istanza del notebook come illustrato in Creare un'istanza del notebook. Ciò conferisce al tuo ruolo le autorizzazioni per leggere e scrivere su Amazon S3 e creare processi di formazione, trasformazione in batch ed elaborazione nell'intelligenza artificiale. SageMaker
-
Concedi al notebook le autorizzazioni per acquisire e svolgere il proprio ruolo, come illustrato in Modifica della policy di autorizzazione di un ruolo. Aggiungi il seguente frammento JSON per collegare questa policy al tuo ruolo. Sostituisci
<your-role-arn>con l'ARN usato per creare l'istanza del notebook. -
Affidati al responsabile del servizio di SageMaker intelligenza artificiale seguendo i passaggi descritti in Modifica di una politica di fiducia dei ruoli. Aggiungi il seguente frammento di dichiarazione alla relazione di attendibilità del tuo ruolo:
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
Configurare l'ambiente
Crea una nuova sessione di SageMaker intelligenza artificiale utilizzando il seguente blocco di codice. Ciò restituisce l'ARN del ruolo per la sessione. Questo ARN del ruolo dovrebbe essere l'ARN del ruolo di esecuzione impostato come prerequisito.
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
Crea una pipeline
Importante
Le politiche IAM personalizzate che consentono ad Amazon SageMaker Studio o Amazon SageMaker Studio Classic di creare SageMaker risorse Amazon devono inoltre concedere le autorizzazioni per aggiungere tag a tali risorse. L’autorizzazione per aggiungere tag alle risorse è necessaria perché Studio e Studio Classic applicano automaticamente tag a tutte le risorse che creano. Se una policy IAM consente a Studio e Studio Classic di creare risorse ma non consente l'etichettatura, possono verificarsi errori AccessDenied "" durante il tentativo di creare risorse. Per ulteriori informazioni, consulta Fornisci le autorizzazioni per etichettare SageMaker le risorse AI.
AWS politiche gestite per Amazon SageMaker AIche danno i permessi per creare SageMaker risorse includono già le autorizzazioni per aggiungere tag durante la creazione di tali risorse.
Esegui i seguenti passaggi dall'istanza del tuo notebook SageMaker AI per creare una pipeline che includa passaggi per:
-
pre-elaborazione
-
addestramento
-
valutazione
-
valutazione condizionale
-
registrazione del modello
Nota
È possibile utilizzare ExecutionVariablesExecutionVariablesviene risolto in fase di esecuzione. Ad esempio, ExecutionVariables.PIPELINE_EXECUTION_ID viene risolto nell'ID dell'esecuzione corrente, che può essere utilizzato come identificatore univoco in diverse esecuzioni.
Fase 1. Scarica il set di dati
Questo notebook utilizza il set di dati Abalone per UCI Machine Learning. Il set di dati contiene le seguenti caratteristiche:
-
length- La misurazione del guscio più lungo dell'abalone. -
diameter- Il diametro dell'abalone perpendicolare alla sua lunghezza. -
height- L'altezza dell'abalone con la carne nel guscio. -
whole_weight- Il peso dell'abalone intero. -
shucked_weight- Il peso della carne estratta dall'abalone. -
viscera_weight- Il peso delle viscere dell'abalone dopo la perdita di sangue. -
shell_weight- Il peso del guscio dell’abalone dopo la rimozione della carne e l'essiccazione. -
sex- Il sesso dell'abalone. Uno tra “M”, “F” o “I”, dove “I” è un abalone neonato. -
rings- Il numero di anelli nel guscio dell’abalone.
Il numero di anelli nel guscio dell’abalone è una buona approssimazione della sua età secondo la formula age=rings + 1.5. Tuttavia, ottenere questo numero è un’operazione che richiede molto tempo. È necessario tagliare il guscio attraverso il cono, colorare la sezione e contare il numero di anelli al microscopio. Tuttavia, le altre misurazioni fisiche sono più facili da determinare. Questo notebook utilizza il set di dati per creare un modello predittivo degli anelli variabili utilizzando le altre misurazioni fisiche.
Per scaricare i set di dati
-
Scarica il set di dati nel bucket Amazon S3 predefinito del tuo account.
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
Scarica un secondo set di dati per la trasformazione in batch dopo la creazione del modello.
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
Fase 2. Definisci i parametri delle pipeline
Questo blocco di codice definisce i seguenti parametri per la pipeline:
-
processing_instance_count- Il numero di istanze del processo di elaborazione. -
input_data- La posizione su Amazon S3 dei dati di input. -
batch_data- La posizione su Amazon S3 dei dati di input per la trasformazione in batch. -
model_approval_status— Lo stato di approvazione per cui registrare il modello addestrato CI/CD. Per ulteriori informazioni, consulta Automazione MLops con progetti SageMaker.
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
Fase 3. Definisci una fase di elaborazione per l’ingegneria delle caratteristiche
Questa sezione mostra come creare una fase di elaborazione per preparare i dati del set di dati per l'addestramento.
Per creare una fase di elaborazione
-
Crea una directory per lo script di elaborazione.
!mkdir -p abalone -
Nella directory
/abalone, crea un file denominatopreprocessing.pycon il contenuto seguente. Questo script di pre-elaborazione viene passato alla fase di elaborazione per l’esecuzione sui dati di input. La fase di addestramento utilizza quindi le funzionalità e le etichette di addestramento pre-elaborate per addestrare un modello. La fase di valutazione utilizza il modello addestrato e le etichette di test pre-elaborate per valutare il modello. Lo script utilizzascikit-learnper effettuare quanto segue:-
Inserire i dati categorici
sexmancanti e codificarli in modo che siano adatti all’addestramento. -
Ridimensionare e normalizzare tutti i campi numerici ad eccezione di
ringsesex. -
Suddividere i dati in set di dati di addestramento, test e convalida.
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
Creare un'istanza di un
SKLearnProcessorda passare alla fase di elaborazione.from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
Creare una fase di elaborazione. Questa fase comprende
SKLearnProcessor, i canali di input e output e lo scriptpreprocessing.pyche hai creato. È molto simile alrunmetodo di un'istanza del processore nell'SDK SageMaker AI Python. Il parametroinput_datapassato aProcessingStepè costituito dai dati di input della fase stessa. Questi dati di input vengono utilizzati dall'istanza del processore durante l'esecuzione.Notate
"traini"validationcanali con"test"nome e specificati nella configurazione di output per il processo di elaborazione. Le fasiPropertiescome queste possono essere utilizzate nelle fasi successive e si risolvono nei rispettivi valori di runtime al runtime.from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
Fase 4. Definisci una fase di addestramento
Questa sezione mostra come utilizzare l'algoritmo SageMaker AI XGBoost per addestrare un modello sull'output dei dati di addestramento delle fasi di elaborazione.
Per definire una fase di addestramento
-
Specifica il percorso del modello in cui desideri salvare i modelli dall'addestramento.
model_path = f"s3://{default_bucket}/AbaloneTrain" -
Configura uno strumento di valutazione per l'algoritmo XGBoost e il set di dati di input. Il tipo di istanza di addestramento viene passato allo strumento di valutazione. Uno script di addestramento tipico:
-
carica i dati dai canali di input
-
configura l’addestramento con iperparametri
-
addestra un modello
-
salva un modello in
model_dircosì che possa essere ospitato in un secondo momento
SageMaker L'intelligenza artificiale carica il modello su Amazon S3 sotto forma di
model.tar.gzun processo di formazione alla fine del processo di formazione.from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
Crea
TrainingSteputilizzando l’istanza dello strumento di stima e le proprietà diProcessingStep. In particolare, passaS3Uridi"train"e il canale di uscita"validation"aTrainingStep.from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
Fase 5. Definisci una fase di elaborazione per la valutazione del modello
Questa sezione mostra come creare una fase di elaborazione per valutare l'accuratezza del modello. Il risultato di questa valutazione del modello viene utilizzato nella fase di condizione per determinare il percorso di esecuzione da seguire.
Per definire una fase di elaborazione per la valutazione del modello
-
Nella directory
/abalone, crea un file denominatoevaluation.py. Questo script viene usato in una fase di elaborazione per eseguire la valutazione del modello. Prende come input un modello addestrato e il set di dati di test, quindi produce un file JSON contenente le metriche di valutazione della classificazione.%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
Crea un'istanza di un
ScriptProcessorche viene utilizzata per creare unProcessingStep.from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
Crea
ProcessingSteputilizzando l’istanza del processore, i canali di input e output e lo scriptevaluation.py. Passa:-
la proprietà
S3ModelArtifactsdalla fase di addestramentostep_train -
S3Uridel canale di output"test"della fase di elaborazionestep_process
È molto simile al
runmetodo di un'istanza del processore nell'SDK SageMaker AI Python.from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
Fase 6: Definizione di una trasformazione in CreateModelStep batch
Importante
Si consiglia di Fase del modello utilizzarlo per creare modelli a partire dalla v2.90.0 di Python SageMaker SDK. CreateModelStepcontinuerà a funzionare nelle versioni precedenti di SageMaker Python SDK, ma non è più supportato attivamente.
Questa sezione mostra come creare un modello di SageMaker intelligenza artificiale a partire dall'output della fase di formazione. Questo modello viene usato per la trasformazione in batch su un nuovo set di dati. Questa fase viene passata alla fase Condizione e viene eseguita solo se tale fase restituisce true.
Per definire una CreateModelStep trasformazione in batch
-
Crea un modello di SageMaker intelligenza artificiale. Passa alla proprietà
S3ModelArtifactssin dalla fase di addestramentostep_train.from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
Definisci l'input del modello per il tuo modello di SageMaker intelligenza artificiale.
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
Crea il tuo
CreateModelSteputilizzando l'CreateModelInputistanza del modello SageMaker AI che hai definito.from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
Fase 7: TransformStep Definire una trasformazione in batch
Questa sezione mostra come creare un TransformStep per eseguire una trasformazione in batch su un set di dati dopo l'addestramento del modello. Questa fase viene passata alla fase Condizione e viene eseguita solo se tale fase restituisce true.
TransformStep Definire una trasformazione in batch
-
Crea un'istanza Transformer con il tipo di istanza di calcolo appropriato, il numero di istanze e l'URI del bucket Amazon S3 di output desiderati. Passa alla proprietà
ModelNamesin dalla fasestep_create_modelCreateModel.from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
Crea un
TransformSteputilizzando l'istanza del transformer che hai definito e il parametro pipelinebatch_data.from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
Fase 8: Definire una RegisterModel fase per creare un pacchetto modello
Importante
Si consiglia di utilizzare Fase del modello per registrare i modelli a partire dalla v2.90.0 di Python SageMaker SDK. RegisterModelcontinuerà a funzionare nelle versioni precedenti di SageMaker Python SDK, ma non è più supportato attivamente.
Questa sezione illustra come creare un’istanza di RegisterModel. Il risultato dell’esecuzione di RegisterModel in una pipeline è un pacchetto di modelli. Un pacchetto di modelli è un'astrazione riutilizzabile di artefatti del modello che racchiude tutti gli ingredienti necessari per l'inferenza. Consiste in una specifica di inferenza che definisce l'immagine di inferenza da usare insieme a una posizione opzionale dei pesi del modello. Un gruppo di pacchetti di modelli è una raccolta di pacchetti di modelli. Puoi utilizzare ModelPackageGroup in Pipelines per aggiungere una nuova versione e un nuovo pacchetto di modelli al gruppo per ogni esecuzione della pipeline. Per ulteriori informazioni sulla registrazione dei modelli, consulta Implementazione della registrazione del modello con il registro dei modelli.
Questa fase viene passata alla fase Condizione e viene eseguita solo se tale fase restituisce true.
Per definire un RegisterModel passaggio per creare un pacchetto modello
-
Costruisci una fase
RegisterModelutilizzando l'istanza dello strumento di valutazione che hai usato per la fase di addestramento. Passa alla proprietàS3ModelArtifactssin dalla fase di addestramentostep_traine specifica unModelPackageGroup. Pipelines creaModelPackageGroupper te.from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
Fase 9. Definisci una fase condizionale per verificare l’accuratezza del modello
ConditionStep consente a Pipelines di supportare l’esecuzione condizionale nel DAG della pipeline in base alla condizione nelle proprietà delle fasi. In questo caso, intendi registrare un pacchetto di modelli solo se l’accuratezza del modello supera il valore richiesto. L’accuratezza del modello è determinata dalla fase di valutazione del modello. Se la precisione supera il valore richiesto, la pipeline crea anche un modello SageMaker AI ed esegue la trasformazione in batch su un set di dati. Questa sezione mostra come definire la fase condizionale.
Per definire una fase condizionale per verificare l'accuratezza del modello
-
Definisci una condizione
ConditionLessThanOrEqualToutilizzando il valore di accuratezza trovato nell'output della fase di elaborazione della valutazione del modello,step_eval. Ottieni questo output utilizzando il file delle proprietà che hai indicizzato nella fase di elaborazione e il rispettivo JSONPath del valore di errore quadratico medio,"mse".from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
Costruisci un
ConditionStep. Passa la condizioneConditionEquals, quindi imposta le fasi di registrazione del pacchetto di modelli e di trasformazione in batch come fasi successive, se la condizione viene soddisfatta.step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
Fase 10: creazione di una pipeline
Ora che hai creato tutte le fasi, combinale in una pipeline.
Come creare una pipeline
-
Definisci quanto segue per la tua pipeline:
name,parametersesteps. I nomi devono essere univoci all'interno di una coppia(account, region).Nota
Un passaggio può apparire solo una volta nell'elenco dei passaggi della pipeline o negli elenchi dei if/else passaggi del passaggio di condizione. Non può apparire in entrambi.
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(Facoltativo) Esamina la definizione della pipeline JSON per assicurarti che sia ben formata.
import json json.loads(pipeline.definition())
Questa definizione della pipeline è pronta per essere inviata all' SageMaker IA. Nel prossimo tutorial, invii questa pipeline all' SageMaker IA e inizi una corsa.
Puoi anche utilizzare boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
Prossima fase: Esecuzione di una pipeline
