Le traduzioni sono generate tramite traduzione automatica. In caso di conflitto tra il contenuto di una traduzione e la versione originale in Inglese, quest'ultima prevarrà.
Ottimizzazione delle prestazioni dei modelli con SageMaker Neo
Neo è una funzionalità di Amazon SageMaker AI che consente ai modelli di machine learning di addestrarsi una sola volta ed essere eseguiti ovunque nel cloud e all'edge.
Se utilizzi SageMaker Neo per la prima volta, ti consigliamo di consultare la sezione Guida introduttiva ai dispositivi Edge per ottenere istruzioni dettagliate su come compilare e distribuire su un dispositivo edge.
Che cos'è Neo? SageMaker
In genere, è difficile ottimizzare i modelli di machine learning per inferenza su più piattaforme perché occorre calibrare manualmente i modelli per la configurazione hardware e software specifica di ciascuna piattaforma. Per ottenere prestazioni ottimali per un determinato carico di lavoro, è necessario conoscere, tra gli altri, l'architettura hardware, il set di istruzioni, i modelli di accesso alla memoria e le forme dei dati di input. Per lo sviluppo software tradizionale, strumenti quali compilatori e profiler semplificano il processo. Per il machine learning, la maggior parte degli strumenti sono specifici per il framework o l'hardware. Ciò costringe l'utente a un processo basato su tentativi ed errori manuale che è inaffidabile e non produttivo.
Neo ottimizza automaticamente i modelli Gluon, Keras, MXNet, PyTorch TensorFlow TensorFlow-Lite, e ONNX per l'inferenza su macchine Android, Linux e Windows basate su processori di Ambarella, ARM, Intel, Nvidia, NXP, Qualcomm, Texas Instruments e Xilinx. Neo è testato con modelli di visione artificiale disponibili negli zoo modello di tutti i framework. SageMaker Neo supporta la compilazione e l'implementazione per due piattaforme principali: istanze cloud (inclusa Inferentia) e dispositivi edge.
Per ulteriori informazioni sui framework supportati e sui tipi di istanze cloud su cui è possibile eseguire la distribuzione, consulta Tipi di istanze e framework supportati per le istanze cloud.
Per ulteriori informazioni sui framework supportati, i dispositivi edge, i sistemi operativi, le architetture di chip e i comuni modelli di machine learning testati da SageMaker AI Neo per i dispositivi edge, consulta per i dispositivi edge. Framework, dispositivi, sistemi e architetture supportati
Come funziona
Neo è costituito da un compilatore e un runtime. Innanzitutto, l'API di compilazione Neo legge modelli esportati da vari framework. Converte le funzioni e le operazioni specifiche del framework in una rappresentazione intermedia indipendente dal framework. Inoltre, esegue una serie di ottimizzazioni. Quindi genera codice binario per le operazioni ottimizzate, le scrive in una libreria di oggetti condivisi e salva la definizione del modello e i parametri in file separati. Neo fornisce, inoltre, un runtime per ogni piattaforma di destinazione che carica ed esegue il modello compilato.
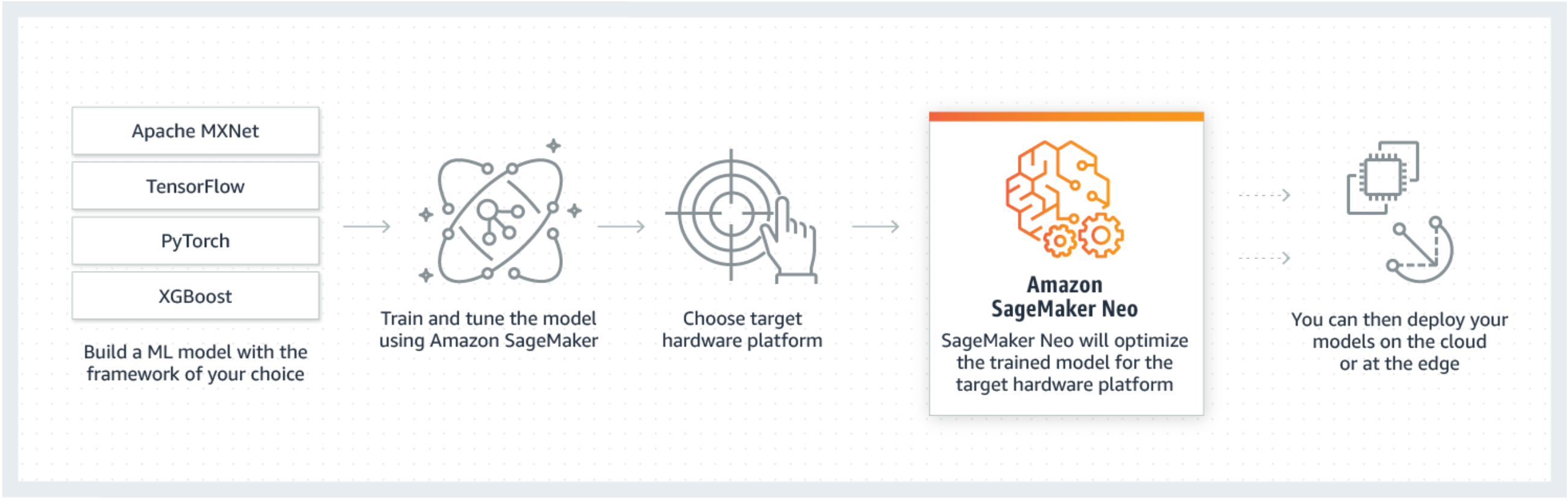
Puoi creare un lavoro di compilazione Neo dalla console SageMaker AI, da AWS Command Line Interface (AWS CLI), da un taccuino Python o SageMaker dalle informazioni SDK.For AI su come compilare un modello, vedi. Compilazione di modelli con Neo Con pochi comandi dell'interfaccia a riga di comando, una chiamata API o pochi clic puoi convertire un modello per la piattaforma scelta. Puoi implementare rapidamente il modello su un endpoint SageMaker AI o su un dispositivo. AWS IoT Greengrass
Neo può ottimizzare i modelli con parametri in FP32 o quantizzati a INT8 o con larghezza FP a 16 bit.
