Les traductions sont fournies par des outils de traduction automatique. En cas de conflit entre le contenu d'une traduction et celui de la version originale en anglais, la version anglaise prévaudra.
Fine-tune modèles de fondation
Les modèles de base auxquels vous pouvez accéder via Amazon SageMaker Canvas peuvent vous aider à effectuer toute une série de tâches générales. Toutefois, si vous avez un cas d’utilisation spécifique et que vous souhaitez personnaliser les réponses en fonction de vos propres données, vous pouvez optimiser un modèle de fondation.
Pour optimiser un modèle de fondation, vous fournissez un jeu de données composé d’exemples d’invites et de réponses du modèle. Ensuite, vous entraînez le modèle de fondation sur ces données. Enfin, le modèle de fondation optimisé est en mesure de vous apporter des réponses plus spécifiques.
La liste suivante contient les modèles de fondation que vous pouvez optimiser dans Canvas :
Titan Express
Falcon-7B
Falcon-7B-Instruct
Falcon-40B-Instruct
Falcon-40B
Flan-T5-Large
Flan-T5-Xl
Flan-T5-Xxl
MPT-7B
MPT-7B-Instruct
Vous pouvez accéder à des informations plus détaillées sur chaque modèle de fondation dans l’application Canvas tout en optimisant un modèle. Pour de plus amples informations, veuillez consulter Fine-tune le modèle.
Cette rubrique décrit comment optimiser les modèles de fondation dans Canvas.
Avant de commencer
Avant de peaufiner un modèle de base, assurez-vous que vous disposez des autorisations nécessaires pour les Ready-to-use modèles dans Canvas et d'un rôle d' Gestion des identités et des accès AWS exécution qui entretient une relation de confiance avec Amazon Bedrock, ce qui permet à Amazon Bedrock d'assumer votre rôle tout en peaufinant les modèles de base.
Lorsque vous configurez ou modifiez votre domaine Amazon SageMaker AI, vous devez 1) activer les autorisations de configuration des Ready-to-use modèles Canvas et 2) créer ou spécifier un rôle Amazon Bedrock, qui est un rôle d'exécution IAM auquel SageMaker AI attache une relation de confiance avec Amazon Bedrock. Pour plus d’informations sur la configuration de ces paramètres, consultez Conditions préalables à la configuration d'Amazon Canvas SageMaker.
Vous pouvez configurer le rôle Amazon Bedrock manuellement si vous préférez utiliser votre propre rôle d'exécution IAM (au lieu de laisser l' SageMaker IA en créer un en votre nom). Pour plus d’informations sur la configuration de la relation d’approbation entre votre propre rôle d’exécution IAM et Amazon Bedrock, consultez Octroi d’autorisations aux utilisateurs pour utiliser Amazon Bedrock et les fonctionnalités d’IA générative dans Canvas.
Vous devez également disposer d’un jeu de données formaté pour optimiser les grands modèles de langage (LLM). Voici une liste des exigences relatives à votre jeu de données :
-
Le jeu de données doit être tabulaire et contenir au moins deux colonnes de données textuelles : une colonne d’entrée (contenant des exemples d’invites pour le modèle) et une colonne de sortie (contenant des exemples de réponses du modèle).
Voici un exemple :
Input Output Quelles sont vos conditions de livraison ?
Nous offrons une livraison gratuite pour toutes les commandes de plus de 50 $. Les commandes de moins de 50 $ font l’objet de frais d’expédition de 5,99 $.
Comment puis-je retourner un article ?
Pour retourner un article, accédez à notre centre de retours et suivez les instructions. Vous devez fournir votre numéro de commande et le motif du retour.
Je rencontre des problèmes avec mon produit. Que puis-je faire ?
Veuillez contacter notre service clientèle et nous serons heureux de vous aider à résoudre ces problèmes.
-
Nous recommandons que le jeu de données comporte au moins 100 paires de texte (lignes d’éléments d’entrée et de sortie correspondants). Cela garantit que le modèle de fondation dispose de suffisamment de données pour le peaufinage et augmente l’exactitude de ses réponses.
-
Chaque élément d’entrée et de sortie doit contenir un maximum de 512 caractères. Tout texte plus long est réduit à 512 caractères lors du peaufinage du modèle de fondation.
Lors du peaufinage d’un modèle Amazon Bedrock, vous devez respecter les quotas Amazon Bedrock. Pour plus d’informations, consultez Quotas de personnalisation des modèles dans le Guide de l’utilisateur Amazon Bedrock.
Pour plus d’informations sur les exigences et limitations générales des jeux de données dans Canvas, consultez Création d’un jeu de données.
Fine-tune un modèle de base
Vous pouvez optimiser un modèle de fondation en utilisant l’une des méthodes suivantes dans l’application Canvas :
-
Lors d'une discussion sur la génération, l'extraction et la synthèse de contenu avec un modèle de base, choisissez l'icône du Fine-tune modèle (
 ).
). -
Lors d'une discussion avec un modèle de base, si vous avez régénéré la réponse deux fois ou plus, Canvas vous offre la possibilité de Fine-tune modéliser. La capture d’écran suivante montre à quoi cela ressemble.

-
Sur la page Mes modèles, vous pouvez créer un nouveau modèle en choisissant Nouveau modèle, puis en sélectionnant le modèle de Fine-tune base.
-
Sur la page d'accueil des Ready-to-use modèles, vous pouvez choisir Créer votre propre modèle, puis dans la boîte de dialogue Créer un nouveau modèle, choisir le modèle de Fine-tune base.
-
Lorsque vous parcourez vos jeux de données dans l’onglet Data Wrangler, vous pouvez sélectionner un jeu de données et choisir Créer un modèle. Ensuite, choisissez le modèle de Fine-tune fondation.
Après avoir commencé à optimiser un modèle, procédez comme suit :
Sélection d’un jeu de données
Dans l’onglet Sélectionner du peaufinage d’un modèle, vous choisissez les données sur lesquelles vous souhaitez entraîner le modèle de fondation.
Sélectionnez un jeu de données existant ou créez un nouveau jeu de données répondant aux exigences répertoriées dans la section Avant de commencer. Pour plus d’informations sur la manière de créer un jeu de données, consultez Création d’un jeu de données.
Lorsque vous avez sélectionné ou créé un jeu de données et que vous êtes prêt à continuer, choisissez Sélectionner le jeu de données.
Fine-tune le modèle
Après avoir sélectionné vos données, vous êtes maintenant prêt à commencer l’entraînement et le peaufinage du modèle.
Fine-tuneDans l'onglet, effectuez les opérations suivantes :
(Facultatif) Choisissez En savoir plus sur nos modèles de fondation pour accéder à plus d’informations sur chaque modèle et mieux choisir le ou les modèles de fondation à déployer.
Pour sélectionner jusqu'à 3 modèles de base, ouvrez le menu déroulant et consultez jusqu'à 3 modèles de base (jusqu'à 2 JumpStart modèles et 1 modèle Amazon Bedrock) que vous souhaitez peaufiner pendant le stage de formation. En optimisant plusieurs modèles de fondation, vous pouvez comparer leurs performances et finalement choisir celui qui convient le mieux à votre cas d’utilisation comme modèle par défaut. Pour plus d’informations sur les modèles par défaut, consultez Visualisation des modèles candidats dans le classement des modèles.
Pour Sélectionner la colonne d’entrée, sélectionnez la colonne de données textuelles de votre jeu de données contenant les exemples d’invites du modèle.
Pour Sélectionner la colonne de sortie, sélectionnez la colonne de données textuelles de votre jeu de données contenant les exemples de réponses du modèle.
-
(Facultatif) Pour configurer les paramètres avancés de la tâche d’entraînement, choisissez Configurer le modèle. Pour plus d’informations sur les paramètres avancés de génération de modèle, consultez Configurations avancées de génération de modèle.
Dans la fenêtre contextuelle Configurer le modèle, procédez comme suit :
Pour Hyperparamètres, vous pouvez ajuster le nombre d’époques, la taille du lot, le taux d’apprentissage et les étapes d’échauffement du taux d’apprentissage pour chaque modèle sélectionné. Pour plus d'informations sur ces paramètres, consultez la section Hyperparamètres de la JumpStart documentation.
Pour Partage des données, vous pouvez spécifier des pourcentages pour répartir vos données entre le jeu d’entraînement et le jeu de validation.
Pour Durée d’exécution de tâche maximale, vous pouvez définir la durée maximale pendant laquelle Canvas exécute la tâche de génération. Cette fonctionnalité n'est disponible que pour les modèles de JumpStart base.
Après avoir configuré ces paramètres, choisissez Enregistrer.
Choisissez Fine-tunede commencer à entraîner les modèles de base que vous avez sélectionnés.
Une fois que la tâche de peaufinage a commencé, vous pouvez quitter la page. Lorsque le modèle apparaît comme Prêt sur la page Mes modèles, il est prêt à être utilisé et vous pouvez alors analyser les performances de votre modèle de fondation optimisé.
Analyse du modèle de fondation optimisé
Dans l’onglet Analyser de votre modèle de fondation optimisé, vous pouvez voir les performances du modèle.
L’onglet Vue d’ensemble de cette page affiche les scores de perplexité et de perte, ainsi que les analyses permettant de visualiser l’amélioration du modèle au fil du temps pendant l’entraînement. La capture d’écran suivante présente l’onglet Vue d’ensemble.

Sur cette page, vous pouvez voir les visualisations suivantes :
La courbe de perplexité mesure la précision de la prédiction par le modèle du mot suivant d’une séquence ou le niveau grammatical de la sortie du modèle. Dans l’idéal, à mesure que le modèle s’améliore pendant l’entraînement, le score diminue et entraîne une courbe qui s’abaisse et s’aplatit au fil du temps.
La courbe de perte quantifie la différence entre la sortie correcte et la sortie prédite du modèle. Une courbe de perte qui diminue et s’aplatit au fil du temps indique que le modèle améliore sa capacité à réaliser des prédictions précises.
L’onglet Métriques avancées vous montre les hyperparamètres et les métriques supplémentaires pour votre modèle. Cela ressemble à la capture d’écran suivante :
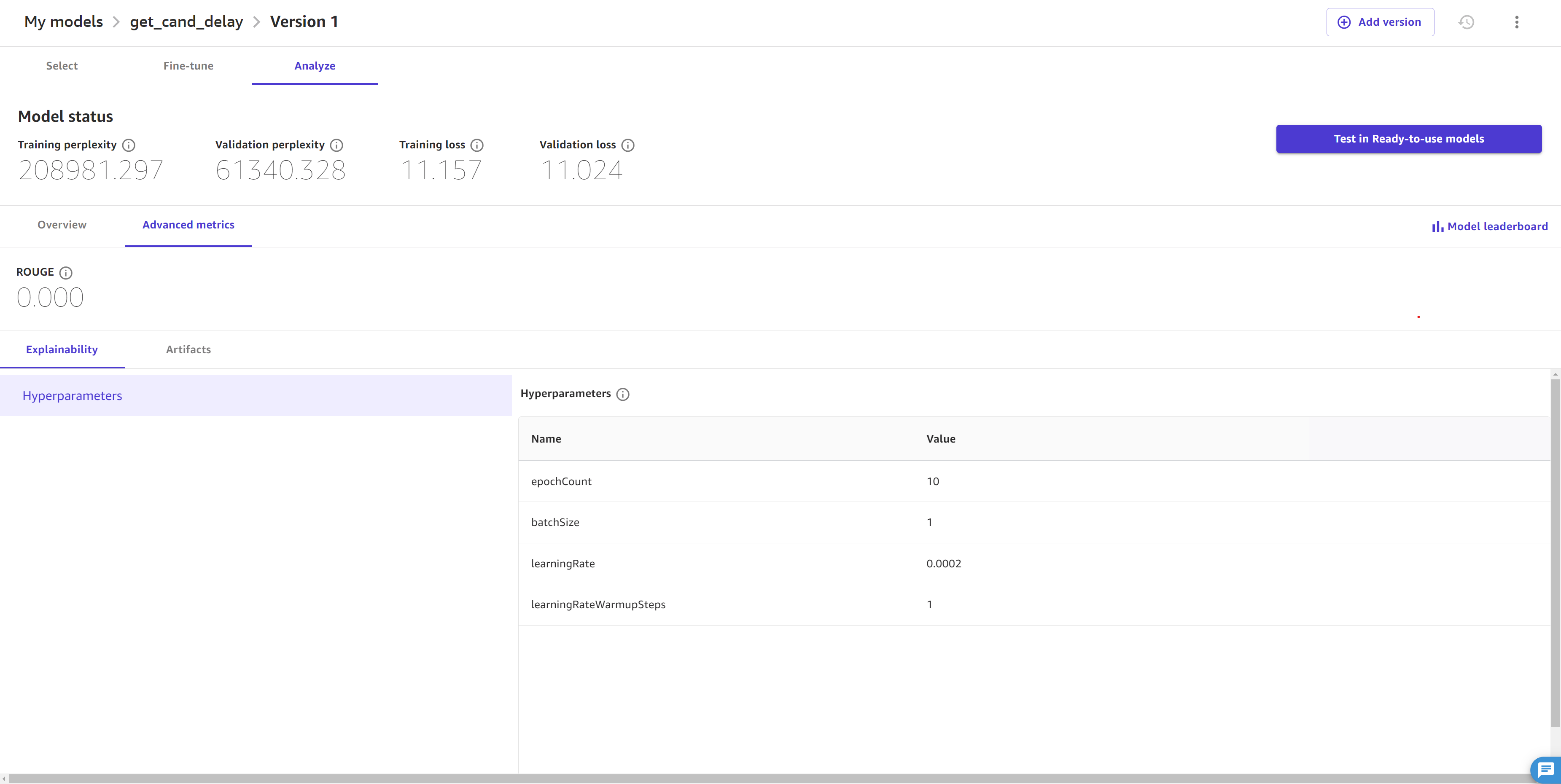
L’onglet Métriques avancées contient les informations suivantes :
-
La section Explicabilité contient les hyperparamètres, qui sont les valeurs définies avant le travail pour guider le peaufinage du modèle. Si vous n’avez pas spécifié d’hyperparamètres personnalisés dans les paramètres avancés du modèle dans la section Fine-tune le modèle, Canvas sélectionne les hyperparamètres par défaut pour vous.
Pour les JumpStart modèles, vous pouvez également consulter la métrique avancée ROUGE (Recall-Oriented Understudy for Gisting Evaluation)
, qui évalue la qualité des résumés générés par le modèle. Elle mesure la précision avec laquelle le modèle peut résumer les principaux points d’un passage. La section Artefacts vous fournit des liens vers les artefacts générés au cours de la tâche de peaufinage. Vous pouvez accéder aux données d’entraînement et de validation enregistrées dans Amazon S3, ainsi qu’au lien vers le rapport d’évaluation des modèles (pour en savoir plus, consultez le paragraphe suivant).
Pour obtenir davantage d'informations sur l'évaluation des modèles, vous pouvez télécharger un rapport généré à l'aide de SageMaker Clarify, une fonctionnalité qui peut vous aider à détecter les biais dans votre modèle et vos données. Commencez par générer ce rapport en choisissant Générer un rapport d’évaluation au bas de la page. Une fois le rapport généré, vous pouvez télécharger le rapport complet en choisissant Télécharger le rapport ou en retournant à la section Artefacts.
Vous pouvez également accéder à un bloc-notes Jupyter qui vous montre comment répliquer votre tâche de peaufinage dans du code Python. Vous pouvez l’utiliser pour répliquer ou apporter des modifications programmatiques à votre tâche de peaufinage ou pour mieux comprendre comment Canvas optimise votre modèle. Pour en savoir plus sur les blocs-notes de modèle et sur la façon d’y accéder, consultez Téléchargement d’un modèle de bloc-notes.
Pour plus d’informations sur la façon d’interpréter les informations contenues dans l’onglet Analyser de votre modèle de fondation optimisé, consultez la rubrique Évaluation de modèle.
Après avoir analysé les onglets Vue d’ensemble et Métriques avancées, vous pouvez également choisir d’ouvrir le classement des modèles, qui affiche la liste des modèles de base entraînés pendant la génération. Le modèle présentant le score de perte le plus bas est considéré comme le modèle le plus performant et est sélectionné comme modèle par défaut, c’est-à-dire le modèle dont vous pouvez voir l’analyse dans l’onglet Analyser. Vous pouvez uniquement tester et déployer le modèle par défaut. Pour plus d’informations sur le classement des modèles et sur la façon de modifier le modèle par défaut, consultez Visualisation des modèles candidats dans le classement des modèles.
Test d’un modèle de fondation optimisé dans une discussion
Après avoir analysé les performances d’un modèle de fondation optimisé, vous souhaiterez peut-être le tester ou comparer ses réponses avec le modèle de base. Vous pouvez tester un modèle de fondation optimisé dans une discussion grâce à la fonctionnalité Générer, extraire et résumer du contenu.
Démarrez une discussion avec un modèle peaufiné en choisissant l’une des méthodes suivantes :
Dans l'onglet Analyser du modèle affiné, choisissez Tester dans les modèles de Ready-to-use base.
Sur la page Ready-to-use Modèles Canvas, choisissez Générer, extraire et résumer le contenu. Choisissez ensuite Nouvelle discussion et sélectionnez la version du modèle que vous souhaitez tester.
Le modèle démarre dans une discussion et vous pouvez interagir avec lui comme avec n’importe quel autre modèle de fondation. Vous pouvez ajouter d’autres modèles à la discussion et comparer leurs sorties. Pour plus d’informations sur les fonctionnalités des discussions, consultez Modèles de base de l'IA générative dans SageMaker Canvas.
Opérationnalisation des modèles de fondation optimisés
Après avoir optimisé votre modèle dans Canvas, vous pouvez effectuer les opérations suivantes :
Enregistrez le modèle dans le registre des SageMaker modèles pour l'intégrer dans les processus MLOPS de votre organisation. Pour de plus amples informations, veuillez consulter Enregistrer une version de modèle dans le registre des modèles d' SageMaker IA.
Déployez le modèle sur un point de terminaison d' SageMaker IA et envoyez des demandes au modèle depuis votre application ou votre site Web pour obtenir des prédictions (ou des inférences). Pour de plus amples informations, veuillez consulter Déploiement de vos modèles sur un point de terminaison.
Important
Vous ne pouvez enregistrer et déployer que des modèles de JumpStart base affinés, et non des modèles basés sur Amazon Bedrock.
